点击上方“AI公园”,关注公众号,选择加“星标“或“置顶”
作者:PRANAV DAR
编译:ronghuaiyang
导读 对于希望学习算法或尝试现有框架的人来说,预训练的模型是一个很好的帮助。由于时间限制或计算资源的限制,不可能总是从头构建模型,这就是为什么存在预训练模型!
介绍 对于希望学习算法或尝试现有框架的人来说,预训练的模型是一个很好的帮助。由于时间限制或计算资源的限制,不可能总是从头构建模型,这就是为什么存在预训练模型!你可以使用预训练的模型作为基准来改进现有的模型,或者用它来测试对比你自己的模型。这个的潜力和可能性是巨大的。
在本文中,我们将研究在Keras中具有计算机视觉应用的各种预训练模型。为什么Keras ?首先,因为我相信这是一个很好的开始学习神经网络的库。其次,我希望在本文中始终使用一个框架。这将帮助你从一个模型转移到下一个模型,而不必担心框架。
我鼓励你在自己的机器上尝试每个模型,了解它是如何工作的,以及如何改进或调整内部参数。
我们已经把这个话题分成了一系列文章。第二部分将重点介绍自然语言处理(NLP),第三部分将介绍音频和语音模型。我们的目标是让你在这些领域中启动和运行现有的解决方案,这些解决方案将快速跟踪你的学习过程。
目标检测 目标检测是计算机视觉领域中最常见的应用之一。它在各行各业都有应用,从自动驾驶汽车到计算人群中的人数。本节讨论可用于检测对象的预训练模型。你也可以阅读下面的文章来熟悉这个主题:
Mask R-CNN https://github.com/matterport/Mask_RCNN
Mask R-CNN是一种灵活的对象实例分割框架。这个预训练模型是基于Python和Keras上的Mask R-CNN技术的实现。它为给定图像中的每个对象实例生成边界框和分割掩码(如上图所示)。
这个GitHub库提供了大量的资源,可以帮助你入门。它包括Mask R-CNN的源代码、MS COCO的训练代码和预训练权重、可以通过Jupyter notebooks 来对pipeline的每一步以及其他内容进行可视化。
YOLOv2 https://github.com/experiencor/keras-yolo2
YOLO是一个非常流行的深度学习对象检测框架。这个库包含Keras中YOLOv2的实现。开发人员在袋鼠检测、自动驾驶汽车、红细胞检测等各种目标图像上测试了该框架,并发布了浣熊检测的预训练模型。
你可以在这里下载浣熊数据集 ( https://github.com/experiencor/raccoon_dataset ),现在就开始使用这个预训练的模型!数据集包含200张图像(160-training, 40-validation)。你可以在这里下载整个模型的预训练权重。根据开发人员的说法,这些权重可以用于一个类的对象检测器。
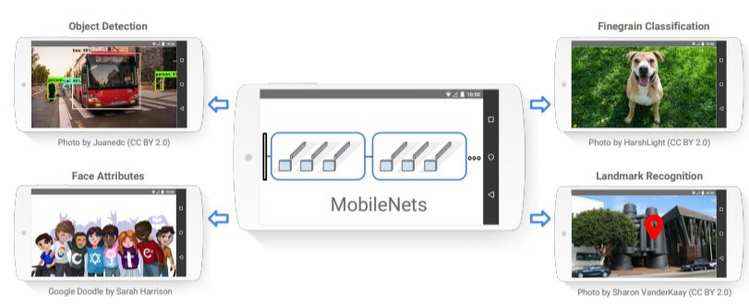
MobileNet https://keras.io/applications/#mobilenet
顾名思义,MobileNet是为移动设备设计的架构。它是由谷歌建造的。我们在上面已经链接了这个特殊的模型,它在流行的ImageNet数据库(它是一个包含数百万张属于20,000多个类的图像的数据库)上提供了预训练的权重。
