[源码解析] TensorFlow 分布式之 MirroredStrategy
-
[源码解析] TensorFlow 分布式之 MirroredStrategy
-
1. 设计&思路
- 1.1 主要逻辑
- 1.2 使用
- 1.3 分析思路
-
2. 定义
- 2.1 MirroredStrategy
- 2.2 MirroredExtended
-
3. 初始化
-
3.1 初始化多worker
- 3.1.1 MultiWorkerMirroredStrategy
- 3.1.2 CollectiveAllReduceExtended
-
3.2 跨设备操作
- 3.2.1 CrossDeviceOps
- 3.2.2 ReductionToOneDevice
- 3.2.3 AllReduceCrossDeviceOps
- 3.2.4 NcclAllReduce
- 3.2.5 HierarchicalCopyAllReduce
- 3.2.6 CollectiveAllReduce
-
3.3 单节点初始化
- 3.3.1 初始化单worker
- 3.3.2 建立集合操作
- 3.3.3 如何区分
-
3.1 初始化多worker
-
4. 更新分布式变量
- 4.1 样例
-
4.2 规约
- StrategyExtendedV2
- MirroredExtended
-
4.3 更新
- StrategyExtendedV2
- MirroredExtended
- distribute_utils
- 0xFF 参考
-
1. 设计&思路
MirroredStrategy 策略通常用于在一台机器上用多个GPU进行训练。其主要难点就是:如何更新 Mirrored 变量?如何分发计算?本文我们看看其总体思路和如何更新变量。
这里安利两个github,都是非常好的学习资料,推荐。
https://github.com/yuhuiaws/ML-study
https://github.com/Jack47/hack-SysML
另外推荐西门宇少的最新大作让Pipeline在Transformer LM上沿着Token level并行起来——TeraPipe。
本系列其他文章是:
[翻译] TensorFlow 分布式之论文篇 "TensorFlow : Large-Scale Machine Learning on Heterogeneous Distributed Systems"
[翻译] TensorFlow 分布式之论文篇 "Implementation of Control Flow in TensorFlow"
[源码解析] TensorFlow 分布式环境(1) --- 总体架构
[源码解析] TensorFlow 分布式环境(2)---Master 静态逻辑
[源码解析] TensorFlow 分布式环境(3)--- Worker 静态逻辑
[源码解析] TensorFlow 分布式环境(4) --- WorkerCache
[源码解析] TensorFlow 分布式环境(5) --- Session
[源码解析] TensorFlow 分布式环境(7) --- Worker 动态逻辑
[源码解析] TensorFlow 分布式环境(8) --- 通信机制
[翻译] 使用 TensorFlow 进行分布式训练
[源码解析] TensorFlow 分布式 DistributedStrategy 之基础篇
[源码解析] TensorFlow 之 分布式变量
1. 设计&思路
1.1 主要逻辑
MirroredStrategy 是TF的单机多卡同步的数据并行分布式训练策略。
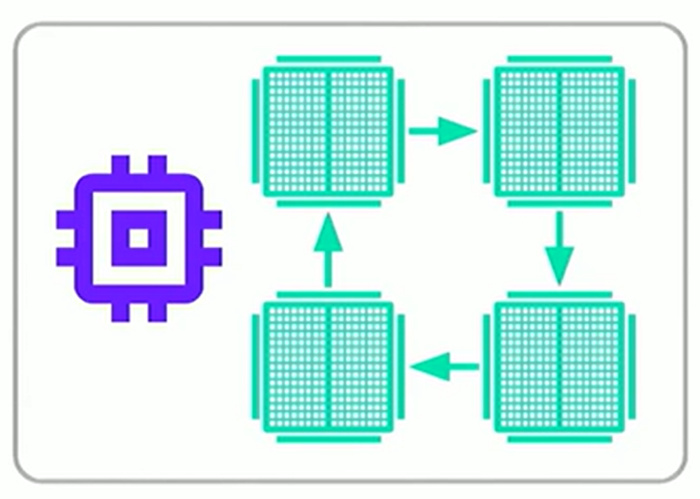
其主要逻辑如下:
- MirroredStrategy 策略自动使用所有能被 TensorFlow 发现的 GPU 来做分布式训练,如果用户只想使用部分 GPU,则需要通过 devices 参数来指定使用哪些设备。
- 在训练开始前,MirroredStrategy 策略把一份完整的模型副本复制到所有 N 个计算设备(GPU)上。模型中的每个变量 (Variables) 都会进行镜像复制,然后被放置到相应的 GPU 上,这些变量就是镜像变量 (MirroredVariable)。
- 数据并行的意义是:工作者会收到 tf.data.Dataset 传来的数据,在训练开始之后,每次传入一个批次数据时,会把数据分成 N 份,这 N 份数据被分别传入 N 个计算设备。
- 同步的意义是:在训练中,每个工作者会在自己获取的输入数据上进行前向计算和反向计算,并且在每个步骤结束时汇总梯度。只有当所有设备均更新本地变量后,才会进行下一轮训练。
- MirroredStrategy 策略通过 AllReduce 算法在每个 GPU 之间对对所有镜像变量保持同步更新, 同步方式是在计算设备间进行高效交换梯度数据,并进行求和,这样最终每个设备都有了所有设备的梯度之和,然后使用梯度求和的结果来更新各个 GPU 的本地变量。AllReduce 算法默认使用 NcclAllReduce ,用户可以通过配置 cross_device_ops 参数来修改为其它 AllReduce 算法(如 HierarchicalCopyAllReduce )。
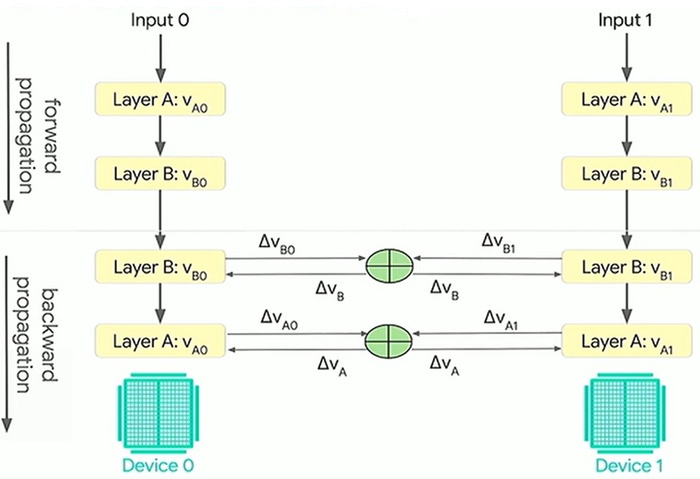
图 1 MirroredStrategy 策略机制
1.2 使用
具体使用代码如下,代码之中夹杂这打印出来运行时候的具体变量。
>>> @tf.function
... def step_fn(var):
...
... def merge_fn(strategy, value, var):
... # All-reduce the value. Note that value here is a
... # tf.distribute.DistributedValues.
... reduced = strategy.extended.batch_reduce_to(
... tf.distribute.ReduceOp.SUM, [(value, var)])[0]
... strategy.extended.update(var, lambda var, value: var.assign(value),
... args=(reduced,))
...
... value = tf.identity(1.)
