A Survey on Deep Learning for Named Entity Recognition
NER的深度学习综述
Jing Li, Aixin Sun, Jianglei Han, and Chenliang Li
Nanyang Technological University 南洋理工大学
SAP
Wuhan University 武汉大学
Accepted in IEEE TKDE
TKDE:Transactions on Knowledge and Data Engineering
综述分为四个方面:
| 1 | NER资源 | tagged NER corpora(标注的命名实体语料);off-the-shelf NER tools(现成的工具) |
| 2 | 分类 | distributed representations for input(输入的分布式表示); context encoder(上下文编码), tag decoder(标注解码器) |
| 3 | 代表方法 | 在新的NER问题背景下应用的深度学习技术 |
| 4 | 总结 | challenges & future directions |
NER不但是一个独立的任务,而且在很多NLP任务中充当着重角色。
1996年MUC-6会议第一使用“Named Entity” (NE),用来识别organizations,people,geographic locations,time,percentage expressions等实体任务。
虽然对NER的定义有争议,但是共识:NEs的分类
NER可以分成两大类:generic NEs 与 domain-specific NEs.论文偏向generic NEs 四大NER技术主流程:
a. 基于规则方法。依赖手工规则,不用标注数据。
b. 非监督学习方法。
c. 基于特征的监督学习方法。要有特征工程。
d. 基于深度学习的方法。end-to-end方法。(详)
a. 近几年深度NER学习有比较好的发展;
b. NER综述文章比较少,有几篇,可是不是基于深度学习来作综述的;
以前NER综述文章:
| 年份与来源 | 题目 | 特点 |
|---|---|---|
| 2007 | A survey of named entity recognition and classification | 手工规则 |
| 2013 | Named entity recognition: fallacies, challenges and opportunities | 对谬误,挑战,机遇的思考 |
| 2015 | Approaches to named entity recognition: a survey | 比较简短的综述 |
| 2017,ICRTCCM | A survey on efficient extraction of named entities from new domains using big data analytics | 新领域NER的简短综述 |
| ACL, 2018 | Recognizing complex entity mentions: A review and future directions | 对于复杂实体综述 |
| COLING, 2018 | A survey on recent advances in named entity recognition from deep learning models | 介绍了最新的句子表达的技术,重点关注了句子的输入表达,可是没有回顾上下文编码器及标注解码 |
| Comput. Sci. Rev,2018 | Recent named entity recognition and classification techniques: A systematic review | 回顾了NER的进展,可是没有介绍最新的技术 |
略[见摘要]
NER任务:是指从自由文本中识别出属于预定义类别的文本片段。可以分为coarse-grained NER与fifine-grained NER tasks。举一个例子:

以2015年分界线,之前的数据少一些,后面会多一些。

CoNLL03:路透社新闻标注,语言为英语和德语;
OntoNotes:有5个版本,比较大规模的语料。由各种结构化信息分类与浅层语义构成。
近几年NER工作报告了他们在CoNLL03和Onto Notes数据集上的性能:

NER工具:学术 (top) and 工业 (bottom)

