在本文中,我们分解了 10 种至少支持某些 SQL 语法的 AWS 服务,讨论它们的用例,并举例说明如何编写查询。
Amazon Web Services (AWS) 是世界上最大的云平台,拥有 200 多项功能 。 在本文中,我们分解了 10 种至少支持某些 SQL 语法的 AWS 服务,讨论它们的用例,并举例说明如何编写查询。
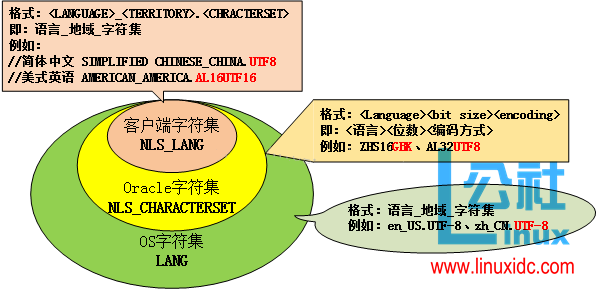
服务 描述 SQL 支持 用例 RDS Postgres、MySQL 等 满的 中小型网络应用 Aurora 无服务器数据库 满的 无服务器应用 Redshift 数据仓库 满的 OLAP、PB 级数据、分析 DynamoDB NoSQL 数据库 一些 - PartiSQL 电子商务,快速构建 Keyspaces 托管 Cassandra(键值) 一些 - CQL 消息传递 Neptune 图数据库 一些 - openCypher 社交网络 Timestream 时间序列数据库 部分的 物联网、日志记录 Quantum Ledger 加密验证交易 一些 - PartiSQL 金融 Athena S3 上的即席查询 一些 - CTAS 历史数据 Babelfish Aurora 上的 MSFT SQL Server 满的 。网
上表显示了服务之间的 SQL 支持如何变化。 图形数据库不能像经典关系数据库那样被查询,各种 SQL 子集,如 PartiQL ,已经出现以适应这些模型。 事实上,即使在标准 SQL 中,也有许多 SQL 方言 适用于不同的公司,如 Oracle 和 Microsoft。
AWS 数据库服务 从 关系到图表到分类账 到时间序列,下面的服务几乎涵盖了所有可以想象的托管数据库用例。 让我们检查一下它们的用途以及如何针对它们编写 SQL 查询!
RDS Amazon RDS 是最基本的 AWS 数据库服务之一,主要用于将您的数据库管理操作卸载到平台上。 因此,它用于数据量有限的中小型企业,并且公司运营所需的功能不是太复杂。
Amazon RDS 支持 MySQL 、MariaDB、 PostgreSQL 、Oracle 和 Microsoft SQL Server 等数据库引擎。 它配备了 使用 SSH 保护您的 RDS 实例 的工作流程,并提供了一个简单的 云控制台用于连接 。
好处 Amazon RDS 是最便宜的服务,因为它易于使用且不复杂。 它具有高度可扩展性,允许您扩展到 32 个 vCPU 和 244 Gb RAM。 该服务也易于使用且速度非常快。 示例 SQL RDS 只是围绕核心数据库的一些不错的管理选项,因此它支持每个数据库支持的确切 SQL。 这是一个 可以针对 Postgres、MySQL 或 Oracle 运行的 子查询。
SELECT
AWS 极光 Amazon Aurora 是 Amazon RDS 的升级版本。 大型企业使用它,因为它们的数据量和操作复杂性要高得多。 它不支持与 Amazon RDS 相同的所有数据库引擎,而是仅支持 MySQL 和 PostgreSQL。 Aurora 会随着数据库负载的增加和减少而向上和向下扩展。 PlanetScale等较新的提供商 也提供此功能 ,具有额外的架构迁移功能和更低的成本。
Amazon Aurora 与 RDS 一样,可以执行复制。 它实际上提供 了大约 15 种不同类型的复制 ,一个复制可以在几毫秒内完成。 另一方面,RDS 只能执行五种类型的复制,需要更多时间。
可以描述 Amazon Aurora 实力的一些用例是企业应用程序、SaaS 应用程序和 Web/移动游戏。
好处 自动缩放允许在不影响数据库性能的情况下自动执行缩放操作。 它允许每个数据库实例最多 128 TB。 Aurora 备份操作是自动的、连续的、增量的,并且具有大约 99.99999999% 的持久性。 Aurora 可以在不到一分钟的时间内检测到数据库故障并恢复。 此外,在发生永久性故障的情况下,它可以自动移动到副本而不会丢失数据。 红移 与 Amazon Aurora 一样,大型企业也使用 Amazon Redshift。 但是,Redshift 更复杂,可以处理更多的数据,被称为数据仓库。 这是因为 Redshift 是为 OLAP(在线分析处理)构建的。