... tf.distribute.get_replica_context().merge_call(merge_fn,
... args=(value, var))
>>>
>>> def run(strategy):
... with strategy.scope():
... v = tf.Variable(0.)
... strategy.run(step_fn, args=(v,))
... return v
>>>
>>> run(tf.distribute.MirroredStrategy(["GPU:0", "GPU:1"]))
MirroredVariable:{
0: ,
1:
}
>>> run(tf.distribute.experimental.CentralStorageStrategy(
... compute_devices=["GPU:0", "GPU:1"], parameter_device="CPU:0"))
>>> run(tf.distribute.OneDeviceStrategy("GPU:0"))
1.3 分析思路
因为我们之前对PyTorch的数据并行实现DDP有了较为深入的分析,所以我们此处分析重点就是寻找TF和PyTorch的异同。能够想到的问题是:
- 在单机上是多进程还是多线程训练?
- 如何分发模型?(这部分通过MirroredVariable来实现,我们已经在前面章节分析)。
- 如何保持镜像变量 (MirroredVariable) 对外提供一个统一视图?(这部分通过MirroredVariable来实现,我们已经在前面章节分析)。
- 如何使用集合通信操作(库)?
从前面 MirroredVariable 章节我们可以知道,这些变量最终都是使用 Strategy 或者 Extended 进行操作。
2. 定义
2.1 MirroredStrategy
MirroredStrategy 的定义如下啊,主要就是生成了 MirroredExtended。
@tf_export("distribute.MirroredStrategy", v1=[]) # pylint: disable=g-classes-have-attributes
class MirroredStrategy(distribute_lib.Strategy):
"""Synchronous training across multiple replicas on one machine.
"""
def __init__(self, devices=None, cross_device_ops=None):
extended = MirroredExtended(
self, devices=devices, cross_device_ops=cross_device_ops)
super(MirroredStrategy, self).__init__(extended)
distribute_lib.distribution_strategy_gauge.get_cell("V2").set(
"MirroredStrategy")
2.2 MirroredExtended
可以看到其核心变量如下:
- devices:本训练所拥有的设备;
- _collective_ops_in_use :底层的集合通信操作;
class MirroredExtended(distribute_lib.StrategyExtendedV1):
"""Implementation of MirroredStrategy."""
# If this is set to True, use NCCL collective ops instead of NCCL cross device
# ops.
_prefer_collective_ops = False
def __init__(self, container_strategy, devices=None, cross_device_ops=None):
super(MirroredExtended, self).__init__(container_strategy)
if context.executing_eagerly():
if devices and not _is_device_list_single_worker(devices):
raise RuntimeError("In-graph multi-worker training with "
"MirroredStrategy is not supported in eager mode.")
else:
if TFConfigClusterResolver().cluster_spec().as_dict():
# if you are executing in eager mode, only the single machine code
# path is supported.
devices = devices or all_local_devices()
else:
devices = devices or all_devices()
self._cross_device_ops = cross_device_ops
self._collective_ops_in_use = False
self._collective_key_base = container_strategy._collective_key_base
self._initialize_strategy(devices)
self._communication_optiOns= collective_util.Options(
implementation=collective_util.CommunicationImplementation.NCCL)
if ops.executing_eagerly_outside_functions():
self.experimental_enable_get_next_as_optiOnal= True
# Flag to turn on VariablePolicy.
self._use_var_policy = False
3. 初始化
初始化这里分为两种:
- 单个节点。这里会初始化单个节点上的单个 worker,初始化集合通信操作。
- 多个节点。调用 _initialize_multi_worker 来初始化多个节点上的多个 worker。
def _initialize_strategy(self, devices):
# The _initialize_strategy method is intended to be used by distribute
# coordinator as well.
devices = tuple(device_util.resolve(d) for d in devices)
if _is_device_list_single_worker(devices):
self._initialize_single_worker(devices)
self._collective_ops = self._make_collective_ops(devices)
if self._prefer_collective_ops and (
isinstance(self._cross_device_ops, cross_device_ops_lib.NcclAllReduce)
or isinstance(self._inferred_cross_device_ops,
cross_device_ops_lib.NcclAllReduce)):
self._collective_ops_in_use = True
self._inferred_cross_device_ops = None
else:
self._initialize_multi_worker(devices)
具体如何区分节点数目则是由 _is_device_list_single_worker 方法完成。
def _is_device_list_single_worker(devices):
"""Checks whether the devices list is for single or multi-worker.
Args:
devices: a list of device strings or tf.config.LogicalDevice objects, for
either local or for remote devices.
Returns:
a boolean indicating whether these device strings are for local or for
remote.
Raises:
ValueError: if device strings are not consistent.
"""
specs = []
for d in devices:
name = d.name if isinstance(d, context.LogicalDevice) else d
specs.append(tf_device.DeviceSpec.from_string(name))
num_workers = len({(d.job, d.task, d.replica) for d in specs})
all_local = all(d.job in (None, "localhost") for d in specs)
any_local = any(d.job in (None, "localhost") for d in specs)
if any_local and not all_local:
raise ValueError("Local device string cannot have job specified other "
"than 'localhost'")
if num_workers == 1 and not all_local:
if any(d.task is None for d in specs):
raise ValueError("Remote device string must have task specified.")
return num_workers == 1
3.1 初始化多worker
这部分其实是被 MultiWorkerMirroredStrategy 使用,我们这里只是大概介绍一下。
3.1.1 MultiWorkerMirroredStrategy
可以看到,其使用了 CollectiveAllReduceExtended 进行操作。
@tf_export(v1=["distribute.experimental.MultiWorkerMirroredStrategy"]) disable=missing-docstring
class CollectiveAllReduceStrategyV1(distribute_lib.StrategyV1):
# The starting number for collective keys. This should only be set in tests.
_collective_key_base = 0
def __init__(self,
communication=collective_util.CommunicationImplementation.AUTO,
cluster_resolver=None):
"""Initializes the object."""
communication_optiOns= collective_util.Options(
implementation=communication)
super(CollectiveAllReduceStrategyV1, self).__init__(
CollectiveAllReduceExtended(
self,
cluster_resolver=cluster_resolver,
communication_optiOns=communication_options))
distribute_lib.distribution_strategy_gauge.get_cell("V1").set(
"MultiWorkerMirroredStrategy")
distribute_lib.distribution_strategy_replica_gauge.get_cell(
"num_workers").set(self.extended._num_workers)
distribute_lib.distribution_strategy_replica_gauge.get_cell(
"num_gpu_per_worker").set(self.extended._num_gpus_per_worker)
3.1.2 CollectiveAllReduceExtended
CollectiveAllReduceExtended 扩展了 MirroredExtended。
class CollectiveAllReduceExtended(mirrored_strategy.MirroredExtended):
因此,在多节点环境下,就是走的 _initialize_multi_worker 路径。
- 初始化 worker,其实就是字符串;
- 初始化 worker_devices,是一个 tuple;
- _inferred_cross_device_ops 或者由用户指定,或者是 NcclAllReduce。
def _initialize_multi_worker(self, devices):
"""Initializes the object for multi-worker training."""
