算法、表达式、匿名函数、作业算法及二分法算法算法就是解决问题的有效方法,一个算法可能是针对某个问题而设计的,也可以是针对某些问题而设计。在python中,如何对列表进行一系列操作的
算法、表达式、匿名函数、作业
算法及二分法
算法
算法就是解决问题的有效方法,一个算法可能是针对某个问题而设计的,也可以是针对某些问题而设计。
在python中,如何对列表进行一系列操作的内置方法是一系列的算法,这些算法也只能操作列表。
如果我们想算1+1,上面的内置方法就压根算不了,并不是算法不够好,而是术业有专攻。
而一般来说,我们对于复杂问题的解决方式更加被认可为算法,算法有高效的也有低效的。
查找算法
比如说有一个有序的列表[11, 23, 44, 64, 71, 78, 91, 107, 114, 125, 131, 201, 210, 212, 456, 678],我想在这个表里查找一个目标值如125,该设计一个什么样的算法。
在我们已学的知识里,只要用for循环遍历一遍,实际上就可以解决了。
l1 = [11, 23, 44, 64, 71, 78, 91, 107, 114, 125, 131, 201, 210, 212, 456, 678] # 一个很长的列表,长度为n
for num in l1: # 逐一进行遍历
if num == 125:
print('找到了')
break
else:
print('没找到啊')
但是,对于查找来说,这个算法并不高效。
如果要找的元素列表里根本没有,那不是每一次都要将列表整整的遍历一遍吗?
针对这个问题,我们要注意到列表是有序的,那么在我们的目标值小于当前遍历的值时,就不必再往后遍历了。这样就可以平均缩短一半的遍历时间:
l1 = [11, 23, 44, 64, 71, 78, 91, 107, 114, 125, 131, 201, 210, 212, 456, 678] # 一个很长的列表,长度为n
for num in l1:
if num == 123:
print('找到了')
break
elif num > 123:
print('列表里面没有啊')
break
else: # 遍历到最后一个元素678,都比目标值小的时候会走到这里。
print('列表里面没有啊')
如果列表很长,但是要找到的元素很靠后呢?
上述算法虽然缩短了一半的平均时间,但这样的提升并不算大,如果列表长度是20000,那平均每次遍历就是10000次。并没有质的提升。
这是就要提到经典的二分算法了。
二分法查找
l1 = [11, 23, 44, 64, 71, 78, 91, 107, 114, 125, 131, 201, 210, 212, 456, 678]
target = 107 # 随时更改目标值
while l1:
mid_index = len(l1) // 2 # 每次循环从列表取中间值
if l1[mid_index] == target:
print('找到了')
break
elif l1[mid_index] > target: # 如果目标值小于中间值
l1 = l1[:mid_index] # 则目标值在左边,去半左边列表
elif l1[mid_index] l1 = l1[mid_index + 1:] # 则目标值在右边,去右半边列表
else:
print('列表中没有目标值')
我们来理一理,107是怎么被找到呢:
- 首先要先与列表中心114做比对,小于114,所以向左得到一个新的列表
[11, 23, 44, 64, 71, 78, 91, 107,]
- 进入下一次循环,与新列表中心71做比对,大于71,向右得到一个新列表
[78, 91, 107,]
- 进入下一次循环,新的中心是91,大于91,向右得到一个新的列表
[107,]
- 下一次循环,新中心是107,找到了!
