目录1.思路和流程分析2.准备训练集和测试集2.1torchvision.transforms的图形数据处理方法2.1.1torchvison.transforms.ToT

目录
1.思路和流程分析
2.准备训练集和测试集
2.1 torchvision.transforms的图形数据处理方法
2.1.1 torchvison.transforms.ToTensor
2.1.2 torchvision.transforms.Normalize(mean,std)
2.1.3 torchvision.transforms.Compose(transforms)
2.2 准备MNIST数据集的Dataset和DataLoader
3.构建模型
3.1 激活函数的使用
3.2 模型中数据的形状(【添加形状变化图形】)
3.3 模型的损失函数
4.模型的训练
5.模型的保存和加载
5.1 模型的保存
5.2 模型的加载
6.模型的评估
7.总的代码
1.思路和流程分析

2.准备训练集和测试集

from torchvision.datasets import MNIST
mnist=MNIST(root=r'D:\各种编译器的代码\pythonProject12\机器学习\NLP自然语言处理\datas',train=True,download=True,transform=None)#len(mnist)==60000
print(mnist[0])#(, 5)
img=mnist[0][0]
img.show()#打开图片

from torchvision import transforms
import numpy as np
data=np.random.randint(0,255,size=12)
img=data.reshape(2,2,3)
print(img.shape)
img_tensor=transforms.ToTensor()(img)#转换成tensor
print(img_tensor)
print(img_tensor.size())
输出如下:
(2, 2, 3)
tensor([[[235, 30],[236, 92]],[[ 1, 113],[ 53, 5]],[[ 21, 190],[ 46, 11]]], dtype=torch.int32)
torch.Size([3, 2, 2])


from torchvision import transforms
import numpy as np
import torchvision
data=np.random.randint(0,255,size=12)
img=data.reshape(2,2,3)
img=transforms.ToTensor()(img)#转换成tensor
print(img)
print('*'*100)
norm_img=transforms.Normalize((10,10,10),(1,1,1))(img)#进行规范化处理
print(norm_img)

transforms.Compose([torchvision.transforms.ToTensor(),#先转换为Tensortorchvision.transforms.Normalize(mean,std)#再进行正则化
])
2.2 准备MNIST数据集的Dataset和DataLoader
准备训练集:
from torchvision.datasets import MNIST
from torchvision.transforms import Compose,ToTensor,Normalize
from torch.utils.data import DataLoaderBATCH_SIZE=128
#1.准备数据
def get_dataloader(train=True):transform_fn = Compose([ToTensor(),Normalize(mean=(0.1307,), std=(0.3081,)) # mean std的形状和通道数相同])dataset = MNIST(root=r'D:\各种编译器的代码\pythonProject12\机器学习\NLP自然语言处理\datas', train=True, transform=transform_fn)data_loader = DataLoader(dataset, batch_size=BATCH_SIZE, shuffle=True)return data_loader
3.构建模型

3.1 激活函数的使用

import torch
import torch.nn.functional as F
b=torch.Tensor([-2,-1,0,1,2])
print(F.relu(b)) #tensor([0., 0., 0., 1., 2.])
3.2 模型中数据的形状(【添加形状变化图形】)

import torch.nn as nn
import torch.nn.functional as F#2.构建模型
class MnistNodel(nn.Module):def __init__(self):super(MnistNodel,self).__init__()self.fc1=nn.Linear(1*28*28,28)#第一个全连接self.fc2=nn.Linear(28,10)#第二个全连接 最终有10个类别def forward(self,input):""":param input:[batch_size,1,28,28]:return:输出层"""#1.修改形状x=input.view([input.size(0),1*28*28])#或者input.view([-1,1*28*28])#2,进行全连接的操作x=self.fc1(x)#3.进行激活函数的处理x=F.relu(x)#形状无变化#4.输出层out=self.fc2(x)return out
3.3 模型的损失函数

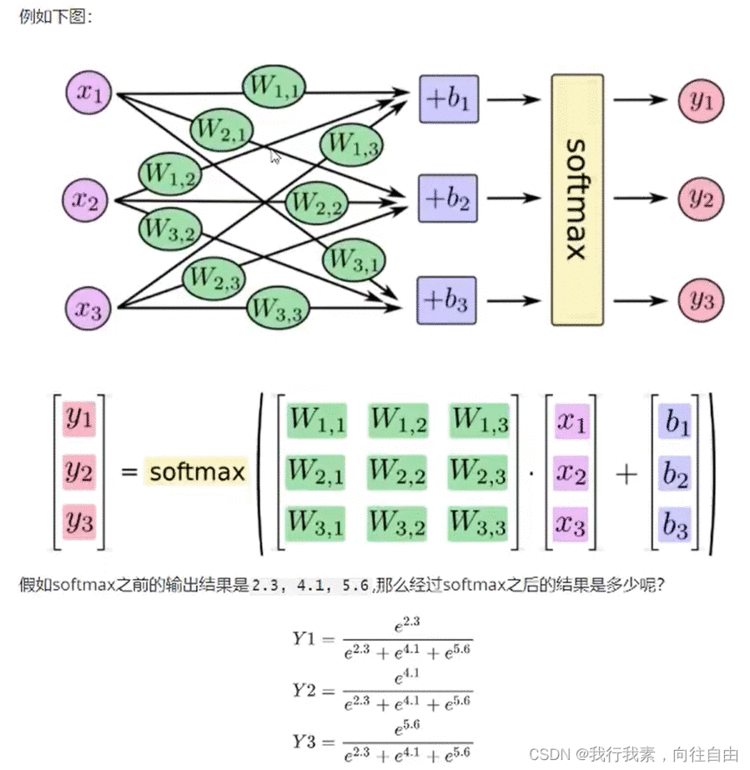

#方法一
criterion=nn.CrossEntropyLoss()#交叉熵损失
loss=criterion(input,target)#方法二
output=F.log_softmax(x,dim=-1)#1.对输出值计算softmax和取对数
loss=F.nll_loss(output,target)#2.使用torch中带权损失nll_loss