device_dict = _group_device_list(devices)
workers = []
worker_devices = []
for job in ("chief", "worker"):
for task in range(len(device_dict.get(job, []))):
worker = "/job:%s/task:%d" % (job, task)
workers.append(worker)
worker_devices.append((worker, device_dict[job][task]))
# Setting _default_device will add a device scope in the
# distribution.scope. We set the default device to the first worker. When
# users specify device under distribution.scope by
# with tf.device("/cpu:0"):
# ...
# their ops will end up on the cpu device of its first worker, e.g.
# "/job:worker/task:0/device:CPU:0". Note this is not used in replica mode.
self._default_device = workers[0]
self._host_input_device = numpy_dataset.SingleDevice(workers[0])
self._devices = tuple(devices)
self._input_workers_devices = worker_devices
self._is_multi_worker_training = True
# 如何选择集合操作
if len(workers) > 1:
if (not isinstance(self._cross_device_ops,
cross_device_ops_lib.ReductionToOneDevice) or
self._cross_device_ops._num_between_graph_workers > 1):
raise ValueError(
"In-graph multi-worker training with MirroredStrategy is not "
"supported.")
self._inferred_cross_device_ops = self._cross_device_ops
else:
self._inferred_cross_device_ops = cross_device_ops_lib.NcclAllReduce()
3.2 跨设备操作
上面提到了跨设备如何选择集合操作,我们接下来就先看看这部分,然后再研究单 worker 初始化。
基本上所有的分布式策略都通过某些 collective ops 和 cross device ops 来进行数据通讯,比如 MirroredStrategy 使用 CollectiveOps 来对变量保持同步,而 CollectiveOps 会在 TensorFlow 执行时候自动根据硬件配置,当前网络拓扑以及张量大小来选择合适的 AllReduce 算法。比如,在 tensorflow/core/kernels/collective_ops.cc 之中有如下使用,c 是当前 op 的计算状态, col_exec 是根据系统的具体情况来选择的 collective executor,所有的集合操作,比如 all reduce,boardcast 等操作都由 collective executor 去执行。
void ComputeAsyncImpl(OpKernelContext* c, CollectiveExecutor* col_exec,
DoneCallback done) override {
auto output_shape = c->input(0).shape();
output_shape.set_dim(
0, output_shape.dim_size(0) * col_params_->group.group_size);
col_params_->instance.shape = output_shape;
// Allocate output on the first pass through this function. This must be
// done immediately, while we're still in the executor thread. Otherwise
// the memory is not guaranteed to be unused by any concurrently executing
// GPU kernel.
if (c->mutable_output(0) == nullptr) {
// Allocate the output tensor.
Tensor* output = nullptr;
OP_REQUIRES_OK_ASYNC(
c, c->allocate_output(0, col_params_->instance.shape, &output), done);
}
if (!CanProceedWithCompute(c, col_exec, done)) return;
auto actual_dOne= [c, col_params = col_params_, done](const Status& s) {
col_params->Unref();
OP_REQUIRES_OK_ASYNC(c, s, done);
done();
};
col_params_->Ref();
col_exec->ExecuteAsync(c, col_params_, GetCollectiveKey(c), actual_done);
}
3.2.1 CrossDeviceOps
CrossDeviceOps 是跨设备操作的基类,目前其派生类如下:
- tf.distribute.ReductionToOneDevice。
- tf.distribute.NcclAllReduce。
- tf.distribute.HierarchicalCopyAllReduce。
@tf_export("distribute.CrossDeviceOps")
class CrossDeviceOps(object):
"""Base class for cross-device reduction and broadcasting algorithms.
The main purpose of this class is to be passed to
tf.distribute.MirroredStrategy in order to choose among different cross
device communication implementations. Prefer using the methods of
tf.distribute.Strategy instead of the ones of this class.
Implementations:
* tf.distribute.ReductionToOneDevice
* tf.distribute.NcclAllReduce
* tf.distribute.HierarchicalCopyAllReduce
"""
3.2.2 ReductionToOneDevice
ReductionToOneDevice 将值复制到一个设备上规约它们,然后将规约后的值广播出来,它不支持批处理。
@tf_export("distribute.ReductionToOneDevice")
class ReductionToOneDevice(CrossDeviceOps):
"""A CrossDeviceOps implementation that copies values to one device to reduce.
This implementation always copies values to one device to reduce them, then
broadcast reduced values to the destinations. It doesn't support efficient
batching.
"""
def __init__(self, reduce_to_device=None, accumulation_fn=None):
"""Initializes with a device to reduce to and a way to accumulate.
Args:
reduce_to_device: the intermediate device to reduce to. If None, reduce
to the first device in destinations of the reduce method.
accumulation_fn: a function that does accumulation. If None,
tf.math.add_n is used.
"""
self.reduce_to_device = reduce_to_device
self.accumulation_fn = accumulation_fn or math_ops.add_n
super(ReductionToOneDevice, self).__init__()
def reduce_implementation(self, reduce_op, per_replica_value, destinations,
options):
del options # Unused.
if check_destinations(destinations):
devices = get_devices_from(destinations, self._canonicalize_devices)
else:
devices = get_devices_from(per_replica_value, self._canonicalize_devices)
reduce_to_device = self.reduce_to_device or devices[0]
reduced = _simple_reduce(per_replica_value, reduce_to_device,
self.accumulation_fn, reduce_op)
return self.broadcast(reduced, destinations)
def _gather_implementation(self, per_replica_value, destinations, axis,
options):
del options # Unused.
if check_destinations(destinations):
devices = get_devices_from(destinations, self._canonicalize_devices)
else:
devices = get_devices_from(per_replica_value, self._canonicalize_devices)
reduce_to_device = self.reduce_to_device or devices[0]
gathered = _simple_gather(per_replica_value, reduce_to_device, axis)
return self.broadcast(gathered, destinations)
def batch_reduce_implementation(self, reduce_op, value_destination_pairs,
options):
return [
self.reduce_implementation(
reduce_op, t, destinatiOns=v, optiOns=options)
for t, v in value_destination_pairs
]
这里 _simple_reduce 如下:
def _simple_reduce(per_replica_value, reduce_to_device, accumulation_fn,
reduce_op):
"""Reduces the value by accumulation_fn and reduce_op."""
all_values = per_replica_value.values
count = len(all_values)
with ops.device(reduce_to_device):
with context.device_policy(context.DEVICE_PLACEMENT_SILENT):
reduced = cross_device_utils.aggregate_tensors_or_indexed_slices(
all_values, accumulation_fn)
if reduce_op == reduce_util.ReduceOp.MEAN:
reduced = cross_device_utils.divide_by_n_tensors_or_indexed_slices(
reduced, count)
elif reduce_op != reduce_util.ReduceOp.SUM:
raise ValueError("reduce_op must be Reduce.SUM or Reduce.MEAN.")
return reduced
3.2.3 AllReduceCrossDeviceOps
这是 NcclAllReduce 和 HierarchicalCopyAllReduce 的基类。
class AllReduceCrossDeviceOps(CrossDeviceOps):
"""All-reduce implementation of CrossDeviceOps.
It performs all-reduce when applicable using NCCL or hierarchical copy. For
the batch API, tensors will be repacked or aggregated for more efficient
cross-device transportation.
For reduces that are not all-reduce, it falls back to
tf.distribute.ReductionToOneDevice.
"""
def __init__(self, all_reduce_alg="nccl", num_packs=1):
"""Initializes the object.