正如你上面所看到的,MobileNet的应用不仅仅局限于对象检测,它还跨越了各种计算机视觉任务,如人脸属性、地标识别、细粒度分类等。
成熟/生番茄分类 https://github.com/fyrestorm-sdb/tomatoes
如果给你几百张西红柿的图片,你会怎么分类——有缺陷的/没有缺陷的,还是成熟的/未成熟的?谈到深度学习,解决这个问题的关键技术是图像处理。在这个分类问题中,我们需要使用预训练过的Keras VGG16模型来识别给定图像中的番茄是成熟的还是未成熟的。
该模型对来自ImageNet数据集的390幅成熟番茄和未成熟番茄图像进行训练,并对18幅不同的番茄验证图像进行测试。这些验证图像的总体结果如下:
Recall 0.8888889 Precision 0.9411765 F1 Score 0.9142857
小汽车分类 https://github.com/michalgdak/car-recognition
有很多方法来分类一辆车—根据它的车身风格,门的数量,打开或关闭的顶棚,座位的数量,等等。在这个特殊的问题中,我们必须把汽车的图像分成不同的类别。这些类包括制造商,型号,生产年份,例如2012 Tesla model s。为了开发这个模型,我们使用了斯坦福的car数据集,其中包含了196个车型类别的16,185张图片。
使用预训练的VGG16、VGG19和InceptionV3模型对模型进行训练。VGG网络的特点是简单,只使用3×3 卷积层叠加在一起,增加深度。16和19代表网络中权重层的数量。
由于数据集较小,最简单的模型,即VGG16,是最准确的。在交叉验证数据集上,VGG16网络训练的准确率为66.11%。更复杂的模型,如InceptionV3,由于偏差/方差问题,精度较低。
人脸识别和重建 人脸识别在深度学习领域非常流行。越来越多的技术和模型正在以惊人的速度发展,以提升识别技术。它的应用范围很广——手机解锁、人群检测、通过分析人脸来分析情绪,等等。
另一方面,人脸重建是由人脸的近距离图像生成三维模型人脸。利用二维信息创建三维结构化对象是业界的另一个深思熟虑的问题。面部再生技术在电影和游戏行业有着广泛的应用。各种CGI模型都可以自动化,从而节省了大量的时间和金钱。
本文的这一部分讨论这两个领域的预训练模型。
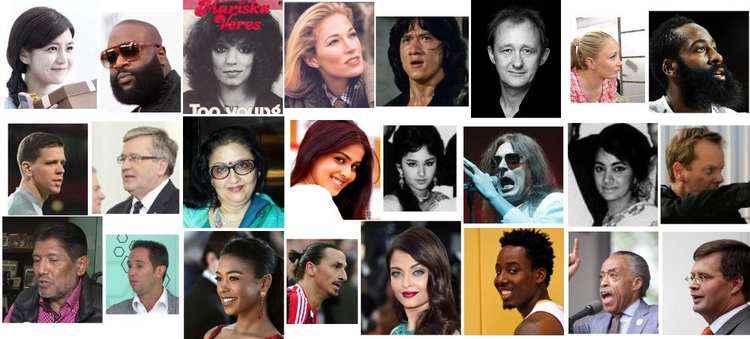
VGG-Face Model https://gist.github.com/EncodeTS/6bbe8cb8bebad7a672f0d872561782d9
从零开始创建人脸识别模型是一项艰巨的任务。你需要查找、收集并标注大量图像,才能有希望构建一个像样的模型。因此,在这个领域中使用预训练的模型很有意义。
VGG-Face 是一个包含2,622个唯一身份的数据集,包含200多万张面孔。该预训练模型的设计方法如下:
从单张图像重建3D人脸 https://github.com/dezmoanded/vrn-torch-to-keras
这是一个很酷的深度学习的实现。你可以从上面的图像中推断出这个模型是如何工作的,以便将面部特征重构成一个三维空间。
这个预训练模型最初是使用Torch 开发的,然后转换到Keras。
