作者:拍友2502902623 | 来源:互联网 | 2023-08-22 16:50
1.1初识人工智能1.1.0abstract1.1.1人工智能与机器学习的关系1.1.1.1什么是人工智能1.1.1.2限制领域AI和通用领域AI1.1.1.3什么是机器学习1.1
1.1初识人工智能 1.1.0 abstract 1.1.1 人工智能与机器学习的关系 1.1.1.1 什么是人工智能 1.1.1.2 限制领域AI和通用领域AI 1.1.1.3 什么是机器学习 1.1.1.4 从数据中学出规律 1.1.1.5 什么是深度学习 1.1.1.6 人工智能、机器学习和深度学习之间的关系 1.1.2 监督学习和无监督学习 1.1.3 常见的机器学习算法 1.1.4 回归问题与分类问题 1.1.5 样本,特征和标签 1.1.6 训练数据和测试数据 1.1.7 机器学习建模流程
1.1.0 abstract 声明:本文只为我闲暇时候学习所做笔记,仅供我无聊时复习所用,若文中有错,误导了读者,敬请谅解!!!
1.1.1 人工智能与机器学习的关系
1.1.1.1 什么是人工智能
1.1.1.2 限制领域AI和通用领域AI
1.1.1.3 什么是机器学习
1.1.1.4 从数据中学出规律
1.1.1.5 什么是深度学习 [外链图片转存失败(img-pUtcydC7-1569209662736)(https://cdn.nlark.com/yuque/0/2019/jpeg/501351/1569181345655-a7202d72-dff7-403c-a93d-4f177e8887f4.jpeg?x-oss-process=image/resize,h_450)]
1.1.1.6 人工智能、机器学习和深度学习之间的关系
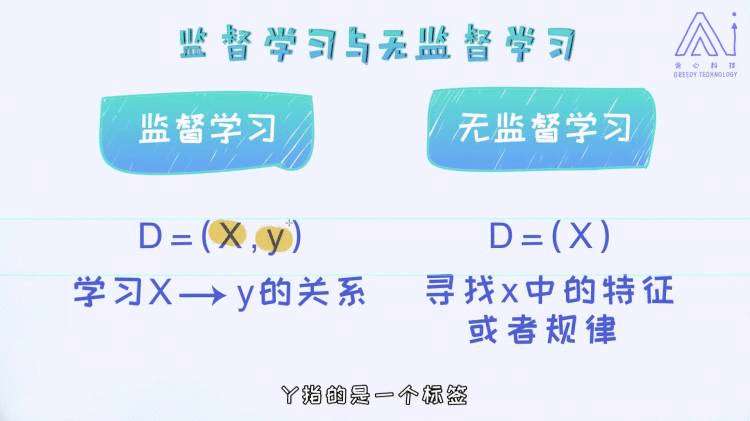