Args:
all_reduce_alg: the all-reduce algorithm to use, currently only "nccl" or
"hierarchical_copy" are supported.
num_packs: a non-negative integer. The number of packs to split values
into. If zero, no packing will be done.
"""
self._all_reduce_alg = all_reduce_alg
self._num_packs = num_packs
self._simple_cross_replica_ops = ReductionToOneDevice()
super(AllReduceCrossDeviceOps, self).__init__()
def reduce_implementation(self, reduce_op, per_replica_value, destinations,
options):
del options # Unused.
# To use NCCL or all-reduce, source and destination devices should match,
# and none of the devices should be CPU.
if (_devices_match(per_replica_value, destinations) and
not any("cpu" in d.lower() for d in get_devices_from(destinations))):
return self._batch_all_reduce(reduce_op, [per_replica_value])[0]
else:
return self._simple_cross_replica_ops.reduce(reduce_op, per_replica_value,
destinations)
def batch_reduce_implementation(self, reduce_op, value_destination_pairs,
options):
if _all_devices_match(value_destination_pairs):
return self._batch_all_reduce(reduce_op,
[v[0] for v in value_destination_pairs])
else:
return [
self.reduce_implementation(reduce_op, value, dest, options)
for value, dest in value_destination_pairs
]
def _batch_all_reduce(self, reduce_op, per_replica_values):
"""All-reduce algorithm in a batch."""
dense_values, dense_indices, sparse_values, sparse_indices = (
cross_device_utils.split_by_sparsity(per_replica_values))
if dense_values:
dense_results = self._do_batch_all_reduce(reduce_op, dense_values)
else:
dense_results = []
if sparse_values:
sparse_results = self._do_batch_all_reduce_sparse(reduce_op,
sparse_values)
else:
sparse_results = []
return cross_device_utils.stitch_values(((dense_results, dense_indices),
(sparse_results, sparse_indices)))
def _do_batch_all_reduce(self, reduce_op, dense_values):
"""Run batch all-reduces."""
destinatiOns= dense_values[0]._devices # pylint: disable=protected-access
grouped = _group_value_by_device(dense_values)
# device_grad_packs:
# [[(t0_gpu0, None), (t1_gpu0, None)], [(t0_gpu1, None), (t1_gpu1, None)]]
device_grad_packs, tensor_packer = _pack_tensors(grouped, self._num_packs)
# The actual aggregation of the repacked gradients. Note that they are
# sharded among different aggregation trees. So it is important to strike
# the balance on num_splits.
if self._all_reduce_alg == "nccl":
reduced = cross_device_utils.aggregate_gradients_using_nccl(
device_grad_packs)
else:
reduced = (
cross_device_utils.aggregate_gradients_using_hierarchical_copy(
destinations, device_grad_packs))
reduced = _unpack_tensors(reduced, tensor_packer)
return _ungroup_and_make_mirrored(reduced, dense_values[0], reduce_op)
def _do_batch_all_reduce_sparse(self, reduce_op, sparse_values):
"""Run batch all-reduce for sparse values."""
# Use sparse_values as destinations to do all-reduces. It is effectively
# an allgather under the hood but not an efficient one.
return self._simple_cross_replica_ops.batch_reduce(
reduce_op, zip(sparse_values, sparse_values))
def _gather_implementation(self, per_replica_value, destinations, axis,
options):
return ReductionToOneDevice()._gather(per_replica_value, destinations, axis, # pylint: disable=protected-access
options)
3.2.4 NcclAllReduce
NcclAllReduce 方法会使用 Nccl 进行AllReduce。
@tf_export("distribute.NcclAllReduce")
class NcclAllReduce(AllReduceCrossDeviceOps):
"""NCCL all-reduce implementation of CrossDeviceOps.
It uses Nvidia NCCL for all-reduce. For the batch API, tensors will be
repacked or aggregated for more efficient cross-device transportation.
For reduces that are not all-reduce, it falls back to
tf.distribute.ReductionToOneDevice.
"""
def __init__(self, num_packs=1):
"""Initializes the object.
Args:
num_packs: a non-negative integer. The number of packs to split values
into. If zero, no packing will be done.
Raises:
ValueError: if num_packs is negative.
"""
if num_packs <0:
raise ValueError(
"NCCL all-reduce requires num_packs >= 0, but {} is specified".format(
num_packs))
super(NcclAllReduce, self).__init__(
all_reduce_alg="nccl", num_packs=num_packs)
3.2.5 HierarchicalCopyAllReduce
HierarchicalCopyAllReduce 使用 Hierarchical 算法进行AllReduce。它把数据沿着一些 hierarchy 的边规约到某一个GPU,并沿着同一路径广播回每个GPU。对于批处理API,张量将被重新打包或聚合,以便更有效地跨设备运输。这是为 Nvidia DGX-1 创建的规约操作,它假设 GPU 在 DGX-1 机器上是 Hierarchical 连接的。如果你有不同的 GPU 相互连接,它可能会比 tf.distribution.ReductionToOneDevice更慢。
@tf_export("distribute.HierarchicalCopyAllReduce")
class HierarchicalCopyAllReduce(AllReduceCrossDeviceOps):
"""Hierarchical copy all-reduce implementation of CrossDeviceOps.
It reduces to one GPU along edges in some hierarchy and broadcasts back to
each GPU along the same path. For the batch API, tensors will be repacked or
aggregated for more efficient cross-device transportation.
This is a reduction created for Nvidia DGX-1 which assumes GPUs connects like
that on DGX-1 machine. If you have different GPU inter-connections, it is
likely that it would be slower than tf.distribute.ReductionToOneDevice.
For reduces that are not all-reduce, it falls back to
tf.distribute.ReductionToOneDevice.
"""
def __init__(self, num_packs=1):
"""Initializes the object.
Args:
num_packs: a non-negative integer. The number of packs to split values
into. If zero, no packing will be done.
Raises:
ValueError if num_packs is negative.
"""
super(HierarchicalCopyAllReduce, self).__init__(
all_reduce_alg="hierarchical_copy",
num_packs=num_packs)
3.2.6 CollectiveAllReduce
CollectiveAllReduce 使用集合通信进行 AllReduce,是 PyTorch 自己实现的算法。
class CollectiveAllReduce(CrossDeviceOps):
"""All-reduce cross device ops using collective ops.
In the between-graph replicated training, it will still do all-reduces across
all workers and then put results on the right destinations.
"""
def __init__(self,
devices,
group_size,
collective_keys=None,
canonicalize_devices=True):
"""Initializes the object.
Args:
devices: a list of device strings to run collectives on.
group_size: the global group size. For between-graph replicated training
it's the total number of devices across all workers.
collective_keys: an optional CollectiveKey object.
canonicalize_devices: Whether to canonicalize devices for workers or not.
