参考https:blog.csdn.netweixin_43002202https:github.comgraykodenlp-tutorial2013年,Goo
参考https://blog.csdn.net/weixin_43002202
https://github.com/graykode/nlp-tutorial
2013年,Google开源了一款用于词向量计算的工具——word2vec,引起了工业界和学术界的关注。首先,word2vec可以在百万数量级的词典和上亿的数据集上进行高效地训练;其次,该工具得到的训练结果——词向量(word embedding),可以很好地度量词与词之间的相似性。随着深度学习(Deep Learning)在自然语言处理中应用的普及,很多人误以为word2vec是一种深度学习算法。其实word2vec算法的背后是一个浅层神经网络。另外需要强调的一点是,word2vec是一个计算word vector的开源工具。当我们在说word2vec算法或模型的时候,其实指的是其背后用于计算word vector的CBoW模型和Skip-gram模型。
1.独热编码
独热编码即 One-Hot 编码,又称一位有效编码,其方法是使用N位状态寄存器来对N个状态进行编码,每个状态都有它独立的寄存器位,并且在任意时候,其中只有一位有效。举个例子,假设我们有四个样本(行),每个样本有三个特征(列),如图:

我们的feature_1有两种可能的取值,比如是男/女,这里男用1表示,女用2表示。feature_2 和feature_3各有4种取值(状态)。one-hot编码就是保证每个样本中的单个特征只有1位处于状态1,其他的都是0。上述状态用one-hot编码如下图所示:
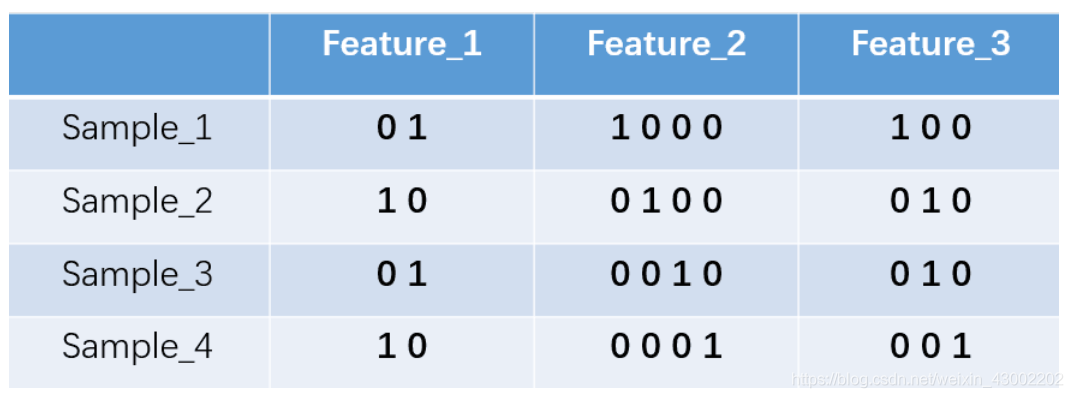
如果将世界所有城市名称作为语料库的话,那这个向量会过于稀疏,并且会造成维度灾难。
杭州 [0,0,0,0,0,0,0,1,0,……,0,0,0,0,0,0,0]
上海 [0,0,0,0,1,0,0,0,0,……,0,0,0,0,0,0,0]
宁波 [0,0,0,1,0,0,0,0,0,……,0,0,0,0,0,0,0]
北京 [0,0,0,0,0,0,0,0,0,……,1,0,0,0,0,0,0]
能不能把词向量的维度变小呢?
