作者:良心無悔1314_878 | 来源:互联网 | 2023-08-15 15:47
文章目录一、Multi-HeadAttention(多头)1.1Single-HeadSelf-Attention(单头Self-Attention)1.2Multi-HeadSe
文章目录
- 一、Multi-Head Attention(多头)
- 1.1 Single-Head Self-Attention(单头Self-Attention)
- 1.2 Multi-Head Self-Attention(多头Self-Attention)
- 1.3 Multi-Head Attention(多头Attention)
- 二、Stacked Self-Attention Layers(堆叠)
- 2.1 Self-Attention Layer+Dense Layer
- 2.2 Stacked Self-Attention Layers
- 2.3 Transformer's Encoder
- 三、Stacked Attention Layers
- 3.1 Stacked Attentions
- 3.2 Transformer's Decoder
- 四、Transformer
- 五、Summary(总结)
- 5.1 From Single-Head to Multi-Head
- 5.2 Encoder Network of Transformer
- 5.3 Decoder Network of Transformer
- 5.4 Transformer Model
一、Multi-Head Attention(多头)
1.1 Single-Head Self-Attention(单头Self-Attention)
输入为一个序列(X1 ,X2 ,X3 ,···,Xm),Self-Attention层有三个参数矩阵(WQ ,WK ,WV),输出是一个序列(C:1 ,C:2 ,C:3 ,···,C:m)
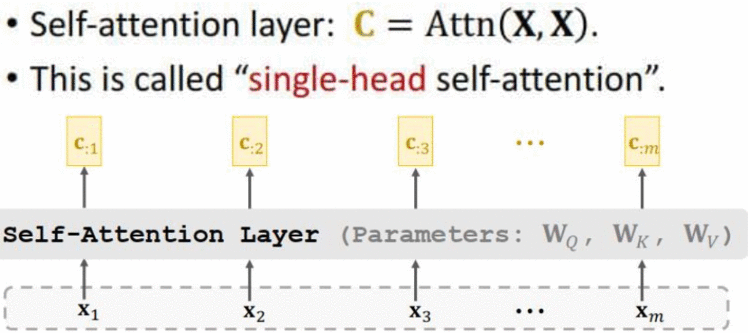
1.2 Multi-Head Self-Attention(多头Self-Attention)
- Using L single-head self-attentions (which do not share parameters.) (多头Self-Attention是由L个单头的Self-Attention组成的,它们各自有各自的参数,不共享参数)
- A single-head self-attention has 3 parameter matrices: WQ ,WK ,WV 。(每个单头self-attention有三个参数矩阵)
- Totally 3L parameters matrices.(因此的,多头self-attention共有3L个参数矩阵)
所有单头Self-Attention都有相同的输入,但是它们的参数矩阵各不相同,所以输出的C序列也各不相同,把 L个单头Self-Attention输出的序列做合并堆叠起来,作为多头Self-Attention的最终输出,堆叠起来的C向量变得更高。
- Suppose single-head self-attentions’ outputs are dxm matrices. (如果每个单头的输出都是d×m的矩阵)
- Multi-head’s output shape: (Ld) xm. (多头的输出是 (Ld)×m )

1.3 Multi-Head Attention(多头Attention)
-
Using L single-head attentions (which do not share parameters.) (多头Self-Attention是由L个单头的Self-Attention组成的,它们各自有各自的参数,不共享参数)
-
Concatenating single-head attentions’ outputs. (合并堆叠单头attention的输出)
-
输入为两个序列(X1 ,X2 ,X3 ,···,Xm),(X‘1 ,X’2 ,X‘3 ,···,Xt)
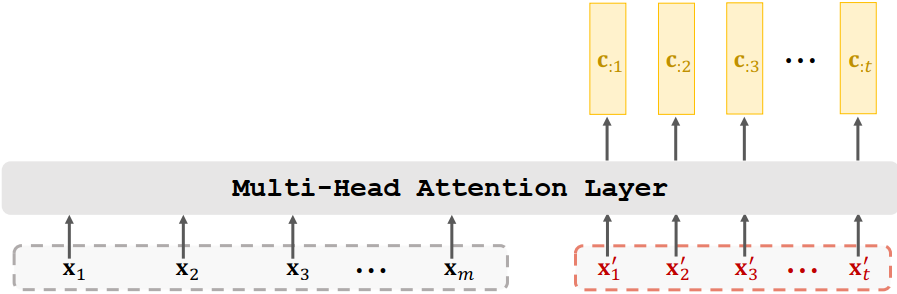
二、Stacked Self-Attention Layers(堆叠)
多头Self-Attention和全连接层搭建一个encoder网络
2.1 Self-Attention Layer+Dense Layer
- 这几个全连接层是相同的,参数矩阵都是Wu
- 搭建的是两层。
- U:i 向量不仅仅依赖于Xi ,U:i 向量依赖于所有m个Xi 向量。改变任何Xi 向量,U:i 向量都会发生变化,对U:i 向量影响最大的还是Xi 向量。

2.2 Stacked Self-Attention Layers

2.3 Transformer’s Encoder
- 一个block有两层,一个是self-attention层和全连接层。
- 输入是512×m的矩阵,输出也是512×m的矩阵
- m是输入序列X的长度,每个X向量都是512维的
- Transformer的encoder网络一共有6个blocks,每个block有两层,每个block都有自己的参数,block之间不共享参数
- 最终的输出是512×m的矩阵,输出与输入的大小是一样的

三、Stacked Attention Layers
3.1 Stacked Attentions
- Transformer is a Seq2Seq model (encoder + decoder).
- Encoder’s inputs are vectors X1 ,X2 ,X3 ,···,Xm 。
- Decoder’s inputs are vectors X‘1 ,X‘2 ,X’3 ,···,X‘t 。
- Transformer’s encoder contains 6 stacked blocks。(Transformer的encoder包含6个blocks)
- 1 block 1 multi-head attention layer + 1 dense layer.(1个block包含两层)

3.2 Transformer’s Decoder
四、Transformer

五、Summary(总结)
5.1 From Single-Head to Multi-Head
- Single-head self-attention can be combined to form a multi-head self-attention.
- Single-head attention can be combined to form a multi-head attention.

5.2 Encoder Network of Transformer
- 1 encoder block ≈ multi-head self-attention + dense.
- Input shape: 512xm.
- Output shape: 512xm.
- Encoder network is a stack of 6 such blocks.(这些blocks之间不共享参数)
5.3 Decoder Network of Transformer
- 1 decoder block ≈ multi-head self-attention + multi-head attention + dense.
- Input shape: ( 512 x m,512 x t ).
- Output shape:512 x t ;
- Decoder network is a stack of 6 such blocks.(这些blocks之间不共享参数)
5.4 Transformer Model
- Transformer is Seq2Seq model; it has an encoder and a decoder.(Transformer是Seq2Seq模型,它有encoder和decoder网络,可以用来做机器翻译)
- Transformer model is not RNN.(Transformer不是RNN,它没有循环结构)
- Transformer is based on attention and self-attention 。 (Transformer完全基于attention和全连接层,Transformer和RNN的输入输出大小完全一样)
- Transformer outperforms all the state-of-the-art RNN models. (Transformer用在自然语言处理问题上效果非常好,可以完爆最好的RNN+attention,因此Transformer现在已经是业界标准)







 京公网安备 11010802041100号
京公网安备 11010802041100号