相比于之前的序列方法,比如Parsing as Language Modeling,本文的序列化有所不同,主要体现在之前的方法都是seq2seq的,也就是输入句子,直接输出树的括号表达式序列。但是这种方法输出不是定长的,所以结果可能会比较差。本文的方法将输出长度固定在了句子长度减1上(只针对不存在一元产生式的句法树,这种情况之后讨论),所以可以将每个预测分配到每个单词上,然后用序列标注的方法来解决。
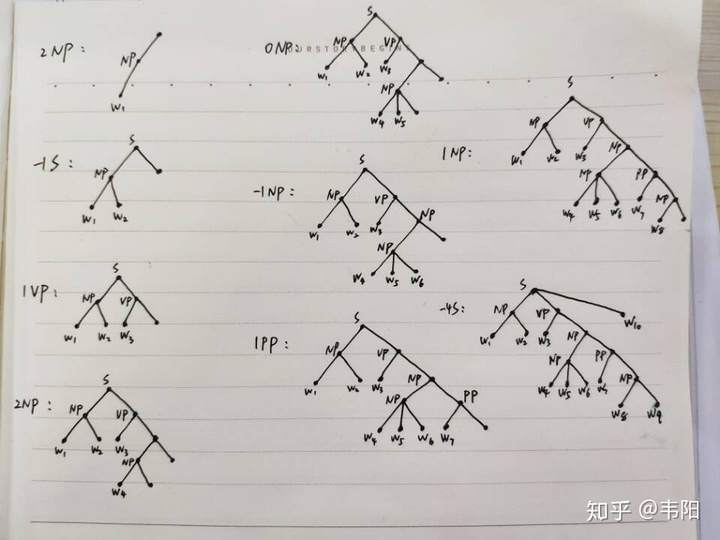
一种情况是对于多叉树,相邻两对叶子结点的LCA的label预测不同。比如在最上面一张图中,“the red toy”如果预测为两个不同的label,那么就会产生矛盾。这种情况很好解决,只要在解码的时候只取第一个label,忽略后一个就行了。
本文详细介绍了一种利用 ESP8266 01S 模块构建 Web 服务器的成功实践方案。通过具体的代码示例和详细的步骤说明,帮助读者快速掌握该模块的使用方法。在疫情期间,作者重新审视并研究了这一未被充分利用的模块,最终成功实现了 Web 服务器的功能。本文不仅提供了完整的代码实现,还涵盖了调试过程中遇到的常见问题及其解决方法,为初学者提供了宝贵的参考。 ...
[详细]
![\textbf{w} = [w_1, w_2, \ldots, w_N]](https://img5.php1.cn/3cdc5/935d/3b4/850e213fbb5adca3) ,其中
,其中  。
。  为拥有
为拥有  个叶子结点的不含有一元产生式的句法树集合。句法分析的任务就是将输入句子
个叶子结点的不含有一元产生式的句法树集合。句法分析的任务就是将输入句子  映射到句法树
映射到句法树  ,也就是将一棵有
,也就是将一棵有  的序列。并且该映射函数还得满足一定的条件,首先它一定得是一个函数(也就是对于所有的句法树,都得找到一个对应的序列),然后这个函数还得有单射性(也就是句法树和序列要一一对应,不能存在两个句法树对应同一个序列,否则的话预测出来一个序列可能解码出两棵句法树,那就尴尬了),当然要是还满足满射性就最好了(也就是对于每一个序列,最好都能找到一棵句法树与之对应,不然预测出一个序列无法找到对应的句法树也很尴尬),当然找不到也没事,后文有解决方法。
的序列。并且该映射函数还得满足一定的条件,首先它一定得是一个函数(也就是对于所有的句法树,都得找到一个对应的序列),然后这个函数还得有单射性(也就是句法树和序列要一一对应,不能存在两个句法树对应同一个序列,否则的话预测出来一个序列可能解码出两棵句法树,那就尴尬了),当然要是还满足满射性就最好了(也就是对于每一个序列,最好都能找到一棵句法树与之对应,不然预测出一个序列无法找到对应的句法树也很尴尬),当然找不到也没事,后文有解决方法。 。这个映射就通过序列标注的LSTM来实现了,
。这个映射就通过序列标注的LSTM来实现了,  就是LSTM的参数。
就是LSTM的参数。 将输入句子转化为对应的句法树。那么
将输入句子转化为对应的句法树。那么  没什么好说的,就是一个序列标注模型,下面重点就是介绍如何设计函数
没什么好说的,就是一个序列标注模型,下面重点就是介绍如何设计函数  。
。 ,分配给它一个二元label
,分配给它一个二元label  ,其中
,其中  为单词
为单词  的CA数量,
