MapReduce排序
一、 场景数据
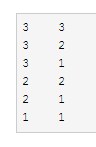
1. 如果按照第一列升序排列。(第一列相同时,按照第二列升序)

2. 如果当第一列相同时,求出第二列的最小值

二、 默认排序partial
1.在hadoop默认排序算法中,只会对key值进行排序。
代码:
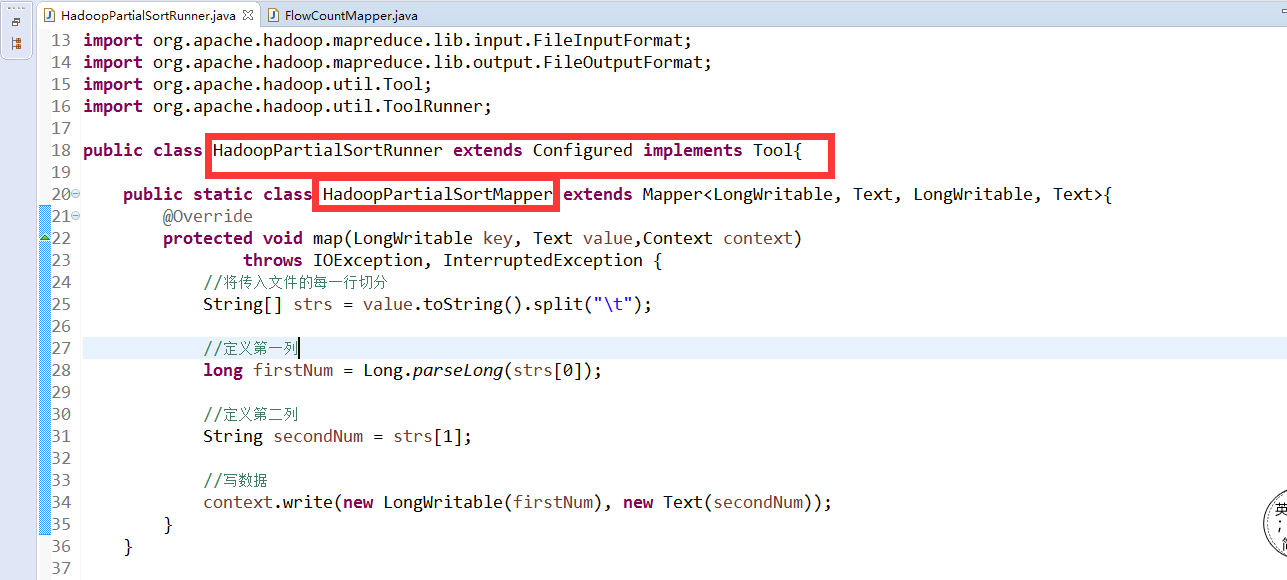
package com.simon.hadoop;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
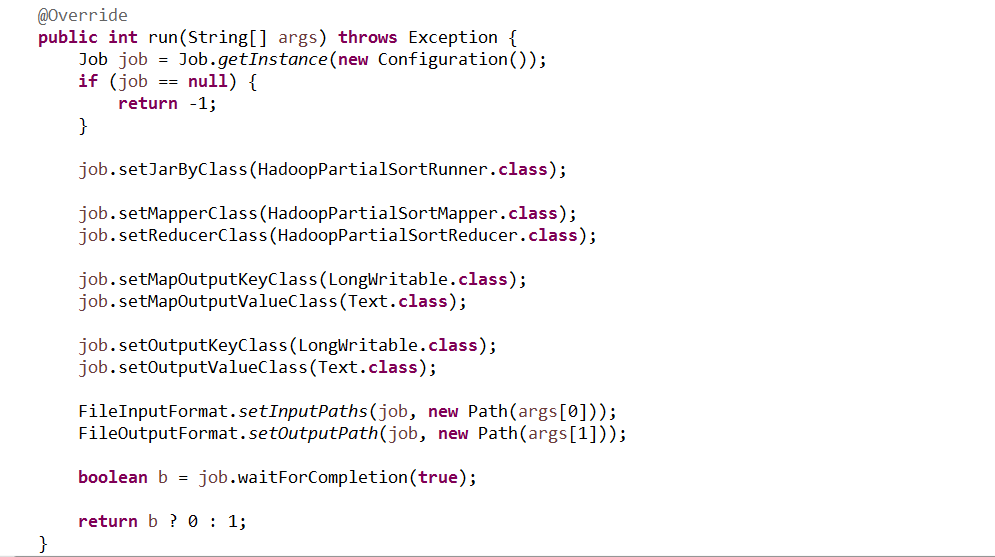
publicclassHadoopPartialSortRunner extends Configured implements Tool{publicstaticclass HadoopPartialSortMapperextendsMapper{@Overrideprotectedvoid map(LongWritable key, Text value,Context context)throws IOException,InterruptedException {//将传入文件的每一行切分 String[] strs = value.toString().split("\t");//定义第一列longfirstNum = Long.parseLong(strs[0]);//定义第二列StringsecondNum= strs[1];//写数据context.write(new LongWritable(firstNum), new Text(secondNum));}}publicstaticclassHadoopPartialSortReducer extends Reducer{@Overrideprotectedvoid reduce(LongWritable key, Iterable values,Context context) throws IOException,InterruptedException {for (Text text : values) {context.write(key, text);}}}@Overridepublicint run(String[] args) throws Exception {Jobjob= Job.getInstance(new Configuration());if (job == null) {return -1;}job.setJarByClass(HadoopPartialSortRunner.class);job.setMapperClass(HadoopPartialSortMapper.class);job.setReducerClass(HadoopPartialSortReducer.class);job.setMapOutputKeyClass(LongWritable.class);job.setMapOutputValueClass(Text.class);job.setOutputKeyClass(LongWritable.class);job.setOutputValueClass(Text.class);FileInputFormat.setInputPaths(job, new Path(args[0]));FileOutputFormat.setOutputPath(job, new Path(args[1]));booleanb = job.waitForCompletion(true);returnb ? 0 : 1;}publicstaticvoid main(String[] args) throws Exception {intexitCode = ToolRunner.run(newHadoopPartialSortRunner(), args);System.exit(exitCode);}
}