"""
if group_size % len(devices) > 0:
raise ValueError("group_size must be divisible by the number of devices.")
self._group_size = group_size
self._collective_keys = (collective_keys or
cross_device_utils.CollectiveKeys())
# This lock guards all collective launches, i.e. calls to
# cross_device_utils.build_collectve_*.
#
# In a multi threaded eager program we need to ensure different groups of
# collectives don't interleave each other, otherwise there could be
# deadlocks. E.g. if two user threads both are launching collectives:
# user-thread-0 device0 device1
# user-thread-1 device0 device1
# In eager mode, we use one thread per device to launch collective ops, so
# the above launch sequences end up with the following queues:
# device-0 collective-0 collective-1
# device-1 collective-1 collective-0
# This deadlocks since neither collective is able to finish.
self._lock = threading.Lock()
if canonicalize_devices:
self._devices = tuple(device_util.canonicalize(d) for d in devices)
else:
self._devices = tuple(
device_util.canonicalize_without_job_and_task(d) for d in devices)
group_key = self._collective_keys.get_group_key(self._devices)
self._launchers = []
# Whether to only use NCCL for batched all-reduce when NCCL is requested.
# This is because of the lack of mechanism to order NCCL operations
# deterministically.
self._limited_nccl = False
for device in self._devices:
launcher = cross_device_utils.CollectiveReplicaLauncher(
group_key, group_size, self._collective_keys, device)
self._launchers.append(launcher)
if not launcher.can_order_nccl():
self._limited_nccl = True
self._pool = multiprocessing.pool.ThreadPool(len(self._devices))
super(CollectiveAllReduce, self).__init__()
self._canonicalize_devices = canonicalize_devices
@property
def _num_between_graph_workers(self):
# Currently we only support equal number of devices on each worker.
return self._group_size / len(self._devices)
def _all_reduce(self, reduce_op, value, replica_id, options):
"""Implements CrossDeviceOps.all_reduce."""
flat_values = nest.flatten(value)
implementation = options.implementation.value
# If NCCL launches can't be ordered (self._limited_nccl == True), we only
# use NCCL when batch_size > 1, hoping that there's only one batched
# all-reduce, which is the gradient aggregation in optimizer. For TF 2.x,
# NCCL launches are always ordered.
if (self._limited_nccl and
options.implementation == CommunicationImplementation.NCCL and
len(flat_values) == 1):
implementation = CommunicationImplementation.AUTO.value
launcher = self._launchers[replica_id]
dense_values, dense_indices, sparse_values, sparse_indices = (
cross_device_utils.split_by_sparsity(flat_values))
dense_results = []
sparse_results = []
if dense_values:
# Reverse the lists so that there's better chance that values follows
# the order in which they are calculated (e.g. when they're gradients), so
# as to overlap calculation with communication. However, this may not be
# optimal for cases like gradients of complicated non-sequential models.
#
# Note that we reverse the list before packing so that the first pack
# won't be too small, since it's more likely for first few packs to have
# long queuing time due to concurrent intense computation.
#
# TODO(b/147393503): explore solutions for optimal ordering.
dense_values.reverse()
packs = cross_device_utils.group_by_size(dense_values,
options.bytes_per_pack)
dense_results = launcher.batch_all_reduce(packs, implementation,
options.timeout_seconds)
if reduce_op == reduce_util.ReduceOp.MEAN:
for i, v in enumerate(dense_results):
with ops.device(self._devices[replica_id]):
dense_results[i] = v / self._group_size
dense_results.reverse()
if sparse_values:
for indexed_slice in sparse_values:
sparse_results.append(
launcher.all_reduce_indexed_slices(indexed_slice, implementation,
options.timeout_seconds))
if reduce_op == reduce_util.ReduceOp.MEAN:
for i, v in enumerate(sparse_results):
with ops.device(self._devices[replica_id]):
sparse_results[i] = ops.IndexedSlices(
values=sparse_results[i].values / self._group_size,
indices=sparse_results[i].indices,
dense_shape=sparse_results[i].dense_shape)
flat_results = cross_device_utils.stitch_values(
((dense_results, dense_indices), (sparse_results, sparse_indices)))
return nest.pack_sequence_as(value, flat_results)
def _all_reduce_per_replica_values(self, reduce_op, per_replica_values,
options):
"""All reduce a list of per_replica_value."""
values_by_device = [[] for _ in self._devices]
num_devices = len(self._devices)
for per_replica in per_replica_values:
for i in range(num_devices):
values_by_device[i].append(per_replica.values[i])
if context.executing_eagerly():
def thread_fn(device_id):
with context.eager_mode():
return self._all_reduce(reduce_op, values_by_device[device_id],
device_id, options)
with self._lock:
outputs_by_device = self._pool.map(thread_fn, list(range(num_devices)))
else:
outputs_by_device = []
with self._lock:
for i in range(num_devices):
outputs_by_device.append(
self._all_reduce(reduce_op, values_by_device[i], i, options))
result = []
for values in zip(*outputs_by_device):
result.append(
distribute_utils.regroup(values, wrap_class=value_lib.Mirrored))
return result
def reduce_implementation(self, reduce_op, per_replica_value, destinations,
options):
values_util.mark_as_unsaveable()
all_reduced = self._all_reduce_per_replica_values(reduce_op,
[per_replica_value],
options)[0]
devices = get_devices_from(destinations, self._canonicalize_devices)
if _devices_match(per_replica_value, destinations,
self._canonicalize_devices):
return all_reduced
# Convert all_reduced to a Mirrored object, as a simple and uniform
# utility to access component for a particular device.
if not isinstance(all_reduced, value_lib.Mirrored):
all_reduced = value_lib.Mirrored([all_reduced])
# If we got this far, the destination devices do not match the all-reduce
# devices, so we must map from one to the other.
index = []
# We must add these control dependencies, otherwise we can get deadlock.
with ops.control_dependencies(all_reduced.values):
for d in devices:
with ops.device(d):
for v in all_reduced.values:
if v.device == d:
index.append(array_ops.identity(v))
break
else:
index.append(array_ops.identity(all_reduced._primary)) # pylint: disable=protected-access
return distribute_utils.regroup(index, wrap_class=value_lib.Mirrored)
def batch_reduce_implementation(self, reduce_op, value_destination_pairs,
options):
values_util.mark_as_unsaveable()
all_devices_match = _all_devices_match(value_destination_pairs,
self._canonicalize_devices)
if all_devices_match:
return self._all_reduce_per_replica_values(
reduce_op, [v[0] for v in value_destination_pairs], options)
else:
return [
self.reduce_implementation(reduce_op, value, dest, options)
for value, dest in value_destination_pairs
]
def _gather_implementation(self, per_replica_value, destinations, axis,
options):
all_gathered = self._batch_all_gather([per_replica_value], axis, options)[0]
values_util.mark_as_unsaveable()
devices = get_devices_from(destinations, self._canonicalize_devices)
if _devices_match(per_replica_value, destinations,
self._canonicalize_devices):
return all_gathered
# Convert all_gathered to a Mirrored object, as a simple and uniform
# utility to access component for a particular device.
if not isinstance(all_gathered, value_lib.Mirrored):
all_gathered = value_lib.Mirrored([all_gathered])
# If we got this far, the destination devices do not match the all-gather
# devices, so we must map from one to the other.
index = []
# We must add these control dependencies, otherwise we can get deadlock.
with ops.control_dependencies(all_gathered.values):
for d in devices:
with ops.device(d):
for v in all_gathered.values:
if v.device == d:
index.append(array_ops.identity(v))
break
else:
index.append(array_ops.identity(all_gathered._primary)) # pylint: disable=protected-access
return distribute_utils.regroup(index, wrap_class=value_lib.Mirrored)
def _batch_all_gather(self, per_replica_values, axis, options):
"""all gather multiple per-replica-values."""
