前言
利用爬虫可以做很多事情,单身汉子们可以用爬虫来收集各种妹子情报,撩妹族们可以用爬虫收集妹子想要的小东西,赚大钱的人可以用来分析微博言论与股票涨跌的关系诸如此类的,简直要上天了。
你们感受一下 点我点我:

蠢蠢欲动
抛开机器学习这种貌似很高大上的数据处理技术,单纯的做一个爬虫获取数据还是非常简单的。对于前段er们来说,生在有nodejs的年代真是不要太幸福了,下面就用nodejs来做一个爬虫吧。
这次我们先拿CSDN来练练手,爬妹子什么的,其实大同小异。要实现的功能就是爬取前端板块的博文,输出作者的信息。
首先是工具的准备,nodejs当然是必须要装好的,我这里用的是目前最新版的6.2.0版本。另外由于我们需要通过各种http请求去爬取内容,所以一个好用的http调试工具也是必需的,这里我推荐是用postman。
搭建环境
根据爬虫需要的功能确定我们要使用的第三方库:
后端服务: express
发出http请求: superagent
控制并发请求:async + eventproxy
分析网页内容:cheerio
相关库的 API 请到对应的 GitHub 项目页上去了解,这里我就不再赘述了,对应的 package.json :
{
"name": "spider",
"version": "0.0.0",
"description": "learn nodejs on github",
"scripts": {
"start": "node app.js"
},
"dependencies": {
"async": "^2.0.0-rc.6",
"cheerio": "^0.20.0",
"eventproxy": "^0.3.4",
"express": "^4.9.5",
"superagent": "^2.0.0"
},
}
写好的 package 记得安装下,这样我们就搭好了开发环境。
爬虫主体
下面按照爬虫需要的功能来一步步写爬虫主体。
后台服务部分
实现的功能是接收前端请求启动爬虫,完成信息爬取之后将信息返回给前端。后台服务部分我这里使用了 express 框架,这里比较简单也可以使用原生的 http 模块。简单框架如下:
var express = require(\'express\');
var app = express();
app.get(\'/\', function (req, res, next) {
// your code here
});
app.listen(3000, function (req, res) {
console.log(\'app is running at port 3000\');
});
在 get 处理中插入我们的响应代码,包括启动爬虫,结果信息输出等。
文章链接的爬取
这里我们用到的是 superagent 这个库来实现,此库作者是个多产大神,我们这里用到的库基本都是他写的,颤抖吧、少年们!
superagent.get(Url).end(function (err, res) {
if (err) { return next(err); }
// your code here
});
Url 为我们请求的地址,使用 get 的方式请求,其实效果跟你用浏览器打开 Url 的效果是一样的,返回来的数据都放在 res 中,对 res 分析就可以得到我们想要的数据了。
数据的处理
这里我们用到的是 cheerio 这个库,他可以让我们以 jQuery 的方式操作返回的数据,实在太贴心了。
// 提取作者博客链接,注意去重
var $ = cheerio.load(sres.text);
$(\'.blog_list\').each(function (i, e) {
var u = $(\'.user_name\', e).attr(\'href\');
if (authorUrls.indexOf(u) === -1) {
authorUrls.push(u);
}
});
是不是很熟悉的感觉? 完全就是 jQuery 的语法呀。
文章作者信息的爬取
这里我们要进入作者主页去爬取相应的消息,跟上一步爬取链接是一样的。
superagent.get(authorUrl)
.end(function (err, s-s-res) {
if (err) { callback(err, authorUrl + \' error happened!\'); }
var $ = cheerio.load(s-s-res.text);
var result = {
userId: url.parse(myurl).pathname.substring(1),
blogTitle: $("#blog_title a").text(),
visitCount: parseInt($(\'#blog_rank>li\').eq(0).text().split(/[::]/)[1]),
score: parseInt($(\'#blog_rank>li\').eq(1).text().split(/[::]/)[1]),
oriCount: parseInt($(\'#blog_statistics>li\').eq(0).text().split(/[::]/)[1]),
copyCount: parseInt($(\'#blog_statistics>li\').eq(1).text().split(/[::]/)[1]),
trsCount: parseInt($(\'#blog_statistics>li\').eq(2).text().split(/[::]/)[1]),
cmtCount: parseInt($(\'#blog_statistics>li\').eq(3).text().split(/[::]/)[1])
};
callback(null, result);
});
这里我们是用 callback 返回结果的。
并发的控制
因为我们的请求都是异步的,所以需要执行成功的回调函数中执行下一步操作,在多并发的情况下,就需要一个计数器来判断是否所有并发均已成功执行完。这里用到的是 eventproxy 这个库来替我们管理并发结果。
CSDN上web前端有3页,所以我们要执行 3 次爬取文章链接,用 eventproxy 的写法就是:
var baseUrl = \'http://blog.csdn.net/web/index.html\';
var pageUrls = [];
for (var _i = 1; _i <4; _i++) {
pageUrls.push(baseUrl + \'?&page=\' + _i);
}
ep.after(\'get_topic_html\', pageUrls.length, function (eps) {
// 文章链接都已经爬取完了
});
pageUrls.forEach(function (page) {
superagent.get(page).end(function (err, sres) {
// 文章链接的爬取
ep.emit(\'get_topic_html\', \'get authorUrls successful\');
});
});
简单来说,就是会检测 \'get_topic_html\' 的emit事件,发生指定次数之后就调用 ep.after 函数。
并发请求数控制
本来呢,到这里就完了,但是我们爬取作者信息时都是用异步操作的,所以同时可能会有几十甚至几百个请求同时发送给目标网站。出于安全角度考虑,目标网站可能会拒绝我们的请求,所以我们要控制并发数量,这里我们用的是 async 这个库来实现。