Dristributed representation可以解决One hot representation的问题,它的思路是通过训练,将每个词都映射到一个较短的词向量上来。所有的这些词向量就构成了向量空间,进而可以用普通的统计学的方法来研究词与词之间的关系。这个较短的词向量维度是多大呢?这个一般需要我们在训练时自己来指定。
比如下图我们将词汇表里的词用"Royalty","Masculinity", "Femininity"和"Age"4个维度来表示,King这个词对应的词向量可能是(0.99,0.99,0.05,0.7)(0.99,0.99,0.05,0.7)。当然在实际情况中,我们并不能对词向量的每个维度做一个很好的解释。
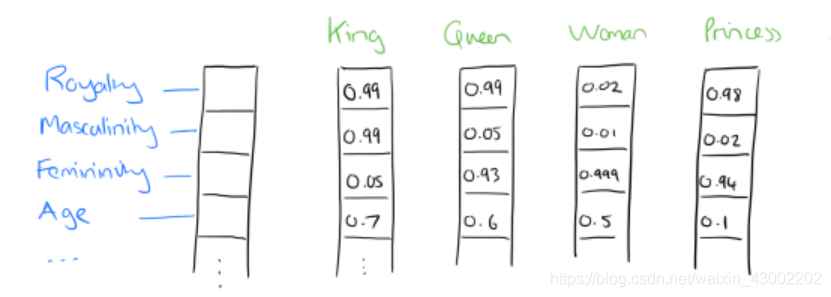
我们将king这个词从一个可能非常稀疏的向量所在的空间,映射到现在这个四维向量所在的空间,必须满足以下性质:
(1)这个映射是单设(不懂的概念自行搜索);
(2)映射之后的向量不会丢失之前的那种向量所含的信息。
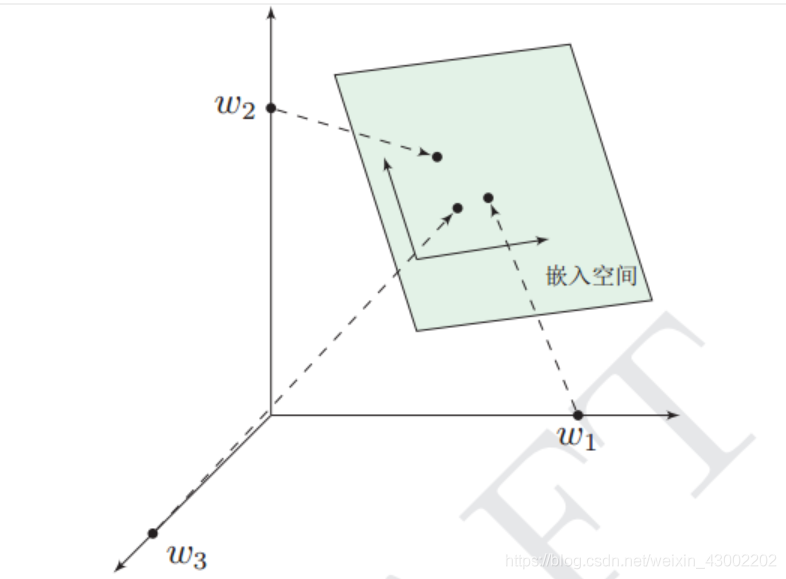
这个过程称为word embedding(词嵌入),即将高维词向量嵌入到一个低维空间。顺便找了个图