此外,Redshift 可以扩展到 PB 级的数据,每个集群最多支持 60 个用户定义的数据库。 另一方面,Aurora 只能扩展到 TB,最多支持 40 个。除此之外,两种数据库服务的安全性和维护性几乎相同。
Amazon Redshift 的一些用例是创建机器模型以预测运营、优化公司的商业智能并提高开发人员的工作效率。
好处 在我们检查过的三个选项中,Redshift 拥有最高的扩展能力。 它的性能更快,更耐用。 Amazon Redshift 还可以处理更大量的数据并在更短的时间内对其进行分析。 示例 SQL Redshift 支持一些通常只有大型数据仓库应用程序才需要的 SQL 函数和查询。 例如, PERCENTILE_CONT 计算线性插值以返回百分位数。
SELECT
动态数据库 DynamoDB 是亚马逊对 MongoDB 的回应,MongoDB 是一种适用于 JSON 文档的 NoSQL 数据库 。 这些数据库严重依赖嵌套数据,并且不会强制执行任何严格的模式,除非开发人员打开该选项。 这意味着 DynamoDB 非常适合 CMS 等大容量站点或具有大量流量的移动应用程序。 例如, 美国职业棒球大联盟和 Duolingo 都使用 DynamoDB。
示例 SQL 因为 DynamoDB 不是关系型数据库,并且默认情况下不强制执行 ACID ,所以它必须使用标准 SQL 的修改版本。 Amazon 开发了一种名为 PartiQL 的查询语言,它使用许多 SQL 概念,但专为高度嵌套的数据而构建。 下面的查询以相对 SQL 标准的方式利用了 DynamoDB 的键值基础。
UPDATE
键空间 Cassandra 是著名的分布式键值数据库。 iMessage 虽然 在客户端使用 SQLite,但 通过 Apple 的大型 Cassandra 集群发送所有消息。 其他构建具有高容错需求的分布式服务的开发人员也可能会考虑使用 Cassandra,尽管他们不想为管理大型集群而头疼。 这就是 AWS Keyspaces 通过证明托管 Cassandra 发挥作用的地方。
示例 SQL Cassandra 项目开发了自己的 SQL 子集,称为 CQL,它使用键空间、表、分区、行和列的概念来查询数据。 下面的例子是 一个 CQL 指令 ,它使用 Cassandra 著名的容错来恢复某个时间点的键空间。
RESTORE TABLE mykeyspace.mytable_restored
AWS 海王星 最著名的图数据库可能是 Neo4j,但对于 AWS 生态系统中的开发人员来说,Neptune 可以填补这个角色。 图数据库对于建模网络中 N 个项目之间的关系非常有帮助。 社交网络是一个显而易见的应用,但 欺诈检测甚至基础设施管理 也是图数据库的良好用例。 Neo4j 开发了一种名为 openCypher 的开源图形查询语言 ,AWS Neptune 支持该 语言。
示例 SQL 如您所见,将以下查询称为 SQL 查询有点仁慈。 事实上,openCypher 语言可能是这里最奇特的 SQL 语言。 在此查询中,我们定义了两个机场之间的路线。 这基本上是一个 INSERT. 稍后,我们可以在票务系统中查询机场之间的最佳路线选择。
MATCH (a:airport {code:'SEA'}), (b:airport {code:'ANC'}),
时间流 由于无限日志记录、物联网、区块链和金融科技的出现,时间序列数据库 越来越受欢迎。 时间序列数据库试图隐藏跨日期范围查询、存储无限历史数据和保持当前数据最新的痛苦。 压缩通常是使用时间序列数据库的关键指标。
AWS Timestream 专门帮助管理此数据的生命周期,还与您可能期望的其他 AWS 服务集成,包括 AWS IoT Core!