评估指标为:P,R, F1。
插入方便理解的图参考【1】

由于NER本质上是两个子任务:boundary detection(边界检测) and type identifification(类型识别)
精确匹配:边界检测正确&类型识别正确
其中F1值又可以分为macro-averaged和micro-averaged,前者是按照不同实体类别计算F1,然后取平均;后者是把所有识别结果合在一起,再计算F1。这两者的区别在于实体类别数目不均衡,因为通常语料集中类别数量分布不均衡,模型往往对于大类别的实体学习较好。
宽松匹配:分类正确,边界有交集就可以认为是正确;另一种情况,边界正确了,不管分类是否正确。
还有提出比较复杂的指标,可是复杂的不好分析,也流行不起来。
rule-based, unsupervised learning, feature-based supervised learning approaches
手动写规则 。
| 序号 | 特点 | 年份 | 题目 |
|---|---|---|---|
| 1 | 特定领域的地名录; | 2005 | Unsupervised named entity extraction from the web: An experimental study |
| 2 | 句法-词汇模式 | 2013 | Unsupervised biomedical named entity recognition: Experiments with clinical and biological texts |
| 3 | Brill rule | 2000 | A rule-based named entity recognition system for speech input |
| 4 | 基于同义词字典 | 2005 | Prominer: rule-based protein and gene entity recognition |
| 5 | 基于词典 | 2016 | Named entity recognition over electronic health records through a combined dictionary-based approach |
基于规则的NER系统: LaSIE-II,NetOwl,Facile,SAR,FASTUS,LTG
优点:如果规则与词典都可以枚举的话,这个系统还是很有用的。
缺点:很难去列举得完整,另外也很难从一个领域移到另一个领域中去。
典型使用–聚类。这个关键点在词典,词模式和大语料的统计。
| 论文 | 介绍 |
|---|---|
| Collins et al. [54] | 归纳成7个简单的规则,然后对于NER提出两个非监督算法 |
| KNOWITALL [9] | 使用一组谓语动词作为输入,从一组普通的抽取模式中提升识别过程 |
| Nadeau et al. [55] | 提出地名索引解决命名实体歧义,提出简单却有效的方法把命名识别与消歧相结合起来 |
| Zhang and Elhadad [44] | 提出一个非监督的方法从生物医学文本中抽取命名实体,在两个主流的生物医药数据库上展示非监督方法的有效性与泛化性 |
将NER问题转换成标注序列问题或标签分类问题。
核心: 特征工程[Feature Engineering];
| 特征 | 举例 |
|---|---|
| Word-level features( 词级特征) | case, morphology, and part-of-speech tag(格,形态学,词性标注) |
| list lookup features(列表查找特征) | Wikipedia gazetteer and DBpedia gazetteer (地名) |
| document and corpus features(文件与语料特征) | local syntax and multiple occurrences (本地语法和多次出现) |
| Feature vector representation(特征向量表达) | one or many Boolean,numeric,nominal values |
| 应用去学习的模型 |
|---|
| Hidden Markov Models (HMM) [69] |
| Decision Trees [70] |
| Maximum Entropy Models [71] |
| Support Vector Machines[72] |