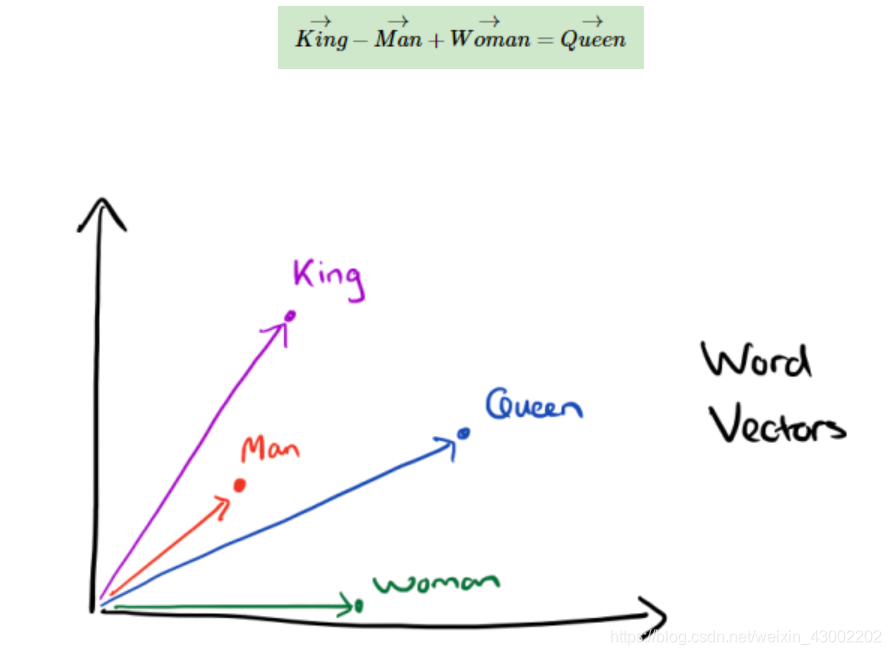
经过我们一系列的降维神操作,有了用Dristributed representation表示的较短的词向量,我们就可以较容易的分析词之间的关系了,比如我们将词的维度降维到2维,有一个有趣的研究表明,用下图的词向量表示我们的词时,我们可以发现:
哈哈哈
出现这种现象的原因是,我们得到最后的词向量的训练过程中引入了词的上下文,使得词向量带有一定的语义信息了。
举个栗子:
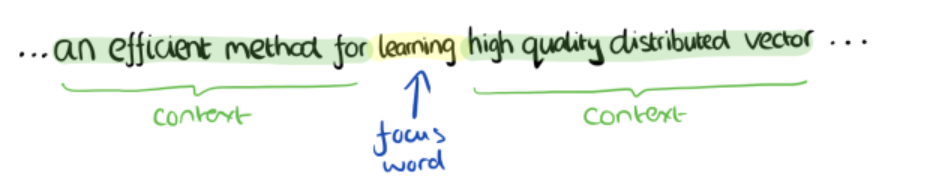
你想到得到"learning"的词向量,但训练过程中,你同时考虑了它左右的上下文,那么就可以使"learning"带有语义信息了。通过这种操作,我们可以得到近义词,甚至cat和它的复数cats的向量极其相近。
2.word2vec
word2vec模型其实就是简单化的神经网络。
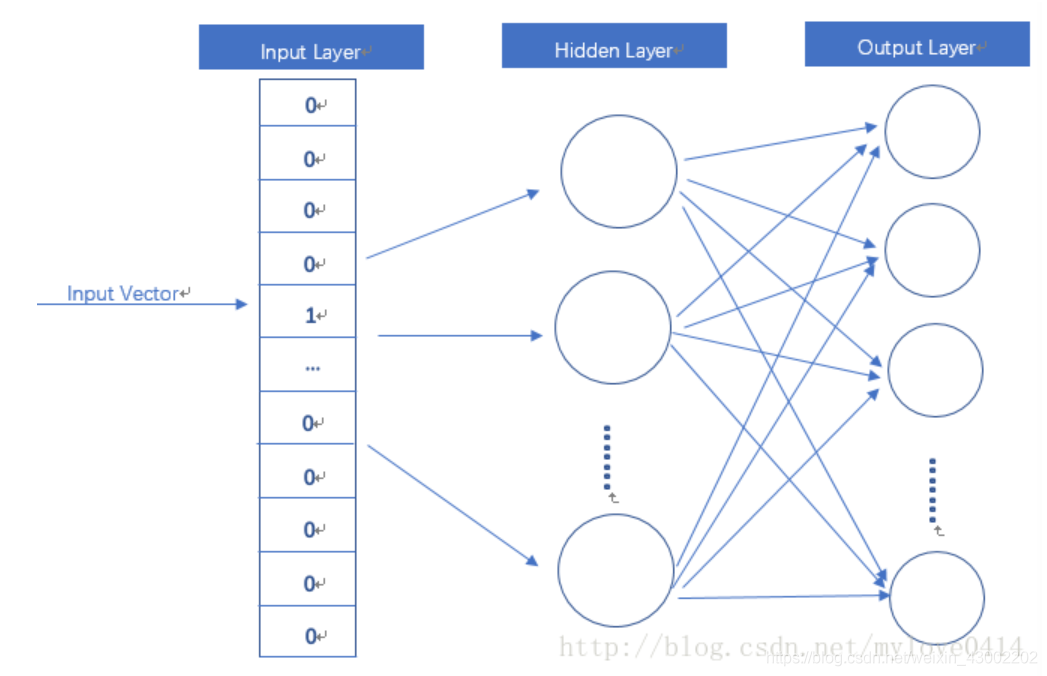
输入是One-Hot Vector,Hidden Layer没有激活函数,也就是线性的单元。Output Layer维度跟Input Layer的维度一样,用的是Softmax回归。