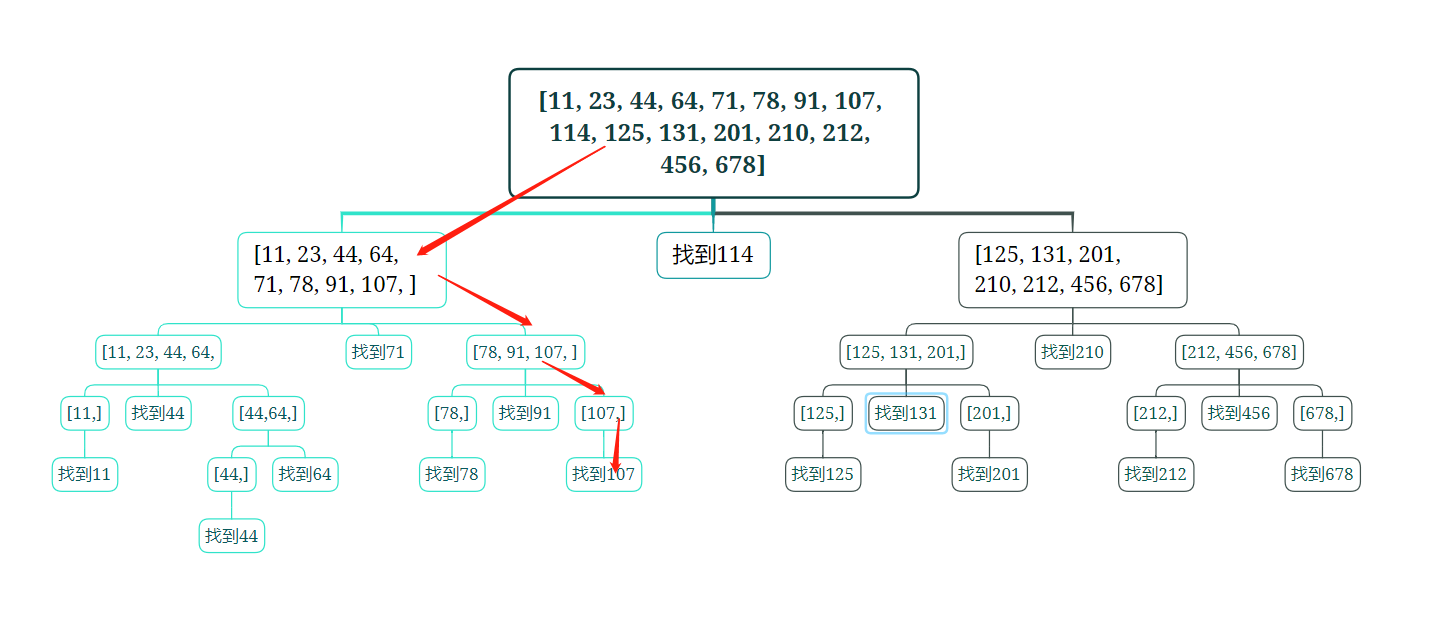
在这样的查询算法中,列表不不断的分成两段,无论你的列表有多少层,查找次数都不会超过log2^n,其中n为列表的长度,如果有20000长度的列表,则最多只需要查找14次就能够查找到,这个遍历次数的降低是数量级的降低!
如果列表不是很长,而且经常取头部的数据,那显然直接用for循环的算法反而更优于二分法查找。
所以还是那句话,算法是针对某类问题设计的,它的高效或低效是对它要解决的问题而言的。
表达式和生成式
在python中,分支结构和for循环结构十分的常用,它们也有一些简化的版本。
三元表达式
分支结构if的一般用法:
name = input('输入你的大名')
if name =='leethon':
print('handsome boy')
else:
print('点个赞呗,大帅哥')
这样二选一的结构占了四行,不是很优雅,python提供了简洁的语法:
name = input('输入你的大名')
res = 'handsome boy' if name == 'leethon' else '点个赞呗,大帅哥' # 三元表达式
print(res)
二选一的if-else结构被简化为了一行,十分的优雅。
这样的结构叫三元表达式,三元指,
一元:数据值if二元:判断条件else三元:数据值
如果判断条件成立则返回if左侧的数据值,如果判断条件不成立则返回else右侧的数据值。
列表生成式
如何对一个列表进行整体型的操作,如:
对列表[1, 2, 3, 4, 5]中的每个数字进行+1操作,以最普遍的for循环用法:
l1 = []
for num in [1, 2, 3, 4, 5]:
l1.append(num + 1)
print(l1) # [2, 3, 4, 5, 6]
但是python又给我们提供了更简洁的语法:
l1 = [num + 1 for num in [1, 2, 3, 4, 5]]
print(l1) # [2, 3, 4, 5, 6]
这个优雅快速获取新列表的语法叫列表生成器,通过遍历一个可以遍历的对象,对遍历对象的每个元素进行一定的操作,得到新的列表。
其语法结构的一般形式为
[表达式 for 变量名 in 可被遍历的对象]
执行顺序:
1.for先行,将遍历值的第一个元素塞到变量名里面,
1.for前面表达式的结果被作为新列表的第一个元素(注,这个表达式可以含for后的变量名)
2.进入下一次for循环,遍历新值
2.for前表达式的结果作为第二个元素传入列表
以此类推
表达式中可含变量名的特点,使它可以对可遍历对象的的每个元素做一定的处理,再生成新的列表。
进阶例子
l1 = [[0] for _ in range(10)]
print(l1)
# [[0], [0], [0], [0], [0], [0], [0], [0], [0], [0]]
# 得到一个嵌套的列表
字典生成式
for循环有时会跟两个变量形成以下的结构:
any_dict = {'leethon': 'handsome', 'alex': 'small-handsome', 'lalisa': 'big-bella'}
for k, v in any_dict.items():
print(k, v)
## 运行结果
leethon handsome
alex small-handsome
lalisa big-bella
##
# enumerate内置方法,类似于得到一个序号与值的二元组列表
for index, value in enumerate([1, 2, 3, 4, 5]):
print(index, value)
## 运行结果
0 1
1 2
2 3
3 4
4 5
##
我们也利用for跟两个变量的形式,来构筑字典生成式:
# 打印A-D的ASCII码对应
print({k: v for k, v in enumerate(['A', 'B', 'C', 'D'], start=65)}) # enumerate的start参数,表示序号开头
# {65: 'A', 66: 'B', 67: 'C', 68: 'D'}
字典生成式以{}为外壳,内部也是表达式加for循环的结构,for循环先执行,表达式作为for关键字的子代码后执行。表达式要为键值对的形式才得到字典。
集合生成式
如果{}内部的表达式不是k:v键值对的形式,而是单独一个表达式形式,则产生集合生成式
print({v for v in 'hello'})
# {'l', 'o', 'e', 'h'} # 去重且无序
匿名函数及其应用
匿名函数指没有函数名的函数,无法通过名字找到它的代码,他可以代替如下的结构:
def func(a, b):
return a+b
# 只传参和只返回,所有的表达式在return后写完的结构
匿名函数关键字lambda
lambda 形参:返回值 # lambda语法
代替上述代码写为:
lambda a, b: a+b
匿名函数的应用场景很小,因为代码不能被函数名找到,所以即用即丢。
它常常搭配一些需要传入函数实参的内置函数使用。
常见内置函数
map() —— 映射