| Conditional Random Fields (CRF) [73]. |
一些提出的方法
| Bikel et al. [74], [75] | 第一个HMM-based NER系统 |
| Szarvas et al. [76] | 使用C4.5与AdaBoostM1学习方法开发了一个多语言NER系统。最大贡献:通过多数选举合成不同特征子集的几棵独立DT分类器的方法作为一种可能。 |
| Borthwick et al. [77] | “maximum entropy named entity” (MENE),能够利用各种来源的知识来做出标记决定。 |
| McNamee and Mayfifield [81] | 使用与语言相关的1000个和258个字形和标点符号特征去训练SVM分类器,每个分类器判断当前的token是否属于8个分类之一,缺点SVM不考虑相邻词 |
| McCallum and Li [82] | 提出特征归纳方法 |
| Krishnan and Manning [67] | 基于两个couple CRF分类器提出两阶段方法 |
基于CRF被广泛应用在各个领域,包括生物文本,tweets, 化学文本等方面。
深度学习技术的明显优点: discovering hidden features automatically(自动发现隐藏的特征).
深度学习使用多个抽象层由多处理层去学习数据表达。典型的层是由前向与后向组成的人工神经网络。
深度学习的重要优点:表示学习的能力,向量表示与神经赋予的语义组合。
喂入源数据给机器,自动发现潜在表达并对分类器或检测器作处理。
三大优点:
优点01: NER得益于深度学习的非线性学习特性。由于非线性,使用神经网络可以从数据中学习更复杂的特征。
优点02: DL可以节省大量设计特征的时间,也不需要太多的专家介入来设计特征,且自动地学习表达。
优点03:DL采用的是end-to-end模式。
DL-based NER的流程:输入的分布式表示,上下文编码,标签解码.
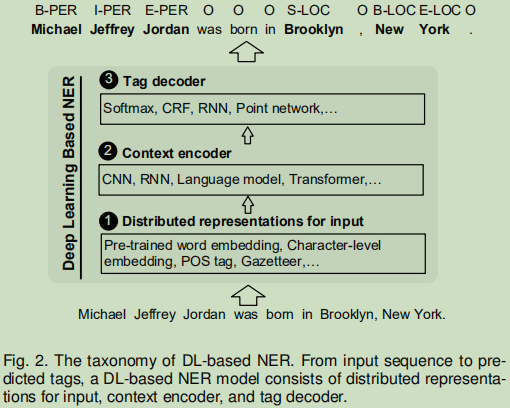
==输入分布式表示:==考虑“词级”与“字符级”的嵌入,同时也包含一些其它方面的特征----POS标注,Gazetteer(地名词典)等等。
==上下文编码:==使用CNN,RNN等神经网络去捕捉上下文的依赖关系;
==Tag 解码:==预测token标签。
| 题目 | 来源 |
|---|---|
| Toward mention detection robustness with recurrent neural networks | 2016 |
| Joint extraction of entities and relations based on a novel tagging scheme | ACL, 2017 |
| Fast and accurate entity recognition with iterated dilated convolutions | ACL, 2017 |
| Effificient estimation of word representations in vector space | ICLR, 2013 |
常用的表示: Google Word2Vec, Stanford GloVe, Facebook fastText and SENNA。
领域表示:
| 引用 | 项目名 | 表示模型 | 语料 | 简介 | 语言 |
|---|---|---|---|---|---|
| Yao et al. [94] | Bio-NER | skip-gram model(600维,205924词) | PubMed | ||
| Nguyen et al. [89] | word2vec toolkit | Gigaword | English | ||
| Zhai et al. [95] | SENNA | 设计成分段与标注两个子任务 | |||
| Zheng et al. [90] | word2vec tookit | NYT | 联合实体与关系抽取的单模型 | ||
| Strubell et al. [91] | ID-CNNs | SENNA corpus by skip-n-gram | |||
| Zhou et al. [96] | Google 300维词向量 |
在方面的一个明显的使用是sub-word-level,例如前缀,后缀;另外,它可以处理out-of-vocabulary的问题;
分两类:CNN-based模型,RNN-based模型

