什么是缓存?
缓存(Web缓存)是指代理服务器和客户端本地磁盘保存的资源副本。当 web 缓存发现请求的资源已经被存储,它会拦截请求,返回该资源的拷贝,而不会去源服务器重新下载。
缓存大致可以分为私有缓存和公有缓存。私有缓存只提供给单独用户使用,公有缓存可以多个用户都访问使用。除了使用浏览器和代理缓存,还有网关缓存、CDN、反向代理缓存和负载均衡器等部署在服务器上。这里主要说浏览器和代理缓存器。
控制缓存的方式也不只使用HTTP首部,但是其他方式使用的不多,这里只介绍首部控制。
(公有)代理缓存
通常也叫代理缓存。缓存服务器是代理服务器的一种,并归类在缓存代理类型中。当代理转发从服务器返回的响应时,代理服务器将会保存一份资源的副本。
(私有)客户端的缓存
缓存不仅可以存在于缓存服务器中,还可以存在客户端浏览器中。
Web浏览器有内建的私有缓存——大多数浏览器都会将常用文档缓存在个人电脑的磁盘或者内存中,并且允许用户去配置缓存的大小和各种设置。
缓存操作的目标
常见的HTTP缓存只能存储GET响应。
- 一个检索请求的成功响应:对于GET请求,响应状态码为200
- 永久重定向:响应状态码301
- 错误响应:响应状态码404的一个页面
- 不完全的响应:响应状态码206,只返回局部的信息
- 除了GET请求外,如果匹配到一个一杯定义的cache键名的响应
缓存的处理过程
一下是对一条HTTP GET报文的基本缓存处理过程,这里例子是一个新鲜命中的缓存。
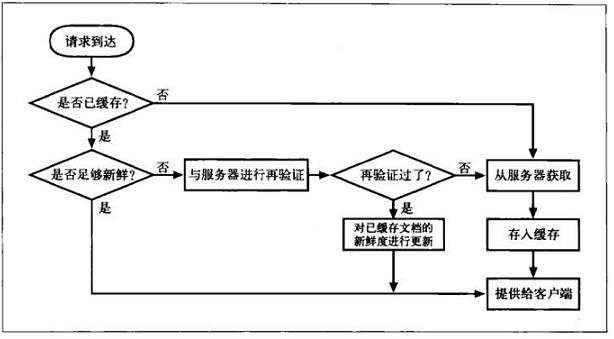
图片来自《HTTP权威指南》
- 接收——缓存从网路中读取抵达的请求报文
- 解析——缓存对报文进行解析,提取出URL和各种首部
- 查询——缓存查看是否有本地副本可用,如果没有,去获取并缓存。已缓存对象中包含了服务器响应主体和原始服务器响应首部,这样就会在缓存命中时返回正确的服务器首部。
- 新鲜度检测——缓存查看已缓存的副本是否新鲜,如果是,使用缓存响应客户端的请求。如果不是,询问服务器再验证缓存的有效性。这里涉及两个很重要的内容:新鲜度和验证机制,分别对应HTTP协议中规定的过期制度(Expiration Model)和验证机制(Validation Model)。涉及的首部字段:Cache-Control(must-revalidate和max-age等)、Expires、Last-Modified、Etag等。
- 创建响应——缓存使用已缓存响应的首部作为响应首部的起点,对这些首部进行修改和扩充。(关于使用缓存构建响应的详细细节可以去RFC文档中查看)有可能为了与客户端匹配,修改http版本。已缓存响应的end-to-end首部被用来构造响应,比如新鲜度信息Cache-Control、Age以及Expires等。通常还会包含一个Via首部说明请求由代理缓存提供。
- 发送——缓存通过网络将响应发回给客户端
- 日志——缓存可选地创建一个日志文件条目来描述这个事务
缓存的控制
服务器通过HTTP定义的几种方式来指定文档过期之前可以将其缓存多久。按照优先级递减的顺序,服务器可以:
- 附加一个Cache-Control: no-store首部到响应中;
- 附加一个Cache-Control:no-cache首部到响应中;
- 附加一个Cache-Control:must-revalidate首部到响应中;
- 附加一个Cache-Control:max-age首部到响应中;
- 附加一个Expires日期首部到响应中;
- 不附加过期信息,让缓存确定自己的过期日期
no-store:主要用于敏感信息,在请求或者响应中明确的要求不要缓存内容。
no-cache:标识为no-cache的响应可以缓存。但是在使用缓存之前必须向源服务器验证其有效性。(标识为no-cache的请求,标识客户端不会接收缓存过的响应)
must-revaliable:标识为must-revaliable的响应告诉缓存,必须跟源服务器验证有效性。
max-age:从服务器将文档传来之时,可以认为文档处于新鲜状态的秒数。
Expires:指定一个绝对时间,在指定时间之前文档是新鲜的。(不推荐,因为绝对时间没有考虑时差等等因素)
新鲜度(过期时间)
服务器用HTTP/1.0+的Expires首部或HTTP/1.1的Cache-Control: max-age响应首部来指定过期日期,同时还会带有响应主体。Expires首部和Cache-Control: max-age首部所做的事情本质上是一样的,但由于Cache-Control首部使用的是相对时间而不是绝对日期,所以我们更倾向于使用比较新的Cache-Control首部。