batch_size = len(per_replica_values)
# Pass options.implementation to the runtime as a communication
# implementation hint.
implementation = options.implementation.value
# For now, we use NCCL only when batch_size > 1.
# TODO(b/132575814): switch to NCCL for all collectives when implementation
# is NCCL.
if (options.implementation == CommunicationImplementation.NCCL and
batch_size == 1):
implementation = CommunicationImplementation.AUTO.value
def compute_gathered_values():
gathered_values = []
with self._lock, ops.name_scope("allgather"):
for per_replica in per_replica_values:
outputs = []
for i in range(len(self._devices)):
outputs.append(self._launchers[i].all_gather(
per_replica.values[i], axis, implementation,
options.timeout_seconds))
gathered_values.append(outputs)
return gathered_values
if context.executing_eagerly():
gathered_values = def_function.function(compute_gathered_values)()
else:
gathered_values = compute_gathered_values()
mirrored = []
for value in gathered_values:
mirrored.append(
distribute_utils.regroup(value, wrap_class=value_lib.Mirrored))
return mirrored
目前具体逻辑如下,可以看到有众多实现方式,如何选择就需要具体情况具体分析:
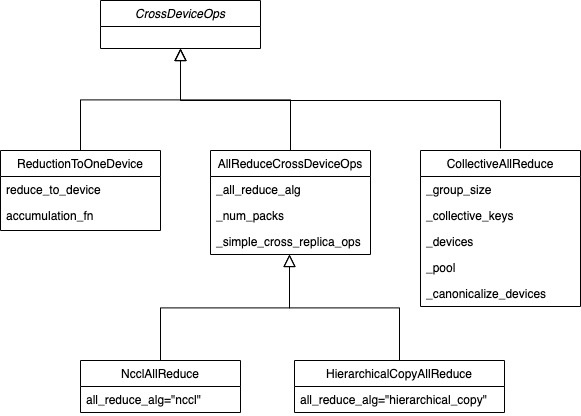
图 2 跨设备操作
3.3 单节点初始化
我们这里重点还是研究单节点初始化,具体代码如下,可以看到主要就是:
- 初始化单个worker;
- 通过 _make_collective_ops 来建立集合操作;
if _is_device_list_single_worker(devices):
self._initialize_single_worker(devices)
self._collective_ops = self._make_collective_ops(devices) # 建立集合操作
if self._prefer_collective_ops and (
isinstance(self._cross_device_ops, cross_device_ops_lib.NcclAllReduce)
or isinstance(self._inferred_cross_device_ops,
cross_device_ops_lib.NcclAllReduce)):
self._collective_ops_in_use = True
self._inferred_cross_device_ops = None
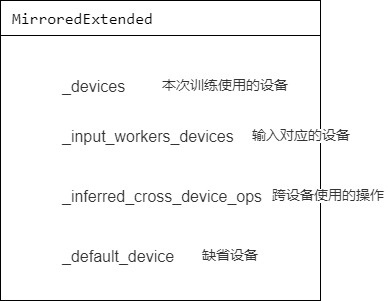
3.3.1 初始化单worker
此部分重点逻辑如下:
- 首先拿到本次训练使用的设备 _devices ,大致为:('/replica:0/task:0/device:GPU:0', '/replica:0/task:0/device:GPU:1')。
- 然后得到输入对应的设备 _input_workers_devices,大致为:('/replica:0/task:0/device:CPU:0': 0, '/replica:0/task:0/device:GPU:0', '/replica:0/task:0/device:GPU:1'),这个后续会被用来建立 InputWorkers。
- 得到 _inferred_cross_device_ops,就是跨设备使用的操作(这是依据已有条件推理出来的)。
- 得到 _default_device,就是缺省设备,这里会设置其 spec。DeviceSpec 被用来描述状态存储和计算发生的位置。使用 "DeviceSpec" 可以解析设备规格字符串以验证其有效性,然后合并它们或以编程方式组合它们。
def _initialize_single_worker(self, devices):
"""Initializes the object for single-worker training."""
self._devices = tuple(device_util.canonicalize(d) for d in devices)
self._input_workers_devices = (
(device_util.canonicalize("/device:CPU:0", devices[0]), devices),)
self._inferred_cross_device_ops = None if self._cross_device_ops else (
cross_device_ops_lib.select_cross_device_ops(devices)) # 推理出跨设备操作
self._host_input_device = numpy_dataset.SingleDevice(
self._input_workers_devices[0][0])
self._is_multi_worker_training = False
device_spec = tf_device.DeviceSpec.from_string(
self._input_workers_devices[0][0])
# Ensures when we enter strategy.scope() we use the correct default device
if device_spec.job is not None and device_spec.job != "localhost":
self._default_device = "/job:%s/replica:%d/task:%d" % (
device_spec.job, device_spec.replica, device_spec.task)
具体如何推理出跨设备操作?是通过 select_cross_device_ops 完成的。
def select_cross_device_ops(devices, session_cOnfig=None):
"""Find the best CrossDeviceOps locally given a tf.compat.v1.ConfigProto.
Args:
devices: a list of devices passed to tf.distribute.Strategy.
session_config: a tf.compat.v1.ConfigProto or None. If None, it will
make decision based on all logical devices.
Returns:
A subclass of CrossDeviceOps.
"""
requested_devices = set(device_util.canonicalize(d) for d in devices)
if ops.executing_eagerly_outside_functions():
logical_gpus = context.context().list_logical_devices(device_type="GPU")
physical_gpus = context.context().list_physical_devices(device_type="GPU")
if len(logical_gpus) != len(physical_gpus):
return ReductionToOneDevice()
machine_devices = context.context().list_logical_devices()
else:
machine_devices = device_lib.list_local_devices(
session_cOnfig=session_config)
using_devices = set()
for d in machine_devices:
if device_util.canonicalize(d.name) in requested_devices:
using_devices.add(d.name)
if any("gpu" not in d.lower() for d in requested_devices):
return ReductionToOneDevice()
if kernels.get_registered_kernels_for_op("NcclAllReduce"):
return NcclAllReduce(num_packs=1)
else:
return ReductionToOneDevice()
3.3.2 建立集合操作
_make_collective_ops 方法用来获取集合操作。
def _make_collective_ops(self, devices):
self._collective_keys = cross_device_utils.CollectiveKeys(
group_key_start=1 + self._collective_key_base)
return cross_device_ops_lib.CollectiveAllReduce(
devices=self._devices,
group_size=len(self._devices),
collective_keys=self._collective_keys)
CollectiveAllReduce 是使用集合通信来完成跨设备的All-reduce。
3.3.3 如何区分
目前有三个集合通信相关的成员变量,我们需要梳理一下。
- self._collective_ops :这是集合操作,实际上配置的是 CollectiveAllReduce。
- self._inferred_cross_device_ops :根据设备情况推理出来的跨设备操作,实际上是 ReductionToOneDevice 或者 NcclAllReduce。
- self._cross_device_ops :传入的配置参数。如果用户想重写跨设备通信,可以通过使用 cross_device_ops 参数来提供tf.distribute.CrossDeviceOps的实例。比如:mirrored_strategy = tf.distribute.MirroredStrategy(cross_device_ops=tf.distribute.HierarchicalCopyAllReduce())。目前,除了默认选项 tf.distribute.NcclAllReduce外,还有 tf.distribute.HierarchicalCopyAllReduce 和 tf.distribute.ReductionToOneDevice 两个选项。
我们看看这三个成员变量的具体用法。比如,_batch_reduce_to 会用到 _get_cross_device_ops。
def _batch_reduce_to(self, reduce_op, value_destination_pairs, options):
cross_device_ops = None
for value, _ in value_destination_pairs:
if cross_device_ops is None:
cross_device_ops = self._get_cross_device_ops(value) # 这里用到
elif cross_device_ops is not self._get_cross_device_ops(value):
raise ValueError("inputs to batch_reduce_to must be either all on the "
"the host or all on the compute devices")
return cross_device_ops.batch_reduce(
reduce_op,
value_destination_pairs,
optiOns=self._communication_options.merge(options))
_get_cross_device_ops 会依据不同配置和情况来选择具体采用哪一种集合操作。
def _use_merge_call(self):