当这个模型训练好以后,我们并不会用这个训练好的模型处理新的任务,我们真正需要的是这个模型通过训练数据所学得的参数,例如隐层的权重矩阵。
这个模型是如何定义数据的输入和输出呢?一般分为CBOW(Continuous Bag-of-Words 与Skip-Gram两种模型。CBOW模型的训练输入是某一个特征词的上下文相关的词对应的词向量,而输出就是这特定的一个词的词向量。 Skip-Gram模型和CBOW的思路是反着来的,即输入是特定的一个词的词向量,而输出是特定词对应的上下文词向量。CBOW对小型数据库比较合适,而Skip-Gram在大型语料中表现更好。
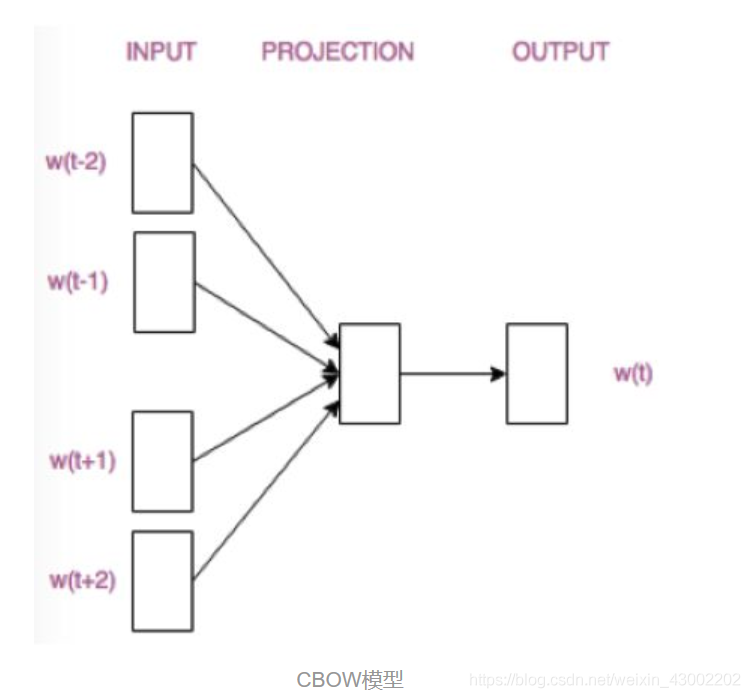
2.1 CBOW(Continuous Bag-of-Words)
CBOW的训练模型如图所示
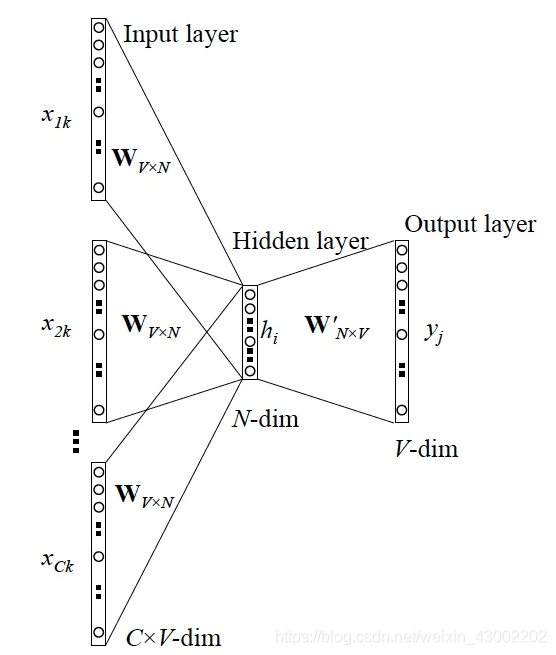
1 输入层:上下文单词的onehot. {假设单词向量空间dim为V,上下文单词个数为C}
2 所有onehot分别乘以共享的输入权重矩阵W. {VN矩阵,N为自己设定的数,初始化权重矩阵W}
3 所得的向量 {因为是onehot所以为向量} 相加求平均作为隐层向量, size为1N.
