
1.几个问题
1.1 基本信息
CVPR 2020
1.2 做了什么
提出了AdvProp
1.3 实现方法 & 创新性
对抗性例子用auxiliary BN处理,干净例子用main BN进行处理。解决二者混合导致的数据分布失真。
1.4 代码链接
Github
2.数学部分 & 模型构建
2.1 现有问题 & 解决方法
现有问题
- 以往的研究表明,对抗性样本训练可以提高模型的泛化能力,但仅限于某些情况,这种改进要么在完全监督的情况下对小数据集(如MNIST)进行,要么在较大的数据集(但在半监督环境下)上观察到。
- 在大数据集下,采用对抗性训练还会减低对清洁数据识别的准确率。
- 现有的对抗性训练的模型本质上没有区别,因为我们假设清洁示例和对抗性示例之间的分布是不匹配的(distribution mismatch)。
解决方法
对对抗性例子和干净例子进行处理,让二者分布接近。
2.2 对抗性训练的目标函数
传统CNN
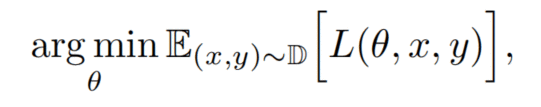
对抗性CNN(Madry’s adversarial training framework)
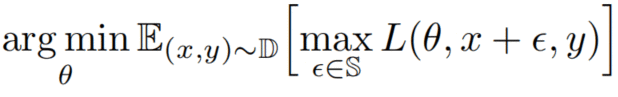
其中DDD是潜在的数据分布,LLL是损失函数,θ\thetaθ是网络参数,xxx是带有真实标签yyy的数据,ε\varepsilonε是加性对抗扰动,SSS是允许的扰动范围。
改进后的对抗性训练CNN
然而,Madry优化函数具有一定的约束。Madry的对抗性训练min的对象只有max L,而max L对应的只是负面例子带来的损失,且max L不能反映L的全局,比较片面。加上L之后,既能改善max的片面性,又能考虑到原本对正面例子的损失,因此更加全面。
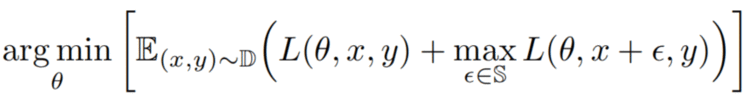
等式 3
虽然理论上改进后的模型能同时从对抗性和干净样本中获得好处。然而可能由于而这两个数据分布不匹配,上式中的模型效果并没有特别好。
2.3 借助Auxiliary BN进行解纠缠学习
Batch Normalization 可以对每个batch中的数据进行归一化处理,使之分布更加一致,从而提高学习效率,这和本文中要改善对抗性数据和干净样本数据的分布的目标是一致的。
使用BN的一个内在假设是,输入特征应该来自单个或类似的分布,否则会出大问题。

论文作者认为,对抗性的例子和干净的图像有不同的潜在分布,并且等式(3)中的对抗性训练框架本质上是一个两成分混合分布。如果采取图3中传统CNN的结构,把对抗性数据和干净数据同时输入一个BN,由于二者的分布不同,BN的输出会导致虚假的分布。然而,如果采用两个BN分别对两种分布不同的数据分别进行处理,最后的结果就会好很多。








 京公网安备 11010802041100号
京公网安备 11010802041100号