CNN-based模型
| 引用 | 描述 |
|---|---|
| Ma et al. [97] | 使用CNN去抽取字符表达,然后把字符表达联合成一个word向量,最后送入到RNN模型中 |
| Li et al. [98] | 使用一系列卷积层和高速公路层,为单词生成字符级表示,最后送入到双向RNN模型中 |
| Yang et al. [102] | 提出神经重排模型,一个卷积层在字符顶层使用固定大小的窗口 |
| Peters et al. [103] | ELMo |
RNN-based模型
| Kuru et al. [100] | 提出CharNER,语言独立于NER的字符层标注器;CharNER把一个句子看成一个字符序列,使用LSTM去抽取字符层的表达,对于每个字符输出一个标注分布表示而不是字符表示 |
| Lample et al. [19] | 使用双向LSTM抽取字符级表达; |
| [97] | 使用双向LSTM表示,字符级的表达与词级表达连接在一起 |
| Gridach [104] | 使用词与字符表达去识别生物医学实体 |
| Rei et al. [105] | 使用门机制去把字符合并成一个词,动态决定字符级或词级组件。 |
| Tran et al. [101] | 使用了stack residual LSTM |
| [106] | 以统一的方式进行跨语言和多任务联合训练 |
| Akbik et al. [107] | 使用BiLSTM模型,用动态embedding取代静态embedding,character-level的模型输出word-level的embedding. 每个词的embedding和具体任务中词所在的整句sequence都有关,算是解决了静态embedding在一词多义方面的短板,综合了上下文信息。 |
除了使用词或字符或两者组合信息去建立表达之外,也使用来其它信息:gazetteers( 地名词典),lexical similarity(词汇相似度), linguistic dependency(语言依存),即是用混合的方法把基于特征的信息整合去基于深度学习的表达中。
| Huang et al. [18] | 提出了BiLSTM-CRF模型,使用了四种特征:spelling features,context features,word embeddings, gazetteer features |
| Chiu and Nichols [20] | 提出 BiLSTM-CNN模型,这个模型包括了Bi-LSTM与一个字符级的CNN. 使用了词级表达及其它信息(大写,专有名词等);同时,字符级(4-dimensional vector representing the type of a character: upper case, lower case,punctuation, other) |
| Wei et al. [112] | 阐述了一个基于CRF去识别与标准化疾病名称的神经系统,系统在词嵌入中使用了丰富的特征(words, POS tags, chunking, and word shape features(dictionary and morphological features)) |
| Strubell et al. [91] | 五维词形态向量连接100维嵌入,例如大写,第一个字母大写等等 |
| Lin et al. [113] | 词表示+字符表示+句法表示(POS tags, dependency roles, word positions, head positions) |
| Aguilar et al. [114] | 多任务被使用,在字符级使用CNN去捕捉字形特征和词形状;对于词级的句法及上下文信息,模型实现了LSTM框架。 |
| Jansson and Liu [115] | 词级与字符级表示与LDA结合起来用 |
| Xu et al. [116] | 提一种基于FOFE局部检测方法 |
| Moon et al. [118] | 提出多模态NER系统,模态整合多方面的信息:带噪音的用户数据,词嵌入,字符嵌入,可视化特征 |
| Ghaddar and Langlais [109] | 提出一种新的词汇表示,词带有词类型 |
| Devlin et al. [119] | BERT |
上下文编码框架:CNN,RNN,递归NN,深度transformer.
| Collobert et al. [17] | 考虑整个句子去标注一个词。 每个词被嵌入变成N-维向量。卷积层是输出局部特征,尺寸是由句子长度决定。全局特征向量是通过卷积抽取局部向量特征来得到,全局特征向量的维度是固定的,独立于句子长度,方便后续的网络层。最后这个合部信息被输入到解码器中去计算标注分布。  |
| Yao et al. [94] | 对于生物医学NER提出Bio-NER |
| Wu et al. [120] | 根据全局隐含节点数使用一个卷积层去泛化全局特征表达。局部与全局的信息都输入去预测NER |
| Zhou et al. [96] | 观察到,使用RNN,后面的词比前面的词对最终句子表示更具影响性。提出了模型BLSTM-RE,BLSTM |
| Strubell et al. [91] | 提出ID-CNNs(Iterated Dilated Convolutional Neural Networks),提高了计算效率。 |
基于RNN的上下文编码器框架:
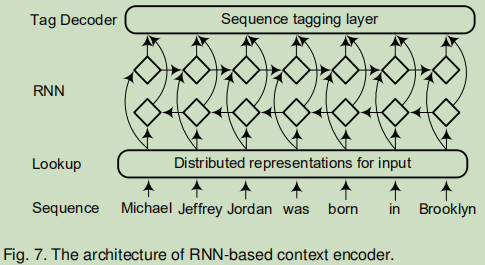
Bidirectional lstm-crf models for sequence tagging应该是最早的一篇关于bi-LSTM+CRF框架的论文
随后,应用BiLSTM作为基础框架去编码序列上下文信息:
| 索引 | 题目 | 来源 |
|---|---|---|
| [19] | Neural architectures for named entity recognition | NAACL, 2016 |
| [20] | Named entity recognition with bidirectional lstm-cnns | Trans. Assoc. Comput. Linguist,2016 |
| [89] | Toward mention detection robustness with recurrent neural networks | 2016 |
| [90] | Joint extraction of entities and relations based on a novel tagging scheme | ACL, 2017 |
| [95] | Neural models for sequence chunking | AAAI, 2017 |
| [96] | Joint extraction of multiple relations and entities by using a hybrid neural network | CCL-NLP-NABD. Springer, 2017 |
| [97] | End-to-end sequence labeling via bidirectional lstm-cnns-crf | ACL,2016 |
| [101] | Named entity recognition with stack residual lstm and trainable bias decoding | IJCNLP, 2017 |
| [105] | Attending to characters in neural sequence labeling models | COLING, 2016 |
| [112] | Disease named entity recognition by combining conditional random fields and bidirectional recurrent neural networks | 2016 |
| [113] | Multi-channel bilstm-crf model for emerging named entity recognition in social media | W-NUT, 2017 |
| 索引 | 题目 | 来源 | 描述 |
|---|---|---|---|
| [106] | Multi-task cross-lingual sequence tagging from scratch | 2016 | 在字符层与词层使用深度GRUs去编码词性及上下文 |
| Gregoric et al. [121] | Named entity recognition with parallel recurrent neural networks | ACL,2018 | 使用多重独立BiLSTM |
| [122] | Nested named entity recognition revisited | ACL,2018 | 基于LSTM的嵌套NER |
| [123] | A neural layered model for nested named entity recognition | NAACL-HLT,2018 | 基于LSTM的嵌套NER |
递归的只介绍了一篇:
P.-H. Li, R.-P. Dong, Y.-S. Wang, J.-C. Chou, and W.-Y. Ma, “Leveraging linguistic structures for named entity recognition with bidirectional recursive neural networks,” in EMNLP, 2017, pp. 2664–2669.