4 乘以输出权重矩阵W' {NV}
5 得到向量 {1V} 激活函数处理得到V-dim概率分布 {PS: 因为是onehot嘛,其中的每一维斗代表着一个单词}
6 概率最大的index所指示的单词为预测出的中间词(target word)与true label的onehot做比较,误差越小越好(根据误差更新权重矩阵)
举个栗子:
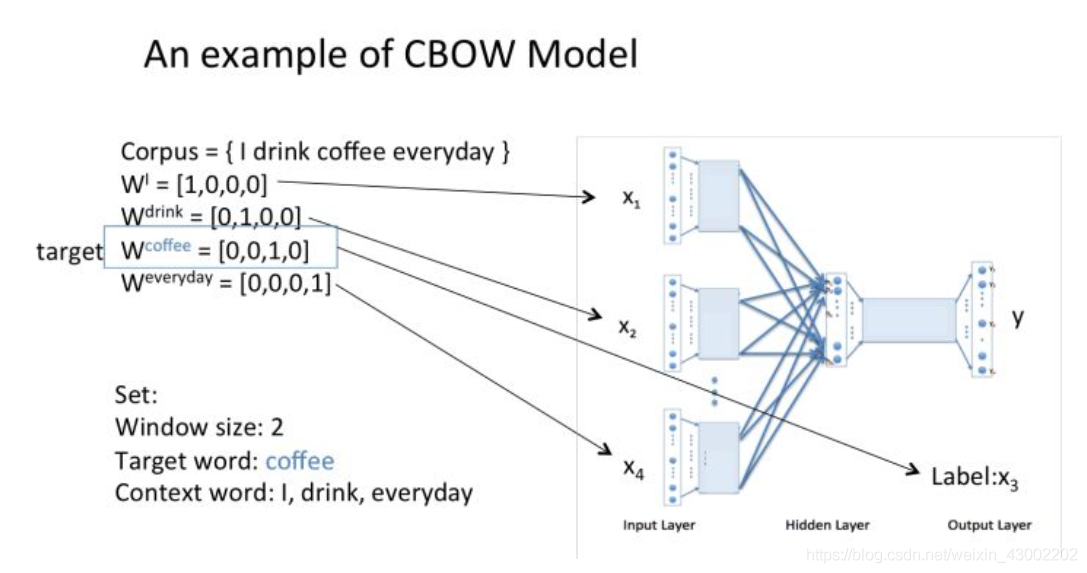
窗口大小是2,表示选取coffe前面两个单词和后面两个单词,作为input词。

假设我们此时得到的概率分布已经达到了设定的迭代次数,那么现在我们训练出来的look up table应该为矩阵W。即,任何一个单词的one-hot表示乘以这个矩阵都将得到自己的word embedding。
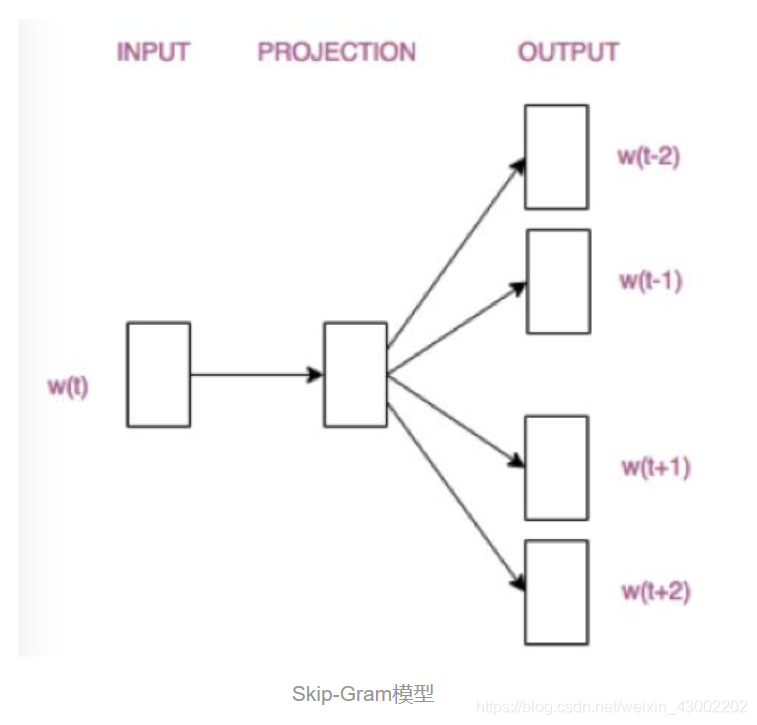
2.2 Skip-Gram
从直观上理解,Skip-Gram是给定input word来预测上下文。
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as nptf.reset_default_graph()# 3 Words Sentence
sentences = [ "i like dog", "i like cat", "i like animal","dog cat animal", "apple cat dog like", "dog fish milk like","dog cat eyes like", "i like apple", "apple i hate","apple i movie book music like", "cat dog hate", "cat dog like"]word_sequence = " ".join(sentences).split()
word_list = " ".join(sentences).split()
word_list = list(set(word_list))
word_dict = {w: i for i, w in enumerate(word_list)}# Word2Vec Parameter
batch_size = 20
embedding_size = 2 # To show 2 dim embedding graph
voc_size = len(word_list)def random_batch(data, size):random_inputs = []random_labels = []random_index = np.random.choice(range(len(data)), size, replace=False)for i in random_index:random_inputs.append(np.eye(voc_size)[data[i][0]]) # targetrandom_labels.append(np.eye(voc_size)[data[i][1]]) # context wordreturn random_inputs, random_labels# Make skip gram of one size window
skip_grams = []
