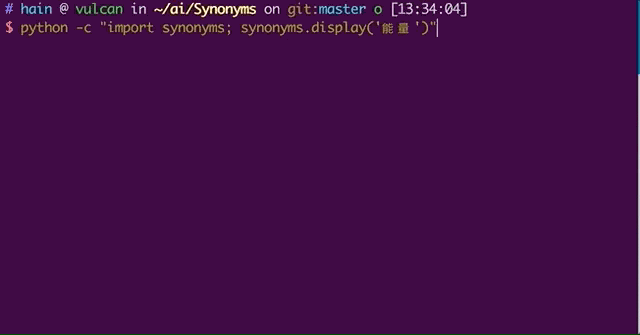
该中文近义词工具包采用的基本技术是Word2vec,因此在介绍该工具的同时我们会简要介绍词嵌入方法。此外,Synonyms的安装十分便捷,我们可以直接使用命令pipinsta
中文同义词工具包的基础技术是Word2vec,所以在介绍这个工具的同时,我们会简单介绍一下单词嵌入的方法。另外,安装同义词非常方便,我们可以直接使用命令pip install -U安装同义词。该工具包兼容Python 2和Python 3,目前稳定版本为v2.0以下是使用同义词工具的效果:
如果我们想将单词输入到机器学习模型中,我们需要将单词转换成一些数字向量,除非我们使用基于树的方法。一种直接的方法是使用“一热编码”方法将单词转换成稀疏表示。如下所示,向量中只有一个元素被设置为1,其余的都是0。

这种方法的缺点是一个词的向量长度等于词汇量的大小,而且非常稀疏。不仅如此,这种方法剥离了单词的所有局部上下文,我们无法用向量来表达单词的概念。因此,我们需要使用一种更高效的方法来表示文本数据,这种方法可以保存单词的上下文信息。这就是Word2Vec方法的初衷。
一般来说,Word2Vec方法由两部分组成。首先,将zxdsb one-hot形式表达的词映射到低维向量中。例如,将10,000列的矩阵转换为300列的矩阵称为单词嵌入。第二个目标是保留单词的上下文,同时在一定程度上保留其含义。Word2Vec可以通过skip-gram和CBOW来实现这两个目标。skip-gram将输入一个单词,然后尝试估计单词附近出现其他单词的概率。相反,有一种连续词包(Continuous Bag Of Words,CBOW)模型,它以一些上下文词作为输入,通过评估概率找出最适合上下文(概率最高)的词。
对于连续词包模型,Mikolov等人在目标词前后使用N个词来同时预测该词。他们把这个模型叫做连续词包(CBOW),因为它用连续的空间来表示词,这些词的顺序并不重要。
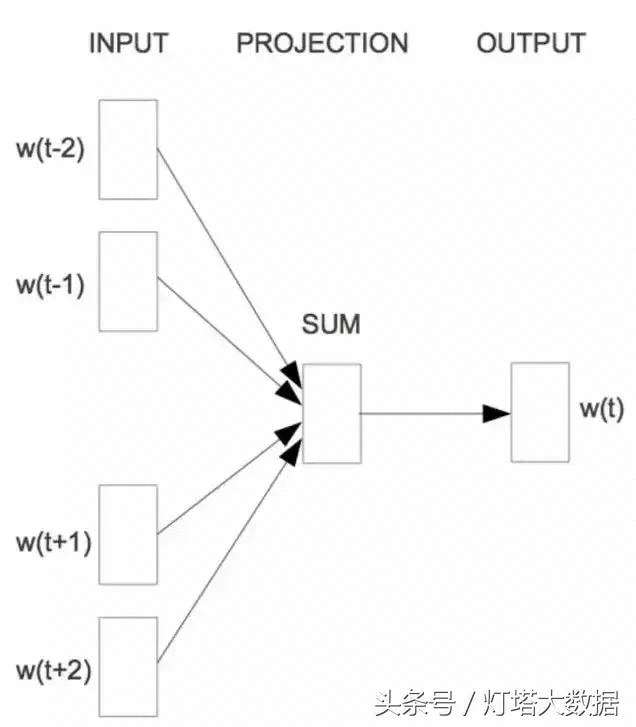
连续词袋(Mikolov等人,2013年)
CBOW可以看作是一个带有先知的语言模型,而skip-gram模型则彻底改变了语言模型的目标:它不像CBOW那样从周围的词中预测中间词;相反,它使用词头来预测周围的单词:
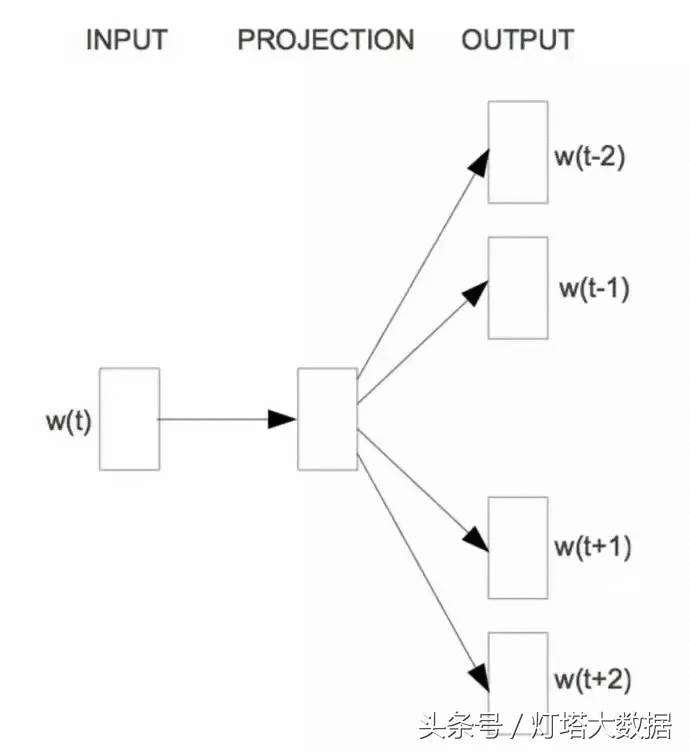
Skip-gram(Mikolov等人,2013年)
在加载同义词中,我们可以看到“从.加载(125796,100)矩阵”会被打印出来,所以同义词采用的词向量维数是100。
使用
输出同义词向量:
导入同义词sprint ('face : %s'%(同义词)附近(' face')) print ('identify 3360% s'%(同义词。附近('识别'))打印('不存在3360% s '
[[near _ WORds],[near _ WORds _ score]],near _ WORds是单词的同义词向量,也存储在列表中,根据距离长度从近到远排列。邻近词得分是邻近词中对应词的距离得分,得分在(0-1)范围内。比如:
同义词.附近(人脸)=[['图片','图像','通过观察','数字图像','几何图形','人脸','图像','放大镜','人脸',' MII'],[0.597284,0.588] 0.530095,0.525344,0.524009,0.523101,0.516046]]如果有多余的单词,返回[[],[]],当前字典大小为: 125,7994]
机器心试图将一整段关于Word2vec的中文分割成单词,然后使用同义词工具对分割结果取同义词。以下是测试结果:
Wordvec: [[],[]] Method : [['方法','手段','新方法','原则','工具','步骤','算法','分析方法','算法','方法可用'],[0.70