a. 前向语言模型
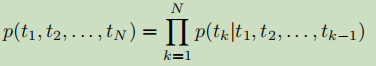
b. 后向语言模型

c. 神经语言模型
| 题目 | 来源 | 描述 |
|---|---|---|
| [21]Semisupervised sequence tagging with bidirectional language models | ACL, 2017 | 提出TagLM |
| [103]Deep contextualized word representations | NAACL-HLT, 2018 | |
| [124]Semi-supervised multitask learning for sequence labeling | ACL, 2017 | |
| [125]Efficient contextualized representation: Language model pruning for sequence labeling | EMNLP, 2018 | |
| [126]Empower sequence labeling with task-aware neural language model | AAAI, 2017 | |
| [127]Cross-domain NER using crossdomain language modeling | ACL, 2019 | |
| [107]Contextual string embeddings for sequence labeling | COLING, 2018 |

更详细的略.
主要介绍了一些基于transformer的预训练模型。
基于transformer,提出GPT(Generative Pre-trained Transformer).BERT,ELMO 等相关的预训练模型。


这里把序列标注任务看作为多分类问题。对于每个token的标注都是独立预测的,并不会考虑它相邻的内容,这个方法早期应该是使用得比较多:
| [91] | Fast and accurate entity recognition with iterated dilated convolutions | 2017 |
| [98] | Leveraging linguistic structures for named entity recognition with bidirectional recursive neural networks | 2017 |
| [116] | A local detection approach for named entity recognition and mention detection | ACL,2017 |
| [119] | Bert: Pre-training of deep bidirectional transformers for language understanding | NAACL-HLT, 2019 |
| [139] | Hierarchically-refined label attention network for sequence labeling | EMNLP, 2019 |
对于某个领域NER:Domain specific named
entity recognition referring to the real world by deep neural
networks [140]使用softmax作为tag解码器用来预测日本棋的游戏状态。
CRF可谓是最常用的方法了,接在上下文编码后作为解码。
作Bi-LSTM的顶层:[18], [90], [103], [141]
作CNN的顶层:[17], [91], [94]
Zhuo et al. [142]提出门递归的半马尔可夫CRFs,直接对段进行建模而不对词;
Ye and Ling [143]对神经序列标注提出混合半马尔可夫CRFs.
相对比较少的研究:
[88]:Y. Shen, H. Yun, Z. C. Lipton, Y. Kronrod, and A. Anandkumar, “Deep active learning for named entity recognition,” in ICLR,2017.
[89]:T. H. Nguyen, A. Sil, G. Dinu, and R. Florian, “Toward mention detection robustness with recurrent neural networks,” arXiv preprint arXiv:1602.07749, 2016.
[90]: S. Zheng, F. Wang, H. Bao, Y. Hao, P. Zhou, and B. Xu, “Joint
extraction of entities and relations based on a novel tagging
scheme,” in ACL, 2017, pp. 1227–1236.
[96]: P. Zhou, S. Zheng, J. Xu, Z. Qi, H. Bao, and B. Xu, “Joint
extraction of multiple relations and entities by using a hybrid
neural network,” in CCL-NLP-NABD. Springer, 2017, pp. 135–146.
[144]: A. Vaswani, Y. Bisk, K. Sagae, and R. Musa, “Supertagging with
lstms,” in NAACL-HLT, 2016, pp. 232–237.
指针网络是使用RNNs去学习一个输入序列相对应位置的离散token元素的条件概率分布。词典大小是可变长的,使用softmax概率分布来作为“指针”。
Zhai et al. [95]:第一个应用指针网络去处得序列标注问题。首先识别分段,然后标注,这两个任务通过分开的神经网络来实现。
(1) Segmentation, to identify scope of the chunks explicitly;