for i in range(1, len(word_sequence) - 1):target = word_dict[word_sequence[i]]cOntext= [word_dict[word_sequence[i - 1]], word_dict[word_sequence[i + 1]]]for w in context:skip_grams.append([target, w])# Model
inputs = tf.placeholder(tf.float32, shape=[None, voc_size])
labels = tf.placeholder(tf.float32, shape=[None, voc_size])# W and WT is not Traspose relationship
W = tf.Variable(tf.random_uniform([voc_size, embedding_size], -1.0, 1.0))
WT = tf.Variable(tf.random_uniform([embedding_size, voc_size], -1.0, 1.0))hidden_layer = tf.matmul(inputs, W) # [batch_size, embedding_size]
output_layer = tf.matmul(hidden_layer, WT) # [batch_size, voc_size]cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits_v2(logits=output_layer, labels=labels))
optimizer = tf.train.AdamOptimizer(0.001).minimize(cost)with tf.Session() as sess:init = tf.global_variables_initializer()sess.run(init)for epoch in range(5000):batch_inputs, batch_labels = random_batch(skip_grams, batch_size)_, loss = sess.run([optimizer, cost], feed_dict={inputs: batch_inputs, labels: batch_labels})if (epoch + 1)%1000 == 0:print('Epoch:', '%04d' % (epoch + 1), 'cost =', '{:.6f}'.format(loss))trained_embeddings = W.eval()for i, label in enumerate(word_list):x, y = trained_embeddings[i]plt.scatter(x, y)plt.annotate(label, xy=(x, y), xytext=(5, 2), textcoords='offset points', ha='right', va='bottom')
plt.show()
再次提醒,最终我们需要的是训练出来的权重矩阵。





 京公网安备 11010802041100号
京公网安备 11010802041100号