分割 图像语义分割—Deeplabv3+ https://github.com/bonlime/keras-deeplab-v3-plus
语义图像分割的任务是为图像中的每个像素分配一个语义标签。这些标签可以是“天空”、“汽车”、“道路”、“长颈鹿”等。这种技术的作用是找到目标的轮廓,从而限制了精度要求(这就是它与精度要求宽松得多的图像级分类的区别)。
Deeplabv3是谷歌最新的语义图像分割模型。它最初是使用TensorFlow创建的,现在已经使用Keras实现。这个GitHub库还提供了如何获取标签的代码,如何使用这个预训练的模型来定制类的数量,当然还有如何跟踪自己的模型。
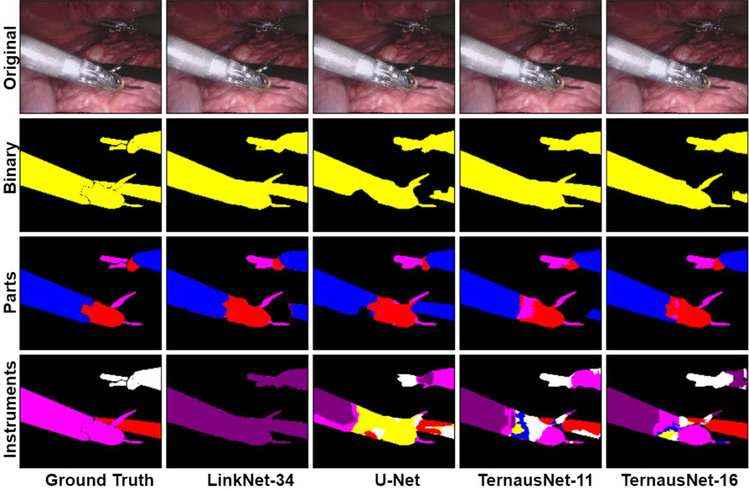
手术机器人图像分割 https://github.com/ternaus/robot-surgery-segmentation
该模型试图解决机器人辅助手术场景下手术器械的图像分割问题。问题进一步分为两部分,具体如下:
二值分割: 图像中的每个像素都被标记为一个工具或背景
多类分割: 将不同的仪器或仪器的不同部分与背景区分开来
该预训练模型基于U-Net网络体系结构,并通过使用最先进的语义分割神经网络LinkNet和TernausNet进一步改进。对8×225帧高分辨率立体相机图像序列进行训练。
杂项 图像描述 https://github.com/boluoyu/ImageCaption
还记得那些游戏吗?在那些游戏中,你会看到一些图片,然后你必须为它们配上说明文字。这就是图像标题的基本含义。它使用了NLP和计算机视觉的结合来产生字幕。长期以来,该任务一直是一个具有挑战性的任务,因为它需要具有无偏置图像和场景的大型数据集。考虑到所有这些约束条件,该算法必须对任意给定的图像进行推广。
现在很多企业都在利用这种技术,但是你如何使用它呢?解决方案在于将给定的输入图像转换为简短而有意义的描述。编码-解码器框架被广泛应用于这一任务。图像编码器是一个卷积神经网络(CNN)。
这是一个在MS COCO数据集 上的VGG 16预训练模型,其中解码器是一个长短时记忆(LSTM)网络,用于预测给定图像的标题。要获得详细的解释和介绍,建议你继续阅读我们关于[自动图像标题 ]的文章( https://www.analyticsvidhya.com/blog/2018/04/solving-animage-title -task- use -deep-learning/)。
结束语 深度学习是一个很难适应的领域,这就是为什么我们看到研究人员发布了这么多预训练过的模型。我个人使用它们来理解和扩展我对对象检测任务的知识,我强烈建议从上面选择一个领域,并使用给定的模型开始您自己的旅程。
—END—
英文原文: https://www.analyticsvidhya.com/blog/2018/07/top-10-pretrained-models-get-started-deep-learning-part-1-computer-vision/
请长按或扫描二维码关注本公众号
喜欢的话,请给我个好看吧 !








 —END—
—END—













 京公网安备 11010802041100号
京公网安备 11010802041100号