1.1.2 监督学习和无监督学习
监督学习的样本数据D,包含了特征向量X,和对应的标签y,监督学习的任务就是通过对已有的已经标注好特征和标签的样本数据D的学习,找到一个预测函数_f_来实现特征向量X到y的映射关系,通多_f_来预测未标注样本的标签y。
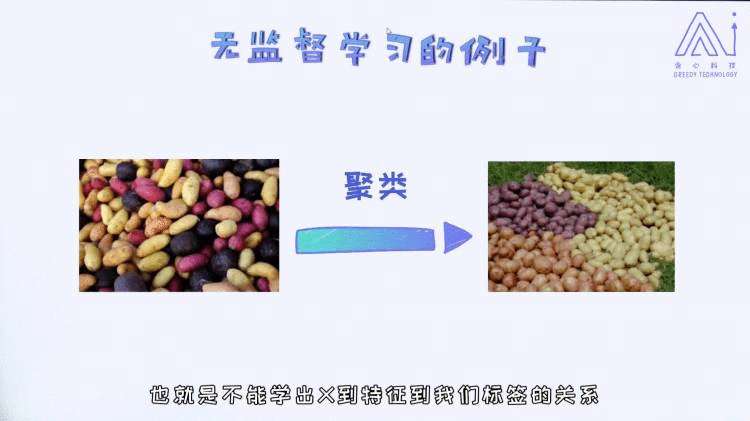
无监督的样本数据D中的数据一般每个样本只有特征向量,没有特征所对应的标签,无监督学习主要是研究样本特征之间的规律,比如聚类等。
无监督学习案例: 1.1.3 常见的机器学习算法
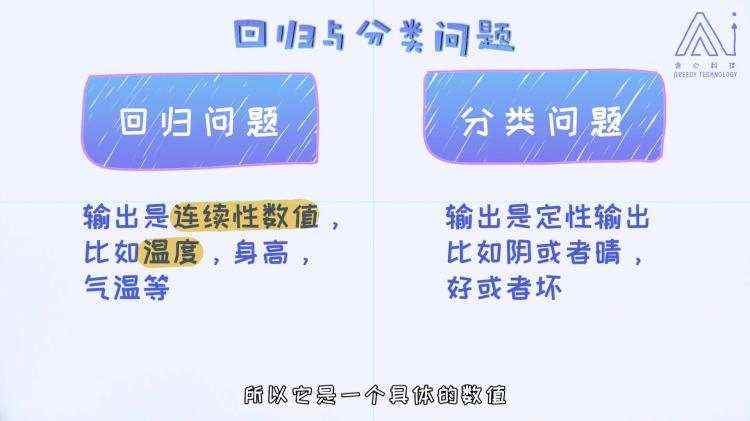
1.1.4 回归问题与分类问题
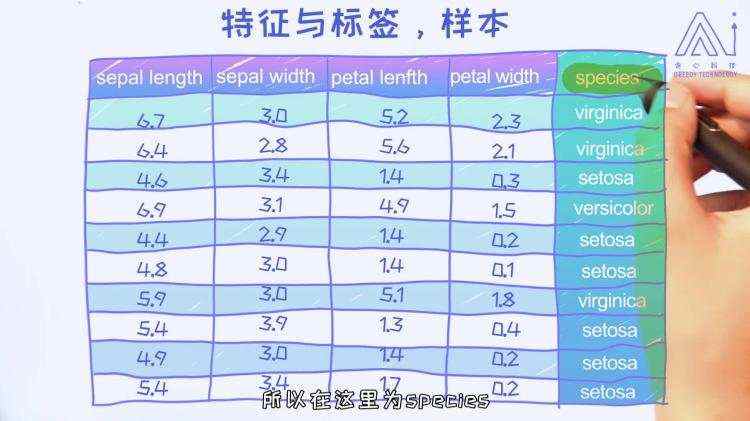
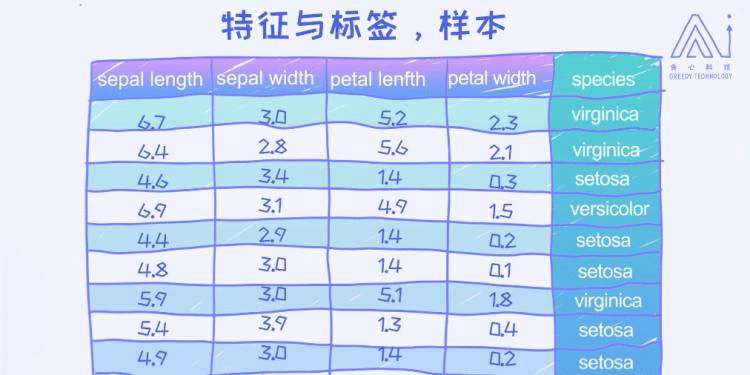
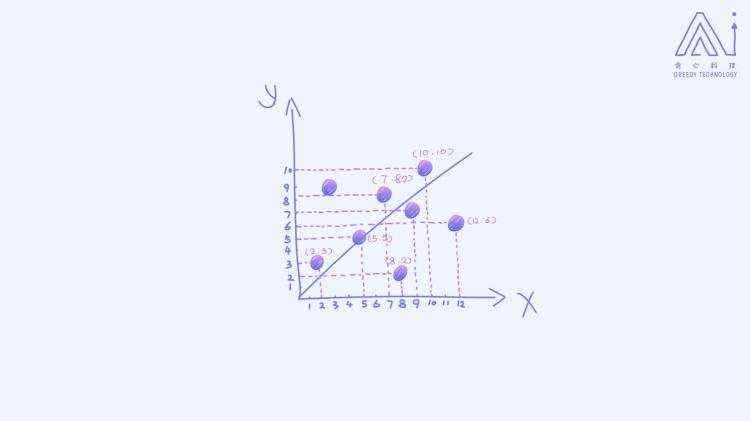
回归问题的输出值一般是连续性的数值 分类问题的输出值一般是离散的值 简单来讲,回归问题就是用来预测某一个具体的数值,分类问题则预测某一个具体的类别。两个都属于监督学习的范畴。 1.1.5 样本,特征和标签
1.1.6 训练数据和测试数据
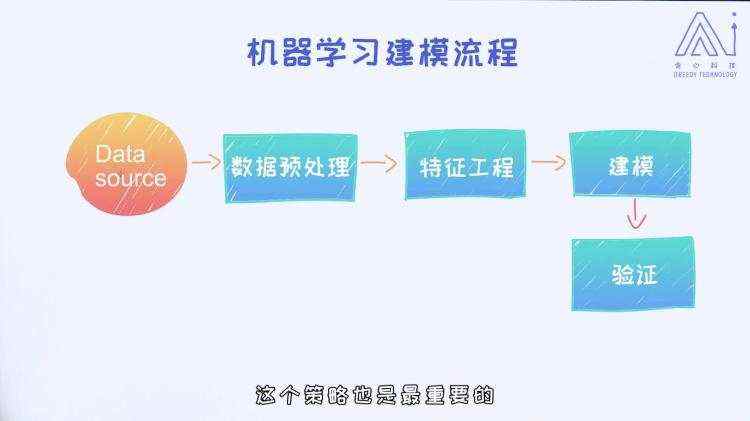
1.1.7 机器学习建模流程
数据集:机器学习的基础,一切研究的基础 数据预处理:数据清洗,去掉缺失数据,数据填补等 特征工程:将数据转换成为数值类型的数据来表示,比如向量,矩阵,张量,来直接作为模型的输入 建模:机器学习模型的尝试,组合,调参 验证:通过测试数据集,对模型的验证




















 京公网安备 11010802041100号
京公网安备 11010802041100号