// 控制最大并发数为5,在结果中取出callback返回来的整个结果数组。
async.mapLimit(authorUrls, 5, function (myurl, callback) {
// 请求作者信息
}, function (err, result) {
console.log(\'=========== result: ===========\n\', result);
res.send(result);
});
这里 authorUrls 是我们前一步爬取好的作者链接数组,async 会根据数组长度依次执行。之前在作者信息爬取部分我们使用了回调函数返回数据,这个也是async 提供的接口。最终数组中所有元素都被执行了一遍之后,就会将 callback 返回的数据放入 result 数组中,将这个数组返回给前端即可。
效果
通过 node app.js 执行后台程序,在 postman 中输入 http://localhost:3000 查看结果:
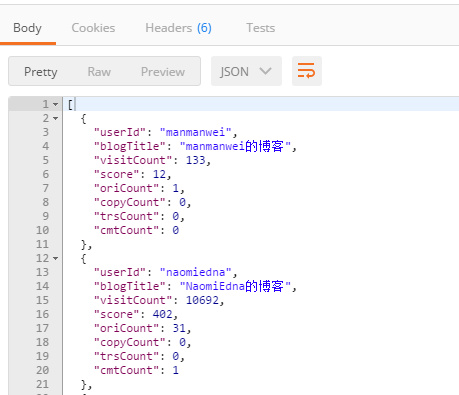
可以看到在返回中的body中已经将我们需要的数据返回来了。
至此,我们的小爬虫就完成了,是不是很简单呢?
完整的代码
/***
* Created by justeptech on 2016/7/11.
*/
var cheerio = require(\'cheerio\');
var superagent = require(\'superagent\');
var async = require(\'async\');
var url = require(\'url\');
var express = require(\'express\');
var app = express();
var eventproxy = require(\'eventproxy\');
var ep = eventproxy();
var baseUrl = \'http://blog.csdn.net/web/index.html\';
var pageUrls = [];
for (var _i = 1; _i <4; _i++) {
pageUrls.push(baseUrl + \'?&page=\' + _i);
}
app.get(\'/\', function (req, res, next) {
var authorUrls = [];
// 命令 ep 重复监听 emit事件(get_topic_html) 3 次再行动
ep.after(\'get_topic_html\', pageUrls.length, function (eps) {
var cOncurrencyCount= 0;
// 利用callback函数将结果返回去,然后在结果中取出整个结果数组。
var fetchUrl = function (myurl, callback) {
var fetchStart = new Date().getTime();
concurrencyCount++;
console.log(\'现在的并发数是\', concurrencyCount, \',正在抓取的是\', myurl);
superagent.get(myurl)
.end(function (err, s-s-res) {
if (err) {
callback(err, myurl + \' error happened!\');
}
var time = new Date().getTime() - fetchStart;
console.log(\'抓取 \' + myurl + \' 成功\', \',耗时\' + time + \'毫秒\');
concurrencyCount--;
var $ = cheerio.load(s-s-res.text);
var result = {
userId: url.parse(myurl).pathname.substring(1),
blogTitle: $("#blog_title a").text(),
visitCount: parseInt($(\'#blog_rank>li\').eq(0).text().split(/[::]/)[1]),
score: parseInt($(\'#blog_rank>li\').eq(1).text().split(/[::]/)[1]),
oriCount: parseInt($(\'#blog_statistics>li\').eq(0).text().split(/[::]/)[1]),
copyCount: parseInt($(\'#blog_statistics>li\').eq(1).text().split(/[::]/)[1]),
trsCount: parseInt($(\'#blog_statistics>li\').eq(2).text().split(/[::]/)[1]),
cmtCount: parseInt($(\'#blog_statistics>li\').eq(3).text().split(/[::]/)[1])
};
callback(null, result);
});
};
// 控制最大并发数为5,在结果中取出callback返回来的整个结果数组。
async.mapLimit(authorUrls, 5, function (myurl, callback) {
fetchUrl(myurl, callback);
}, function (err, result) {
console.log(\'=========== result: ===========\n\', result);
res.send(result);
});
});
// 获取每页的链接数组,这里不要用emit返回了,因为我们获得的已经是一个数组了。
pageUrls.forEach(function (page) {
superagent.get(page).end(function (err, sres) {
// 常规的错误处理
if (err) {
return next(err);
}
// 提取作者博客链接,注意去重
var $ = cheerio.load(sres.text);
$(\'.blog_list\').each(function (i, e) {
var u = $(\'.user_name\', e).attr(\'href\');
if (authorUrls.indexOf(u) === -1) {
authorUrls.push(u);
}
});
console.log(\'get authorUrls successful!\n\', authorUrls);
ep.emit(\'get_topic_html\', \'get authorUrls successful\');
});
});
});
app.listen(3000, function (req, res) {
console.log(\'app is running at port 3000\');
});
关于Nodejs搭建小爬虫的介绍就到这里了,码字不易,顺手点赞哈!
本文源自WeX5论坛,尊重原创,原文链接:http://bbs.wex5.com/forum.php?mod=viewthread&tid=100231&pid=165282433&page=1&extra=




 京公网安备 11010802041100号
京公网安备 11010802041100号