# We currently only disable merge_call when XLA is used to compile the fn
# passed to strategy.run and all devices are GPU.
return not control_flow_util.GraphOrParentsInXlaContext(
ops.get_default_graph()) or not all(
[_is_gpu_device(d) for d in self._devices])
def _get_cross_device_ops(self, value):
if not self._use_merge_call():
return self._collective_ops
# 如果设置了 _prefer_collective_ops,并且其他两个成员变量有一个是NcclAllReduce,则设置 _collective_ops_in_use。
if self._collective_ops_in_use:
if isinstance(value, values.DistributedValues):
value_int32 = True in {
dtypes.as_dtype(v.dtype) == dtypes.int32 for v in value.values
}
else:
value_int32 = dtypes.as_dtype(value.dtype) == dtypes.int32
if value_int32:
return cross_device_ops_lib.ReductionToOneDevice()
else:
return self._collective_ops
return self._cross_device_ops or self._inferred_cross_device_ops
具体逻辑如下:
4. 更新分布式变量
我们接下来看看如何更新分布式变量,因为篇幅原因,这里分析的目的只是大致把流程走通,如果有兴趣的读者可以继续深入研究。
4.1 样例
分布式变量是在多个设备上创建的变量,Mirrored variable和 SyncOnRead variable 是两个例子。一个操作分布式变量的代码如下,首先调用 reduce_to,然后调用 update。
>>> @tf.function
... def step_fn(var):
...
... def merge_fn(strategy, value, var):
... # All-reduce the value. Note that value here is a
... # tf.distribute.DistributedValues.
... reduced = strategy.extended.reduce_to(tf.distribute.ReduceOp.SUM,
... value, destinatiOns=var)
... strategy.extended.update(var, lambda var, value: var.assign(value),
... args=(reduced,))
...
... value = tf.identity(1.)
... tf.distribute.get_replica_context().merge_call(merge_fn,
... args=(value, var))
>>>
>>> def run(strategy):
... with strategy.scope():
... v = tf.Variable(0.)
... strategy.run(step_fn, args=(v,))
... return v
>>>
>>> run(tf.distribute.MirroredStrategy(["GPU:0", "GPU:1"]))
MirroredVariable:{
0: ,
1:
}
>>> run(tf.distribute.experimental.CentralStorageStrategy(
... compute_devices=["GPU:0", "GPU:1"], parameter_device="CPU:0"))
>>> run(tf.distribute.OneDeviceStrategy("GPU:0"))
4.2 规约
我们首先看看 reduce_to 操作。
StrategyExtendedV2
代码首先来到 StrategyExtendedV2。reduce_to 聚合了 tf.distribution.DistributedValues 和分布式变量。它同时支持 dense values 和tf.IndexedSlices。这个 API 目前只能在跨副本背景下调用(cross-replica)。其他用于跨副本规约的变体是。
- tf.distribution.StrategyExtended.batch_reduce_to:批量版本 API。
- tf.distribution.ReplicaContext.all_reduce:在副本上下文中的对应 API 版本。它同时支持批处理和非批处理的 all-reduce。
- tf.distribution.Strategy.reduce:在跨副本上下文中的规约到主机的 API,使用起来更加便捷。
Destinations 指定将数值规约到哪里,例如 "GPU:0"。你也可以传入一个张量,这样规约目的地将是该张量的设备。对于 all-reduce 需要传递相同类型的 value 和 destinations。
def reduce_to(self, reduce_op, value, destinations, optiOns=None):
"""Combine (via e.g. sum or mean) values across replicas.
reduce_to aggregates tf.distribute.DistributedValues and distributed
variables. It supports both dense values and tf.IndexedSlices.
This API currently can only be called in cross-replica context. Other
variants to reduce values across replicas are:
* tf.distribute.StrategyExtended.batch_reduce_to: the batch version of
this API.
* tf.distribute.ReplicaContext.all_reduce: the counterpart of this API
in replica context. It supports both batched and non-batched all-reduce.
* tf.distribute.Strategy.reduce: a more convenient method to reduce
to the host in cross-replica context.
destinations specifies where to reduce the value to, e.g. "GPU:0". You can
also pass in a Tensor, and the destinations will be the device of that
tensor. For all-reduce, pass the same to value and destinations.
It can be used in tf.distribute.ReplicaContext.merge_call to write code
that works for all tf.distribute.Strategy.
Args:
reduce_op: a tf.distribute.ReduceOp value specifying how values should
be combined. Allows using string representation of the enum such as
"SUM", "MEAN".
value: a tf.distribute.DistributedValues, or a tf.Tensor like object.
destinations: a tf.distribute.DistributedValues, a tf.Variable, a
tf.Tensor alike object, or a device string. It specifies the devices
to reduce to. To perform an all-reduce, pass the same to value and
destinations. Note that if it's a tf.Variable, the value is reduced
to the devices of that variable, and this method doesn't update the
variable.
options: a tf.distribute.experimental.CommunicationOptions. Options to
perform collective operations. This overrides the default options if the
tf.distribute.Strategy takes one in the constructor. See
tf.distribute.experimental.CommunicationOptions for details of the
options.
Returns:
A tensor or value reduced to destinations.