502, 0.657432, 0.656965]]由 : [[], []]两 : [[], []]部分 : [['部份', '大部分', '一小', '其余部分', '外', '大多', '之外', '大部份', '以外', '均'], [0.819274, 0.77532, 0.696557, 0.630384, 0.625031, 0.617763, 0.609703, 0.600958, 0.599957, 0.592684]]组成 : [['构成', '分成', '组合成', '组合而成', '都由', '组建', '分为', '都是由', '成员', '合组'], [0.672614, 0.633627, 0.622906, 0.601468, 0.579645, 0.576105, 0.56926, 0.558928, 0.555657, 0.55275]]。 : [[], []]首先 : [[], []]是 : [[], []]将 : [[], []]zxdsb : [['kadhb', 'wwdhc', '希尔伯特', '庞加莱', '欧拉', '几何', '群论', '图论', '高斯', '线性代数'], [0.585315, 0.570614, 0.52954, 0.507108, 0.503025, 0.501703, 0.49944, 0.496649, 0.495397, 0.488994]]独热 : [[], []]形式 : [['方式', '型式', '性质', '表现形式', '表达方式', '概念', '媒介', '内容', '规则', '简单'], [0.748891, 0.621915, 0.6181, 0.617813, 0.617308, 0.611825, 0.583548, 0.578797, 0.574129, 0.569158]]表示 : [['回应', '指出', '透露', '表达', '声称', '对此', '暗示', '否认', '说明', '问到'], [0.733619, 0.718644, 0.700614, 0.69215, 0.669181, 0.663752, 0.65325, 0.648804, 0.64028, 0.632011]]的 : [[], []]单词 : [['单字', '词语', '短语', '字词', '词根', '词组', '句子', '音节', '词汇', '前缀'], [0.819558, 0.793184, 0.779852, 0.775173, 0.771767, 0.767386, 0.747697, 0.733435, 0.722758, 0.715587]]映射 : [['同构', '拓扑', '等价', '同态', '算子', '流形', '给定', '子集', '函数', '向量'], [0.751925, 0.737796, 0.736626, 0.723419, 0.72286, 0.717205, 0.70084, 0.699233, 0.698332, 0.682505]]成 : [['出', '变成', '成为', '演变成', '变为', '起来', '转成', '形成', '已成', '转变成'], [0.626685, 0.597042, 0.578111, 0.554632, 0.55223, 0.538277, 0.498342, 0.482658, 0.480671, 0.479747]]低 : [['较低', '较高', '高', '更高', '极低', '很低', '低于', '高于', '偏高', '较差'], [0.880493, 0.829336, 0.814844, 0.751234, 0.744953, 0.73976, 0.715566, 0.715089, 0.709287, 0.686807]]维向量 : [[], []]。 : [[], []]例如 : [[], []]将 : [[], []] : [[], []]10 : [[], []], : [[], []]000 : [[], []] 列 : [[], []]的 : [[], []]矩阵 : [['行列式', '乘积', '向量', '乘法', '算子', '特征值', '线性', '函数', 'formula_', '实数'], [0.78328, 0.743294, 0.7416, 0.735933, 0.705292, 0.697315, 0.697315, 0.690086, 0.689624, 0.683013]]转换 : [['切换', '变换', '转换成', '叠加', '匹配', '类比', '传输', '交换', '操作', '简化'], [0.733128, 0.718899, 0.715552, 0.628927, 0.621122, 0.612286, 0.611997, 0.609811, 0.604056, 0.603366]]为 : [[], []] : [[], []]300 : [[], []] 列 : [[], []]的 : [[], []]矩阵 : [['行列式', '乘积', '向量', '乘法', '算子', '特征值', '线性', '函数', 'formula_', '实数'], [0.78328, 0.743294, 0.7416, 0.735933, 0.705292, 0.697315, 0.697315, 0.690086, 0.689624, 0.683013]]。 : [[], []]这个 : [[], []]过程 : [['步骤', '流程', '处理过程', '操作过程', '现实生活', '程序', '机制', '方法', '方式', '每一次'], [0.654057, 0.627095, 0.612206, 0.588535, 0.587763, 0.584512, 0.570078, 0.56342, 0.556587, 0.555285]]被 : [[], []]称为 : [['称作', '称之为', '被称作', '称做', '专指', '统称', '叫作', '叫做', '称呼', '特指'], [0.931905, 0.888719, 0.883803, 0.833798, 0.741266, 0.73327, 0.725112, 0.720903, 0.714699, 0.695307]]词 : [['词语', '该词', '名词', '用法', '词汇', '用语', '含义', '辞汇', '字词', '术语'], [0.865391, 0.833362, 0.817649, 0.810989, 0.79878, 0.752893, 0.741603, 0.730943, 0.727771, 0.725913]]嵌入 : [['映射', '内嵌', '填充', '封装', '插入', '存储', '链接', '浸入', '粘贴', '构造'], [0.640392, 0.630447, 0.618274, 0.60825, 0.604815, 0.59937, 0.566457, 0.55673, 0.554925, 0.554157]]。 : [[], []]第二 : [[], []]个 : [[], []]目标 : [['目的', '最终目标', '能够', '尽可能', '战略目标', '策略', '能力', '远距离', '任务', '必须'], [0.743574, 0.66224, 0.652209, 0.625992, 0.595744, 0.595451, 0.586327, 0.585261, 0.582277, 0.579012]]是 : [[], []]在 : [[], []]保留 : [['保有', '保存', '留存', '沿用', '原有', '延续', '存留', '更改', '恢复', '维持'], [0.741621, 0.70751, 0.695012, 0.667181, 0.644165, 0.609553, 0.57785, 0.558837, 0.55696, 0.554073]]单词 : [['单字', '词语', '短语', '字词', '词根', '词组', '句子', '音节', '词汇', '前缀'], [0.819558, 0.793184, 0.779852, 0.775173, 0.771767, 0.767386, 0.747697, 0.733435, 0.722758, 0.715587]]上下文 : [['语义', '语句', '字符串', 'codice_', '句子', '正则表达式', '变量', '表达式', '子句', '自然语言'], [0.777081, 