示例 SQL 在对时间序列数据进行查询时,我们大量使用公用表表达式 (CTE) 和聚合。 AWS Timestream 支持 许多有用的函数 ,使这些查询更容易,因为您想在 SQL 中实现线性插值吗? 在下面的查询中,我们发现特定 EC2 主机在过去 2 小时内以 30 秒的时间间隔划分的平均 CPU 利用率,使用线性插值填充缺失值。 然后可以将这些数据显示在方便的折线图上或以其他方式用于服务监控。
WITH binned_timeseries AS (
量子账本 (QLDB) QLDB 是一个庞大的分类账或金融事件的历史。 银行或人口普查局等组织使用分类账来确保无论他们的数据发生什么情况,他们都可以绝对确定记录。 我们将注意到 AWS 文档努力不使用术语区块链。 的确,如果 QLDB 分布在世界各地并开放访问,它将非常接近比特币。
QLDB 的关键属性是它是不可变的。 没办法,数据库的提交日志怎么能被修改。 如果是,分类帐可以报告此情况或拒绝处理其他交易。 QLDB 的基础是一种 名为 AWS Ion 的类似 JSON 的数据结构 。 我们之前看到了 PartiQL 如何为高度嵌套的数据提供一种 SQL 式查询语言。 下面的示例将一条记录插入 QLDB 以跟踪车辆登记。
示例 SQL 一旦这条记录被输入到账本中,它就变得不可变,并且在不插入新记录的情况下无法更改。 换句话说, UPDATE对于 QLDB 真的没有概念。
INSERT INTO VehicleRegistration VALUE
AWS 雅典娜 您是否曾经只是将数据推送到 S3 中而忘记了它? S3 通常存储数 TB 的 JSON、CSV、文本或其他非结构化数据。 AWS Athena 是一种 SQL 服务,用于从 S3 中提取数据并将其推送到关系结构中。 它非常适合检查存储桶、通过 ETL 流程转换数据或清理数据以发送到 Hadoop 等服务。 它还与 DataStation 兼容。
还有另一种使用名为 S3 Select 的服务查询 S3 的方法。 有关此主题的更多信息即将发布到 Arctype 博客! Athena 比 S3 Select 更灵活,因为它可以在同一个查询中触及多个对象和存储桶。 这也称为进行“临时”查询。
示例 SQL AWS Athena 的关键概念称为 从查询结果创建表 (CTAS) 。 很明显,在查询S3之前是不存在表的,所以我们需要利用 INSERT INTO拉取数据的时候来建表。 在下面的查询中,我们根据 S3 存储桶中的 CSV 绘制 2015 年之前的日期。
INSERT INTO new_parquet
用于 Aurora PostgreSQL 的 Babelfish 如果不将 Babelfish 列为此列表中的最后一个 SQL 服务,我们将是失职的。 从技术上讲 ,Babelfish 更像是一种技术 ,而不是成熟的数据库,但它接受 SQL 查询,所以我们开始吧!
使用 Babelfish ,您可以将您在 Microsoft 生态系统中编写的应用程序(例如使用 .NET 和 TSQL)连接到由 Postgres 支持的 AWS Aurora。 尽管我们会注意到 限制 和陷阱的列表似乎相当长,但对于拥有大量代码库并使用 TSQL 的组织来说,这实际上是比重写每个查询以支持 Postgres 更容易的迁移路径。
示例查询 这里只是一个简单的。 此查询不会在 Postgres 中运行,因为它使用 Microsoft 特定的语法。 然而,使用 Aurora 支持的 Babelfish,它将返回正确的结果。
SELECT @@VERSION AS version;
完全托管的数据库与管理服务器 上述所有选项都属于 AWS 软件正在执行繁重的配置、备份、横向扩展、升级以及与操作数据库相关的其他任务的类别。 当然,您可以将上述所有软件托管在您自己的服务器上并自己执行此操作。
弹性计算云 几乎 与 AWS Managed Services (AMS) 相反。 它被创建为虚拟机以同时创建多个实例。 每个实例都可以根据您的要求和需要运行操作系统或软件包。 虽然涉及 Auto Scaling 等功能,但用户仍需自行执行安全、资源利用、维护等重要功能。 这导致了另一组优点和缺点:
优点:
它具有高度可扩展性。 它与大多数 AWS 服务集成。 API 的存在使您的操作非常容易。 您可以完全控制实例。 缺点:
您必须查看公共实例的安全性。 管理生命周期的资源利用、维护和管理可能会变得非常乏味。 在特定场景下,EC2 对公司来说并不具有成本效益。 结论 这是对用于数据库和编写 SQL 的 AWS 数据库服务的(相当)完整的概述。 所有这些都允许您通过 SQL 操作和查询数据,这使得它们易于使用,同时还具有高度可扩展性。 突出的一件事是架构、语法和目标用例的多样性。 这说明了亚马逊产品的深度和云计算市场的规模。 振作起来,您在一个每年增长 40% 的行业工作!
文章来源:https://dzone.com/articles/10-aws-services-that-use-sql


















 京公网安备 11010802041100号
京公网安备 11010802041100号