如果Cache-Control和Expires同时存在,Cache-Control优先级更高。
如果首部不存在Cache-Control和Expires,则查找是否存在Last-Modified,如果有,缓存的寿命就等于头里面Date的值减去Last-Modified的值除以10(注:根据rfc2626其实也就是乘以10%)。
缓存失效时间计算公式如下:
expirationTime = responseTime + freshnessLifetime - currentAge
上式中,responseTime 表示浏览器接收到此响应的那个时间点。
加速资源
对于设置了较长缓存时间的资源,一旦想要更新,会有些困难。网页上引入js/css文件,当它们变动时需要尽快更新线上资源。
web开发者发明了一种被 Steve Souders 称之为 revving 的技术。不频繁更新的文件会使用特定的命名方式:在URL后面(通常是文件名后面)会加上版本号。加上版本号后的资源就被视作一个完全新的独立的资源,同时拥有一年甚至更长的缓存过期时长。但是这么做也存在一个弊端,所有引用这个资源的地方都需要更新链接。web开发者们通常会采用自动化构建工具在实际工作中完成这些琐碎的工作。当低频更新的资源(js/css)变动了,只用在高频变动的资源文件(html)里做入口的改动。
……具体细节待续
再验证(校验)
如果文档过期,并不意味着文档与实际文档有区别。只意味着缓存需要向源服务器验证文档的有效性。如果文档确实发生了改变,缓存将获取新的文档替换旧的缓存。如果文档未发生变化,缓存只需要换取新的首部,更新缓存对象的首部。
如何高效的实现再验证呢?HTTP条件方法,允许发送一个“条件GET”,只有服务器文档与缓存文档不同时,才会返回对象主体。
HTTP定义了5个条件请求首部。对缓存再验证来说最有用的2个首部是If-Modified-Since和If-None-Match。

If-Modified-Since后面可以跟Date或者Last-Modified等日期。如果未发生变化,返回304,如果发生了变化,返回带有新实体的200响应。
If-None-Match:Etag。如果Etag发生变化,返回带有新实体的200响应。如果未发生变化,返回304。
两种方法的选择:服务器响应首部有Etag,则缓存使用If-None-Match再验证。如果首部有Last-Modofied,则使用If-Modified-Since。由于Etag是http1.1才有的,如果两种验证都存在,就可以同时保证http1.0和http1.1都可以进行验证。
如果HTTP/1.1缓存或服务器收到的请求既带有If-Modified-Since,又带有实体标签条件首部,那么只有这两个条件都满足时,才能返回304 Not Modified响应。
Vary响应首部
代理服务器接收到源服务器返回的包含Vary指定项的响应之后,仅对请求中含有相同Vary指定首部字段的请求返回缓存。即使对相同的资源发出请求,如果Vary不一致,就必须从源服务器获取资源。
使用vary头有利于内容服务的动态多样性。例如,使用Vary: User-Agent头,缓存服务器需要通过UA判断是否使用缓存的页面。如果需要区分移动端和桌面端的展示内容,利用这种方式就能避免在不同的终端展示错误的布局。
关于强制缓存和协商缓存
网上直接baidu浏览器缓存会出现一大堆文章都是关于浏览器缓存分为强制缓存和协商缓存的。看了RFC文档以及MDN相关文章,根本没有出现这两个单词。之所以自己重新整理一篇文章主要是因为想要弄清楚缓存的原理,以及浏览器到底充当了什么角色,再就是确定强制缓存和协商缓存这两个概念到底是什么。
所谓的强制缓存和协商缓存,只是HTTP首部的不同字段对应的不同功能。浏览器作为用户代理,处理HTTP请求和响应时根据HTTP首部采取不同的措施,本质上是由HTTP规范决定了浏览器采取哪些行动,并且非浏览器的用户代理也会采取相同的措施,并且浏览器本身的功能分类。
所以我觉得这两个概念并不好,突兀的告诉你,浏览器的缓存有两个分类,对于概念的记忆和使用没有多少好处。明白整个网络通信过程,以及缓存在其中的工作细节,才是关键。
参考
- 《图解HTTP》
- 《HTTP权威指南》
- RFC2616 (网上有很多翻译的版本)
- HTTP缓存-MDN
- caching Tutorial





 京公网安备 11010802041100号
京公网安备 11010802041100号