"""
if options is None:
optiOns= collective_util.Options()
_require_cross_replica_or_default_context_extended(self)
if isinstance(reduce_op, six.string_types):
reduce_op = reduce_util.ReduceOp(reduce_op.upper())
return self._reduce_to(reduce_op, value, destinations, options)
MirroredExtended
这里有几种执行流程,比如使用 _get_cross_device_ops 来得到集合通信函数。
def _reduce_to(self, reduce_op, value, destinations, options):
if (distribute_utils.is_mirrored(value) and
reduce_op == reduce_util.ReduceOp.MEAN):
return value
def get_values(value):
if not isinstance(value, values.DistributedValues):
# This function handles reducing values that are not PerReplica or
# Mirrored values. For example, the same value could be present on all
# replicas in which case value would be a single value or value could
# be 0.
return cross_device_ops_lib.reduce_non_distributed_value(
reduce_op, value, destinations, self._num_replicas_in_sync)
if self._use_merge_call() and self._collective_ops_in_use and ((
not cross_device_ops_lib._devices_match(value, destinations) or
any("cpu" in d.lower()
for d in cross_device_ops_lib.get_devices_from(destinations)))):
return cross_device_ops_lib.ReductionToOneDevice().reduce(
reduce_op, value, destinations)
return self._get_cross_device_ops(value).reduce(
reduce_op,
value,
destinatiOns=destinations,
optiOns=self._communication_options.merge(options))
return nest.map_structure(get_values, value)
4.3 更新
我们其次看看 update 操作。
StrategyExtendedV2
Update 运行fn 使用 input 来更新 var,镜像到相同设备的输入。tf.distribution.StrategyExtended.update 接收一个要更新的分布式变量 var,一个更新函数 fn,以及用于 fn 的 args 和 kwargs。然后从 args 和 kwargs 传递相应的值,将 fn 应用于 var 的每个组件变量。
Args 和 kwargs 都不能包含 per-replica values。如果它们包含 mirrored values,则在调用fn之前,它们将被解包(unwrapped)。例如,fn 可以是 assign_add,args 可以是一个镜像(mirrored)的 DistributedValues,DistributedValues 中每个组件都包含要被添加到这个镜像变量 var 的值。调用 update 将使用在设备上相关张量来在 var 的每个组件变量上调用 assign_add。
def update(self, var, fn, args=(), kwargs=None, group=True):
"""Run fn to update var using inputs mirrored to the same devices.
tf.distribute.StrategyExtended.update takes a distributed variable var
to be updated, an update function fn, and args and kwargs for fn. It
applies fn to each component variable of var and passes corresponding
values from args and kwargs. Neither args nor kwargs may contain
per-replica values. If they contain mirrored values, they will be unwrapped
before calling fn. For example, fn can be assign_add and args can be
a mirrored DistributedValues where each component contains the value to be
added to this mirrored variable var. Calling update will call
assign_add on each component variable of var with the corresponding
tensor value on that device.
Example usage:
```python
strategy = tf.distribute.MirroredStrategy(['GPU:0', 'GPU:1']) # With 2
devices
with strategy.scope():
v = tf.Variable(5.0, aggregation=tf.VariableAggregation.SUM)
def update_fn(v):
return v.assign(1.0)
result = strategy.extended.update(v, update_fn)
# result is
# Mirrored:{
# 0: tf.Tensor(1.0, shape=(), dtype=float32),
# 1: tf.Tensor(1.0, shape=(), dtype=float32)
# }
```
If var is mirrored across multiple devices, then this method implements
logic as following:
```python
results = {}
for device, v in var:
with tf.device(device):
# args and kwargs will be unwrapped if they are mirrored.
results[device] = fn(v, *args, **kwargs)
return merged(results)
```
Otherwise, this method returns fn(var, *args, **kwargs) colocated with
var.
Args:
var: Variable, possibly mirrored to multiple devices, to operate on.
fn: Function to call. Should take the variable as the first argument.
args: Tuple or list. Additional positional arguments to pass to fn().
kwargs: Dict with keyword arguments to pass to fn().
group: Boolean. Defaults to True. If False, the return value will be
unwrapped.
Returns:
By default, the merged return value of fn across all replicas. The
merged result has dependencies to make sure that if it is evaluated at
all, the side effects (updates) will happen on every replica. If instead
"group=False" is specified, this function will return a nest of lists
where each list has an element per replica, and the caller is responsible
for ensuring all elements are executed.
"""
if kwargs is None:
kwargs = {}
replica_cOntext= distribution_strategy_context.get_replica_context()
if (replica_context is None or replica_context is
distribution_strategy_context._get_default_replica_context()):
fn = autograph.tf_convert(
fn, autograph_ctx.control_status_ctx(), convert_by_default=False)
with self._container_strategy().scope():
return self._update(var, fn, args, kwargs, group) # 调用到派生类
else:
return self._replica_ctx_update(
var, fn, args=args, kwargs=kwargs, group=group)
MirroredExtended
MirroredExtended 会把更新组合成列表,调用 fn 完成取值,然后调用 distribute_utils.update_regroup 完成 regroup 操作。
def _update(self, var, fn, args, kwargs, group):
assert isinstance(var, values.DistributedVariable)
updates = []
for i, v in enumerate(var.values): # 遍历 var 的 component
name = "update_%d" % i
with ops.device(v.device), \
distribute_lib.UpdateContext(i), \
ops.name_scope(name):
# If args and kwargs are not mirrored, the value is returned as is.
updates.append(
fn(v, *distribute_utils.select_replica(i, args),
**distribute_utils.select_replica(i, kwargs)))
return distribute_utils.update_regroup(self, updates, group)
distribute_utils
distribute_utils.update_regroup 会完成 regroup 操作,限于篇幅这里不做深入,有兴趣读者可以自行研究。
def update_regroup(extended, updates, group):
"""Regroup for an update, with dependencies to ensure all updates execute."""
if not group:
regrouped = regroup(updates, values_lib.Mirrored)
return nest.map_structure(extended._local_results, regrouped)
def _make_grouped_mirrored(values):
"""Convert per-replica list values into Mirrored type with grouping."""
if len(values) == 1:
return values_lib.Mirrored(values)
# Make sure we run all updates. Without this, something like
# session.run(extended.update(...)) may only update one replica.
g = control_flow_ops.group(values)
# If values is just ops, the grouping is enough. Everything in values
# should have the same type, since we expect every replica to be performing
# the same computation.
if not all(tensor_util.is_tf_type(v) for v in values):
return g
# Otherwise we need tensors with the same values as values, but
# that have a dependency on g.
with_dep = []
for v in values:
with ops.device(v.device), ops.control_dependencies([g]):
with_dep.append(array_ops.identity(v))
return values_lib.Mirrored(with_dep)
return regroup(updates, _make_grouped_mirrored)
逻辑如下:
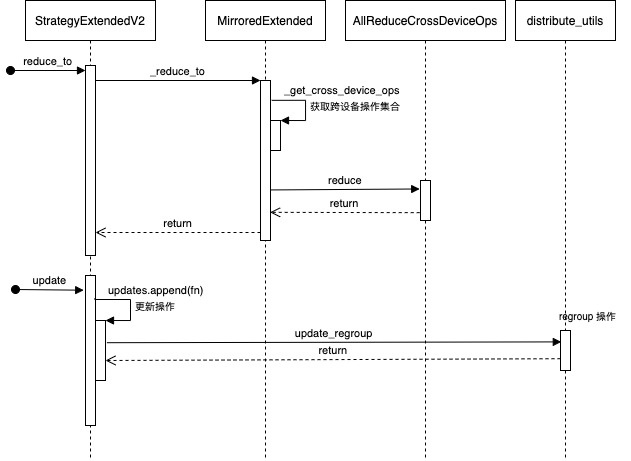
图 更新操作
0xFF 参考
tensorflow源码解析之distributed_runtime
TensorFlow分布式训练
- TensorFlow内核剖析
- 源代码
Tensorflow分布式原理理解
TensorFlow架构与设计:概述
Tensorflow 跨设备通信
TensorFlow 篇 | TensorFlow 2.x 分布式训练概览









 京公网安备 11010802041100号
京公网安备 11010802041100号