是spark中一些特殊的算子操作会触发的一种操作 shuffle操作,会导致大量的数据在不同的机器和节点之间进行传输,因此也是spark中最复杂、最消耗性能的一种操作
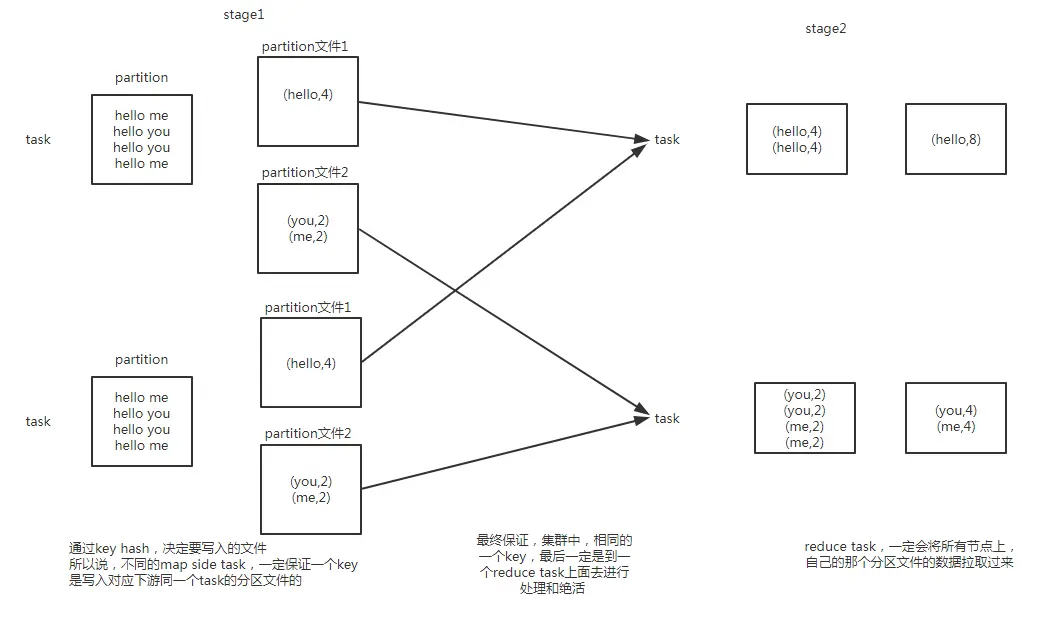
我们可以通过reduceByKey操作作为一个例子,来理解shuffle操作 先看图
shuffle操作原理.png
reduceByKey算子会将上一个RDD中的每个key对应的所有value都聚合成一个value,然后生成一个新的RDD 新的RDD的元素类型就是对的格式,每个key对应一个聚合起来的value 这里最大的问题就在于,对于上一个RDD来说,并不是一个key对应的所有value都是在一个partition中的,也更不太可能说key的所有value都在一台机器上 所以对于这种情况来说,就必须在整个集群中,将各个节点上,同一个key对应的values,统一传输到一个节点上来聚合处理 这个过程中就会发生大量的网络数据的传输
在进行一个key对应的values的聚合时 首先,上一个stage的每个map task就必须保证将自己处理的当前分区中的数据,相同的key写入一个分区文件中,可能会写多个不同的分区文件 接着下一个stage的reduce task就必须从上一个stage所有task所在的机器上,将各个task写入的多个分区文件中,找到属于自己的那个分区文件 接着将属于自己的分区数据,拉取过来,这样就可以保证每个key对应的所有values都汇聚到一个节点上去处理和聚合 这个过程就称之为shuffle
shuffle是分为shuffle write和shuffle read两个部分的,是在两个不同的stage中进行的
默认情况下,shuffle操作是不会对每个分区中的数据进行排序的
如果想要对每个分区中的数据进行排序,那么可以使用以下三种方法:
上述三种方法中,相对来说,mapPartitions的代价比较小,因为不需要进行额外的shuffle操作 repartitionAndSortWithinPartitions和sortByKey可能会进行额外的shuffle操作的,因此性能并不是很高
val rdd2 = rdd1.reduceByKey(_ + _) rdd2.mapPartitions(tuples.sort) rdd2.repartitionAndSortWithinPartitions(),重分区,重分区的过程中,就进行分区内的key的排序,重分区的原理和repartition一样 rdd2.sortByKey,直接对rdd按照key进行全局性的排序
spark中会导致shuffle操作的有以下几种算子
重分区: 一般会shuffle,因为需要在整个集群中,对之前所有的分区的数据进行随机,均匀的打乱,然后把数据放入下游新的指定数量的分区内 byKey类的操作:因为你要对一个key,进行聚合操作,那么肯定要保证集群中,所有节点上的,相同的key,一定是到同一个节点上进行处理 join类的操作:两个rdd进行join,就必须将相同join key的数据,shuffle到同一个节点上,然后进行相同key的两个rdd数据的笛卡尔乘积
所以对于上述的操作 首先第一原则,就是,能不用shuffle操作,就尽量不用shuffle操作,尽量使用不shuffle的操作 第二原则,就是,如果使用了shuffle操作,那么肯定要进行shuffle的调优,甚至是解决碰到的数据倾斜的问题
shuffle操作是spark中唯一最最消耗性能的地方 因此也就成了最需要进行性能调优的地方,最需要解决线上报错的地方,也是唯一可能出现数据倾斜的地方 因为shuffle过程中,会产生大量的磁盘IO、数据序列化和反序列化、网络IO
为了实施shuffle操作 spark中才有了stage的概念,在发生shuffle操作的算子中,进行stage的拆分 shuffle操作的前半部分,是上一个stage来进行,也称之为map task,shuffle操作的后半部分,是下一个stage来进行,也称之为reduce task 其中map task负责数据的组织,也就是将同一个key对应的value都写入同一个下游task对应的分区文件中 其中reduce task负责数据的聚合,也就是将上一个stage的task所在节点上,将属于自己的各个分区文件,都拉取过来聚合 这种模型,是参考和模拟了MapReduce的shuffle过程来的
map task会将数据先保存在内存中,如果内存不够时,就溢写到磁盘文件中去 reduce task会读取各个节点上属于自己的分区磁盘文件,到自己节点的内存中,并进行聚合
shuffle操作会消耗大量的内存,因为无论是网络传输数据之前,还是之后,都会使用大量的内存中数据结构来实施聚合操作 比如reduceByKey和aggregateByKey操作,会在map side使用内存中的数据结构进行预先聚合 其他的byKey类的操作,都是在reduce side,使用内存数据结构进行聚合 在聚合过程中,如果内存不够,只能溢写到磁盘文件中去,此时就会发生大量的磁盘IO,降低性能
此外,shuffle过程中,还会产生大量的中间文件,也就是map side写入的大量分区文件 比如Spark 1.3版本,这些中间文件会一致保留着,直到RDD不再被使用,而且被垃圾回收掉了,才会去清理中间文件 这主要是为了,如果要重新计算shuffle后的RDD,那么map side不需要重新做一次磁盘写操作 但是这种情况下,如果我们的应用程序中,一直保持着对RDD的引用,导致很长时间以后才会进行RDD垃圾回收操作 保存中间文件的目录,由spark.local.dir属性指定
内存的消耗、磁盘IO、网络数据传输(IO)
我们可以通过对一系列的参数进行调优,来优化shuffle的性能 spark 1.5.2版本








 京公网安备 11010802041100号
京公网安备 11010802041100号