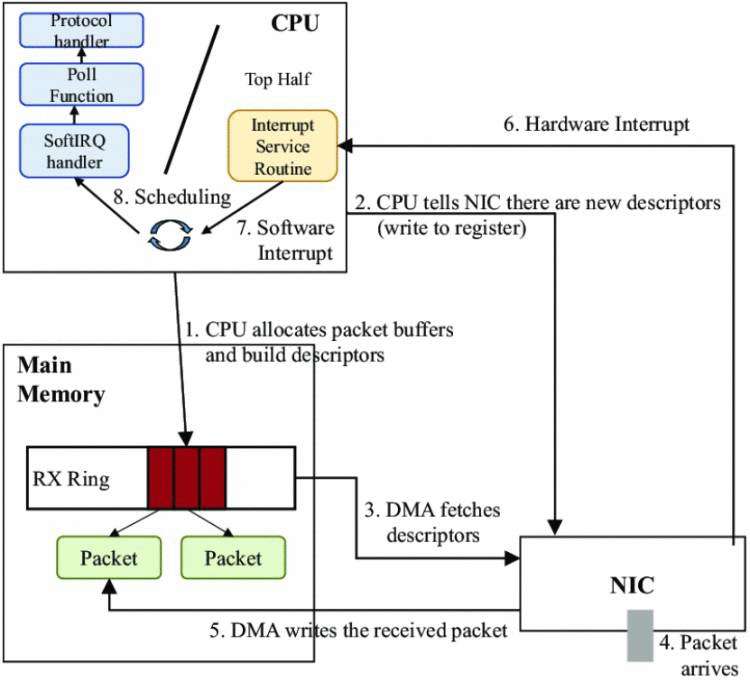
int select(int n, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);int poll (struct pollfd *fds, unsigned int nfds, int timeout);int epoll_create(int size);//创建一个epoll的句柄,size用来告诉内核这个监听的数目一共有多大 int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event); int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);











 京公网安备 11010802041100号
京公网安备 11010802041100号