map(函数, 可遍历对象) 指将遍历的元素挨个取出来做函数的形参,得到的返回值放到map工厂里,map工厂转换为列表的结果就是每个被函数处理好的元素组成的列表
l1 = [1, 2, 3, 4, 5]
'''如果用有名函数
def func(a):
return a + 1
res = map(func, l1)
'''
res = map(lambda x:x+1, l1) # 而匿名函数这种简单又临时的函数很适合用在这里
print(list(res)) # [2, 3, 4, 5, 6]
"""
元素1经过匿名函数变成2,
元素2经过匿名函数返回3
以此类推
最终res会接收一个迭代器,可以被for循环,所以可以被list()转换为列表
"""
max()/min() —— 最大最小值
# 简单的比较
l1 = [11, 22, 33, 44]
res = max(l1) # 44
# 依据映射关系比较
d1 = {
'leethon': 100,
'jason': 8888,
'lalisa': 99999999,
'alex': 1000
}
# def func(a): # 传键
# return d1.get(a) # 返回字典的值
# res = max(d1, key=func) # key后面跟函数
res = max(d1, key=lambda k: d1.get(k)) # 根据键的值来比较
print(res) # lalisa # 但是返回的是键
max根据映射关系比较的逻辑是:
根据遍历元素映射后的值作依据比较,得到的结果是映射前原本的元素。
reduce()
# reduce 传多个值,返回一个值
from functools import reduce # 已经不是内置方法了,需要导入模块
l1 = [1, 2, 3, 4, 5]
res = reduce(lambda a, b: a * b, l1) # 计算 ((((1+2)+3)+4)+5)
print(res)
作业
"""
1.先编写校验用户身份的装饰器
2.然后再考虑如何保存用户登录状态
3.再完善各种需求
"""
user_data = {
'1': {'name': 'jason', 'pwd': '123', 'access': ['1', '2', '3']},
'2': {'name': 'kevin', 'pwd': '321', 'access': ['1', '2']},
'3': {'name': 'oscar', 'pwd': '222', 'access': ['1']}
}
hashmap = {v.get('name'): k for k, v in user_data.items()}
print(hashmap)
login_user_index = None
def login_auth(mode):
def inner(func):
def wrapper(*args, **kwargs):
global login_user_index
# 如果登录过了,就直接校验权限,并执行功能
if not login_user_index:
# 选择想用的功能时要求登录
username = input('用户名:').strip()
password = input('密码:').strip()
# 校验密码
if username in hashmap:
user_index = hashmap.get(username)
user_dict = user_data.get(user_index)
if user_dict.get('pwd') == password:
# 保存登录状态
login_user_index = hashmap.get(username)
print('登录成功')
else:
print('账户或者密码错误')
return
# 核验用户权限
if login_user_index:
if mode in user_data.get(login_user_index).get('access'):
res = func(*args, **kwargs)
return res
print('抱歉,你没有此功能的权限')
return wrapper
return inner
@login_auth('1')
def func1():
"""func1"""
print('func1')
@login_auth('2')
def func2():
"""func2"""
print('func2')
@login_auth('3')
def func3():
"""func3"""
print('func3')
func_dict = {
'0': quit,
'1': func1,
'2': func2,
'3': func3,
}
while True:
choice = input('功能序号:').strip()
if choice in func_dict:
func_dict.get(choice)()











 京公网安备 11010802041100号
京公网安备 11010802041100号