4.模型的训练

from torch.optim import Adammodel=MnistNodel()#实例化模型
optimizer=Adam(model.parameters(),lr=0.001)
def train(epoch):'''实现训练的过程'''data_loader=get_dataloader()for idx,(input,target) in enumerate(data_loader):optimizer.zero_grad()output=model(input)#调用模型,得到预测值loss=F.nll_loss(output,target)#得到损失loss.backward()#反向传播optimizer.step()#梯度的更新if idx%100==0:print(epoch,idx,loss.item(),sep='\t')
5.模型的保存和加载
5.1 模型的保存
torch.save(model.state_dict(),'path')#保存模型参数
torch.save(optimizer.state_dict(),'path')#保存优化器参数
5.2 模型的加载
model.load_state_dict(torch.load('path'))
optimizer.load_state_dict(torch.load('path'))
6.模型的评估

import numpy as npdef test():loss_list=[]acc_list=[]test_dataloader=get_dataloader(train=False)for idx,(input,target) in enumerate(test_dataloader):with torch.no_grad():output=model(input)cur_loss=F.nll_loss(output,target)loss_list.append(cur_loss)#计算准确率#output [batch_size,10] target:[batch_size]pred=output.max(dim=-1)[-1]cur_acc=pred.eq(target).float().mean()acc_list.append(cur_acc)print('平均准确率:',np.mean(acc_list),'\t平均损失:',np.mean(loss_list))#结果如下:
# 平均准确率: 0.9503709 平均损失: 0.17310049
7.总的代码
import torch,os
import numpy as np
from torchvision.datasets import MNIST
from torchvision.transforms import Compose,ToTensor,Normalize
from torch.utils.data import DataLoader
import torch.nn as nn
import torch.nn.functional as F
from torch.optim import AdamBATCH_SIZE=128
#1.准备数据
def get_dataloader(train=True):transform_fn = Compose([ToTensor(),Normalize(mean=(0.1307,), std=(0.3081,)) # mean std的形状和通道数相同])dataset = MNIST(root=r'D:\各种编译器的代码\pythonProject12\机器学习\NLP自然语言处理\datas', train=True, transform=transform_fn)data_loader = DataLoader(dataset, batch_size=BATCH_SIZE, shuffle=True)return data_loader#2.构建模型
class MnistNodel(nn.Module):def __init__(self):super(MnistNodel,self).__init__()self.fc1=nn.Linear(1*28*28,28)#第一个全连接self.fc2=nn.Linear(28,10)#第二个全连接 最终有10个类别def forward(self,input):""":param input:[batch_size,1,28,28]:return:输出层"""#1.修改形状x=input.view([input.size(0),1*28*28])#或者input.view([-1,1*28*28])#2,进行全连接的操作x=self.fc1(x)#3.进行激活函数的处理x=F.relu(x)#形状无变化#4.输出层out=self.fc2(x)return F.log_softmax(out)model=MnistNodel()#实例化模型
if os.path.exists(r'D:\各种编译器的代码\pythonProject12\机器学习\NLP自然语言处理\模型的保存\mnist_model.pkl'):model.load_state_dict(torch.load(r'D:\各种编译器的代码\pythonProject12\机器学习\NLP自然语言处理\模型的保存\mnist_model.pkl'))
optimizer=Adam(model.parameters(),lr=0.001)
if os.path.exists(r'D:\各种编译器的代码\pythonProject12\机器学习\NLP自然语言处理\模型的保存\mnist_optimizer.pkl'):optimizer.load_state_dict(torch.load(r'D:\各种编译器的代码\pythonProject12\机器学习\NLP自然语言处理\模型的保存\mnist_optimizer.pkl'))def train(epoch):'''实现训练的过程'''data_loader=get_dataloader()for idx,(input,target) in enumerate(data_loader):optimizer.zero_grad()output=model(input)#调用模型,得到预测值loss=F.nll_loss(output,target)#得到损失loss.backward()#反向传播optimizer.step()#梯度的更新if idx%100==0:print(epoch,idx,loss.item(),sep='\t')#模型的保存if idx%100==0:#每隔100个保存一下torch.save(model.state_dict(),r'D:\各种编译器的代码\pythonProject12\机器学习\NLP自然语言处理\模型的保存\mnist_model.pkl')torch.save(optimizer.state_dict(),r'D:\各种编译器的代码\pythonProject12\机器学习\NLP自然语言处理\模型的保存\mnist_optimizer.pkl')def test():loss_list=[]acc_list=[]test_dataloader=get_dataloader(train=False)for idx,(input,target) in enumerate(test_dataloader):with torch.no_grad():output=model(input)cur_loss=F.nll_loss(output,target)loss_list.append(cur_loss)#计算准确率#output [batch_size,10] target:[batch_size]pred=output.max(dim=-1)[-1]cur_acc=pred.eq(target).float().mean()acc_list.append(cur_acc)print('平均准确率:',np.mean(acc_list),'\t平均损失:',np.mean(loss_list))if __name__ == '__main__':# for i in range(3):#训练三轮# train(i)test()



![[翻译]PyCairo指南裁剪和masking](https://img6.php1.cn/3cdc5/9d74/696/ff5f2ae0c65cf286.jpeg)





 京公网安备 11010802041100号
京公网安备 11010802041100号