(2) Labeling, to label each chunk as a single unit based on
the segmentation results.
图来自[95]F. Zhai, S. Potdar, B. Xiang, and B. Zhou, “Neural models for sequence chunking.” in AAAI, 2017, pp. 3365–3371.
BiLSTM +CRF是最常的方法。
NER的成功之处来源于预训练的表达。
第一,是否加入外部的知识数据没有共识。优点:使用外部知识对于NER任务的确是有很好提升。缺点:构建外部知识体系是一个劳力密集的,另外,不利于深度学的端到端学习与对于泛化也是不利的;
第二,当Transformer大量语料训练后,Transformer编码比LSTM更有效;另外,在时间的复杂度方面也有优势。缺点:Transformer要大量预训练后才有效果。
第三,RNN与指针网络的最大缺点为解码器都是基于贪婪思想,依赖于前一个输入,这样就限制了算法的并行处理。CRF可以有效捕捉标注转移的依赖性。
| Wu et al. [120] and Wang et al. [149] | Chinese clinical text |
|---|---|
| Zhang and Yang [150] | lattice-structured LSTM,Chinese NER |
这里只把中文的摘出来了,论文还讲了对于其它语言的,还有跨语言的。
a. NER与其它序列标注任务一起形成多任务
Collobert et al. [17]: 联合POS, Chunk, NER, SRL 等任务来学习。
Yang et al. [106]: 联合 POS, Chunk, NER 等任务学习。
Rei [124]:发现在训练过程中能过加入非监督语言目标,这个序列标注模型得到了相应的性能提升。
Linet al. [160]:对于低资源环境,提出了多语言多任务的学习框架,有效地转化各种知识去提升主要模型。
b. 实体抽取与关系识别联合
[90],[96]
c. 实体的任务细分为实体分段与实体分类
[114], [162]
d. 不同的数据集,可以把NER看成多任务
[163], [164]
Pan et al. [169]:提出跨域的transfer joint embedding(TJE)方法;这个属于低资的方法;
Qu et al. [174]: 使用两层神经网络去学习源域与目标域命名实体类型之间的关系,这个方法使用背景是源域与目标域有相似的实体类型;
Peng and Dredze [162]:在多任务上研究迁移学习;
Yang et al. [175]:研究对于跨域,跨语言,跨应用为背景有三种不同的参数共享方式 ;
Pius and Mark [176]:联合训练信息语料与合并句子级特征表达;
Zhao et al. [177]:提出领域适应的多任务模型,全连接层适应不同数据库,CRF层单独训练;
Lee et al. [170]:通过在源领域进行预训练模型,把预训练好的模型迁移到目标领域进行微调;
Lin and Lu [171]:也是微调的方法;
Beryozkin et al. [178]:对于异构标记集NER设置提出tag分层模型,分层在推理标签时被使用。
[164], [179], [180]:在生物医学NER中使用迁移,为了降低要求的标签数据。
机器为主,标注人员根据机器选出来的无标注样本进行标注。
Shen et al. [88]:提出用每批新标签对NER进行增量培训。
[182] :选择句子时采用不确定策略;
[183]:12.0% and 16.9%的数据就可以达到合部数据的预测效果。
Narasimhan et al. [187]:把信息抽取看作一个 马尔可夫过程 (MDP),动态地结合实体预测并提供灵活性,以便从一组自动生成的选项中选择下一个搜索查询。
[188]:使用一个深度Q-network作为函数的近似。
Yang et al. [189] :利用远程监督生成的数据在新域中执行新类型的命名实体识别。
对抗的目的是使模型更具强壮性。
第一种方法:[192]–[194]:认为源域中的实例是目标域的对抗性例子,反之亦然。
第二种方法:[195]:通过添加带有扰动的原始样本来准备对抗性样本;
Rei et al. [105] :在end-to-end的模型中,使用关注力机制动态地决定使用的信息有多少是来自字符或词组件;
Zukov-Gregoric et al. [197]:研究NER中的自关注学习。
Xu et al. [198]:提出一个基于关注力神经NER框架使用文本级全局信息。
Zhang et al. [199]:在推文中使用了一个自适应的NER co-attention网络。这个是一个多模态模型,包括了可视关注力,文本关注力。
a. 数据标注;
b. 非正式文本与未见过的实体;
a. 细粒度NER与边界检测;
b. 联合NER与实体连接;
c. 使用附助资料在非正式文本上的深度NER学习;
d. 深度NER的可测量性;
e. 深度迁移学习NER;
f. 简单易用的深度NER工具;
整体来说,这里面的内容还是比较全面的。对于token与上下文的表达,不单单是NER任务,一般要处理NLP问题都要去研究这个表达。
另外,对于解码的总结也很好,也算是比较好的,一共四种,一般我们用CRF,知道有softmax这种,不知还有另外两种。两个表格总结也是很让人喜悦的。
面铺得很广,由于学得不够深,get到的最后一个印象内容却是预训练表达,对字符,词的表达,上下文的表达;感觉联合的模型少了一些,对于图神经网络的运用也没有看到。
【1】如何解释召回率与精确率?, https://www.zhihu.com/question/19645541
格语法(case grammar):语法关系理论
费尔莫尔针对乔姆斯基的语法理论提出,认为乔姆斯基提出的深层结构的语法关系,实际属于表层结构的主谓概念,而格才真正构成深层结构中的语法关系。格是普遍存在于所有语言中的“格功能”或“格关系”。
by happyprince https://blog.csdn.net/ld326/article/details/113250638










 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有 