0.745407, 0.737112, 0.710487, 0.706909, 0.700924, 0.693529, 0.688357, 0.682883, 0.678303]]的 : [[], []]同时 : [[], []], : [[], []]从 : [[], []]一定 : [[], []]程度 : [['水平', '因素', '高度', '素质', '层面', '能力', '状况', '相对', '情况', '原因'], [0.643124, 0.635219, 0.627448, 0.624889, 0.619942, 0.602435, 0.599929, 0.598476, 0.596007, 0.594679]]上 : [[], []]保留 : [['保有', '保存', '留存', '沿用', '原有', '延续', '存留', '更改', '恢复', '维持'], [0.741621, 0.70751, 0.695012, 0.667181, 0.644165, 0.609553, 0.57785, 0.558837, 0.55696, 0.554073]]其 : [[], []]意义 : [['涵义', '含义', '意涵', '内涵', '象征意义', '本质', '含意', '意味', '概念', '性质'], [0.784661, 0.767263, 0.758177, 0.749875, 0.734564, 0.730683, 0.671735, 0.670497, 0.666011, 0.658259]]。 : [[], []]
两个句子的相似度比较:
sen1 = "发生历史性变革" sen2 = "发生历史性变革" r = synonyms.compare(sen1, sen2, seg=True)
其中,参数 seg 表示 synonyms.compare 是否对 sen1 和 sen2 进行分词,默认为 True。返回值:[0-1],并且越接近于 1 代表两个句子越相似。
旗帜引领方向 vs 道路决定命运:0.429
旗帜引领方向 vs 旗帜指引道路:0.93
发生历史性变革 vs 发生历史性变革:1.0
句子相似度准确率
在 SentenceSim 上进行测试:
SentenceSim 地址:https://github.com/fssqawj/SentenceSim/blob/master/dev.txt
测试语料条数为:7516条.
设定阈值0.5:
相似度>0.5,返回相似;
相似度<0.5,返回不相似.
评测结果:
正确:6626,错误:890,准确度:88.15%
关于距离计算和阀值选取,参考 Synonyms/issues/6。
以友好的方式打印近义词,方便调试,display 调用了 synonyms#nearby 方法:
>>> synonyms.display("飞机")
'飞机'近义词:
1.架飞机:0.837399
2.客机:0.764609
3.直升机:0.762116
4.民航机:0.750519
5.航机:0.750116
6.起飞:0.735736
7.战机:0.734975
8.飞行中:0.732649
9.航空器:0.723945
10.运输机:0.720578
最后,Synonyms 项目的作者bbdxyz是北京邮电大学研究生,目前实习于今日头条 AI LAB。从事自然语言处理方向研究,在智能客服,知识图谱等领域都有相关研究开发经验。研发模型在文体分类权威数据集 TREC 上达到目前最优精度,申请深度学习与自然语言处理结合的国家发明专利 5 项。

@online{Synonyms:hain2017,
author = {Hai Liang Wang, Hu Ying Xi},
title = {中文近义词工具包Synonyms},
year = 2017,
url = {https://github.com/huyingxi/Synonyms},
urldate = {2017-09-27}
}









 京公网安备 11010802041100号
京公网安备 11010802041100号