2.执行结果
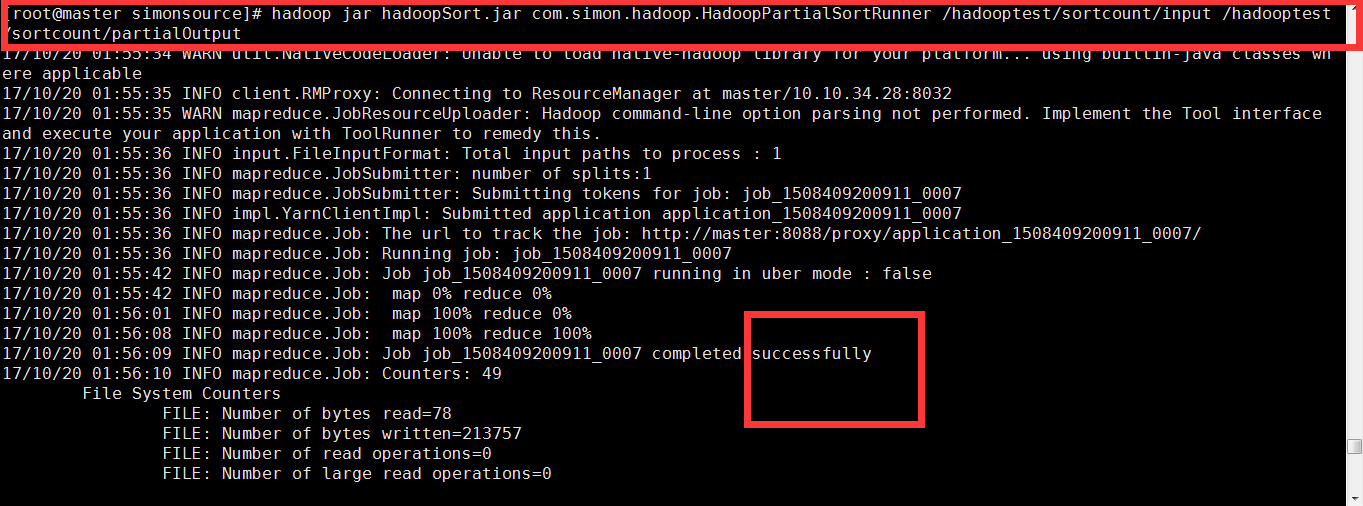
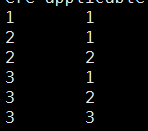
3.查看结果

三、 全排序
四、 二次排序







 京公网安备 11010802041100号
京公网安备 11010802041100号