的CA数量,  为它俩的LCA的label。
为它俩的LCA的label。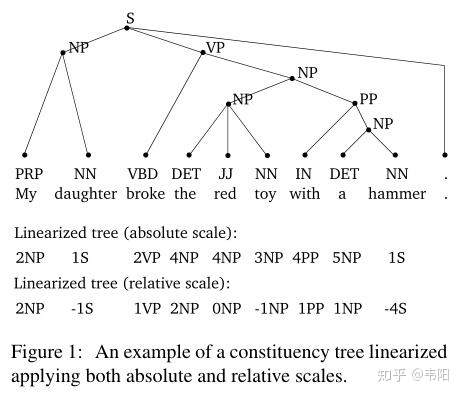
 叉树编码:如果句法树所有产生式全部是
叉树编码:如果句法树所有产生式全部是  到根结点路径的长度比
到根结点路径的长度比  到根结点路径长度少
到根结点路径长度少  个结点。大致结构如下图所示(图画的丑,不要介意):
个结点。大致结构如下图所示(图画的丑,不要介意):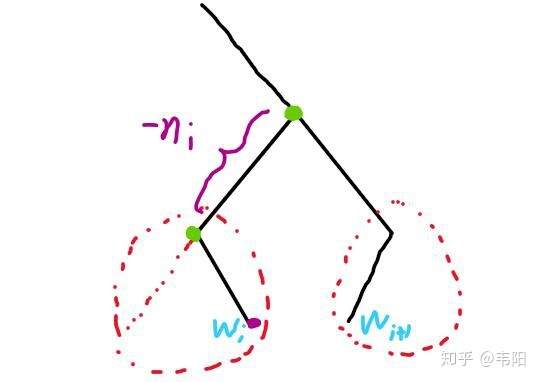
 这棵子树接在了从
这棵子树接在了从  到根结点路径上的第
到根结点路径上的第  个结点上。但是
个结点上。但是  与
与 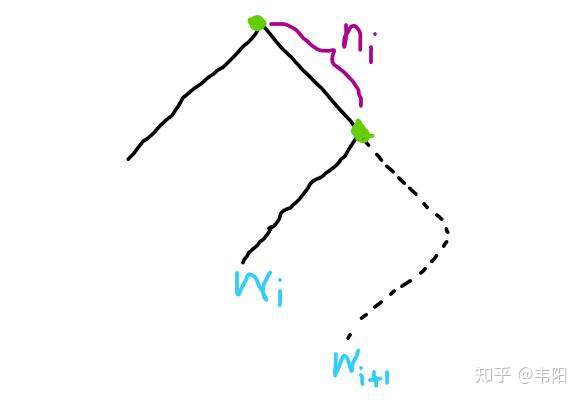
 个结点处。同样也无法确定它的准确位置,但是它所在的子树确定了从这分叉出去的。
个结点处。同样也无法确定它的准确位置,但是它所在的子树确定了从这分叉出去的。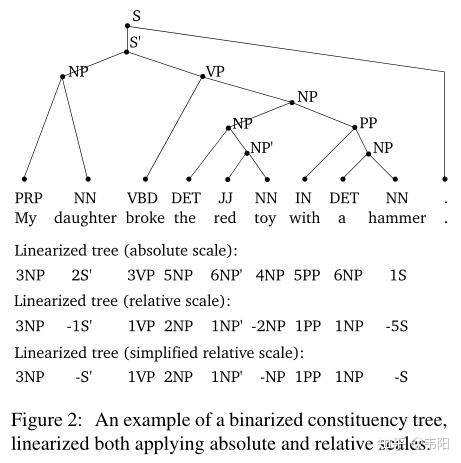
 作为它们的label。
作为它们的label。 表示第
表示第  个叶子结点,那么句法树可以表示成如下的括号表达式:
个叶子结点,那么句法树可以表示成如下的括号表达式:
 形式肯定是
形式肯定是 ![[)]^*[(X]^*](https://img5.php1.cn/3cdc5/935d/3b4/37269d9ad8d2ac83) ,因为如果存在一个闭合的括号对,那么中间肯定还存在着一个叶子结点,这显然不可能。所以我们可以用
,因为如果存在一个闭合的括号对,那么中间肯定还存在着一个叶子结点,这显然不可能。所以我们可以用  来替代
来替代 ![[)]^*](https://img5.php1.cn/3cdc5/935d/3b4/de9387e90eb6cb71) ,用
,用  来替代
来替代 ![[(X]^*](https://img5.php1.cn/3cdc5/935d/3b4/f63d16da017db936) ,将
,将  ,括号表达式可以重写为:
,括号表达式可以重写为:
 替换
替换  ,得到序列:
,得到序列:
![[(X]^*(\bullet_i)](https://img5.php1.cn/3cdc5/935d/3b4/f63d16da017db936%28%5Cbullet_i%29) 和
和 ![(\bullet_i)[)]^*](https://img5.php1.cn/3cdc5/935d/3b4/7d858ea49c673b02%5B%29%5D%5E%2A) 中的一个。因为如果两个都含有的话,说明存在
中的一个。因为如果两个都含有的话,说明存在  这种一元产生式,但是因为一元产生式都提前处理过了,所以不可能存在。
这种一元产生式,但是因为一元产生式都提前处理过了,所以不可能存在。 ,如果
,如果  ,如果右边有
,如果右边有  。如果将这些值写成序列:
。如果将这些值写成序列:
 ,其中第三个元素就是每个叶子结点的label。
,其中第三个元素就是每个叶子结点的label。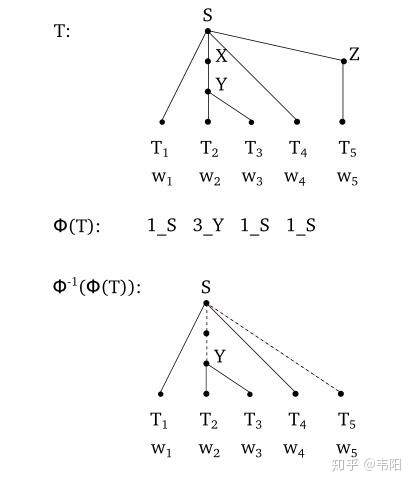









 京公网安备 11010802041100号
京公网安备 11010802041100号