作者:morimodomasaaki | 来源:互联网 | 2023-09-10 19:22
Hello大家好,学习二分类变量的Stata操作之后,是不是觉得很简单呀?今天我们就来学一下连续型变量的Stata操作。案例:对两种药物(A药和B药)治疗焦虑性失眠的疗效做meta
Hello大家好,学习二分类变量的Stata操作之后,是不是觉得很简单呀?今天我们就来学一下连续型变量的Stata操作。
案例:对两种药物(A药和B药)治疗焦虑性失眠的疗效做meta分析,结局指标是恢复正常睡眠所需要的天数。在这里假定A是实验组,B是对照组。于是我们开始我们的探索。
1.先在Excel 将数据整理好(数据是自己模拟的)
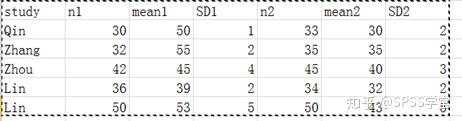
2. 将Excel的数据复制粘贴到Stata12.0:Dataà Data Editorà Data Editor(Edit)
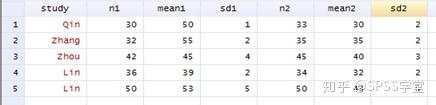
n1: A药组人数
mean1: A药组均数(平均天数)
sd1: A药组标准差
n2: B药组人数
mean 2: B药组均数(平均天数)
sd 2: B药组标准差
逐一核对数据,请不要输错
Study: 命名研究
3. 进行连续变量Meta分析:User àMeta-AnalysisàOf Binary and Continuous (metan)
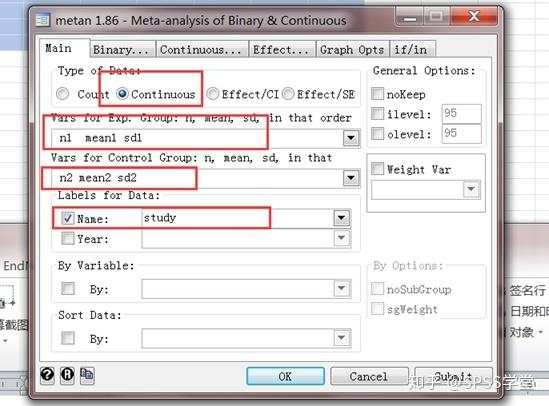
4. 按下图指示填好
因为数据是连续型变量,在数据类型那里选择“continuous”, 然后实验组(A药物组)和对照组(B药物组)分别选择 n1 mean1 sd1,n2 mean2 sd2。
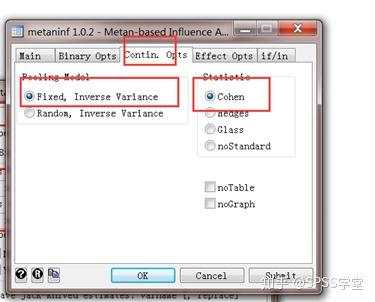
模型效应在这里先选择随机模型,因为数据是自己模拟的,可能有很大的异质性,统计量选择Cohen,因为Cohen是默认的标准化均数的方法。
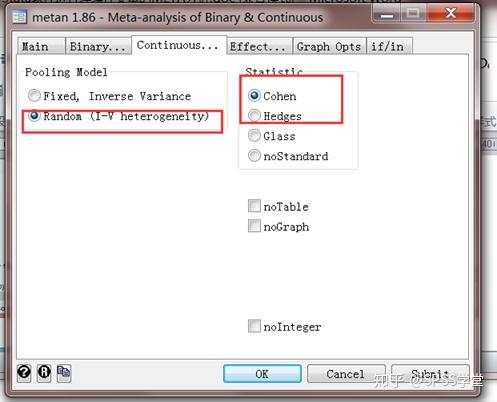
5. 生成森林图
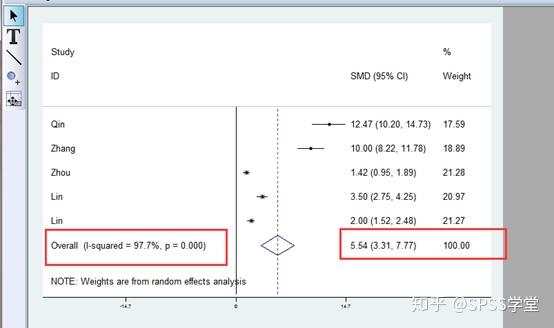
从结果可以看出,异质性I-squared=97.7%远大于50%,因此我们选择的随机效应模型是正确的,如果这里发现异质性较小的话,那么可以重新选择固定效应模型。SMD=5.54,以及95%CI是(3.31,7.77),说明A,B两种药物治疗焦虑性失眠患者恢复正常睡眠的天数不同。
6.漏斗图
(1)User->Meta->Analysis->Funnel Graph,vertical(metafunnel)
(2)数据类型选择Theta,SE, 然后依次选入_ES, _seES,点击OK
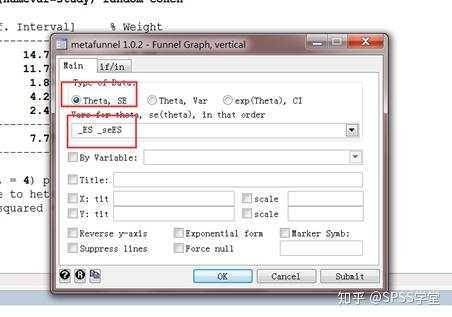
(3)输出结果:
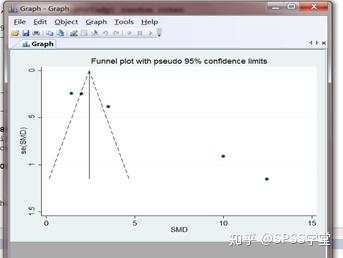
这漏斗图非常不好看,明显存在发表偏倚(具体判断见Meta分析系列之五)但是考虑到数据是自己瞎编的,仅供参考
7.敏感性分析
(1)User->Meta->Analysis->Influence Analysis, metan-based (metaninf)
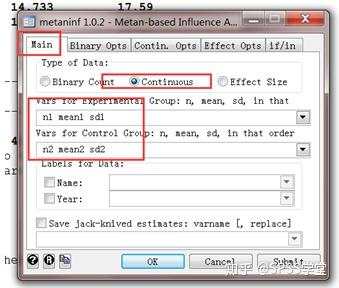
(2)研究类型选择连续 (Continuous),然后依次选入n1, mean1, sd1, n2, mean2, sd2。这次不勾选Name,给大家看看是什么效果。模型和效应量跟上面一致,还是选择随机效应模型,Cohen。点击OK。
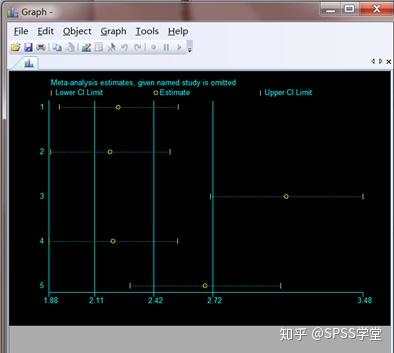
(3)输出结果:
如图,不勾选Name就是只有序号,而没有研究者的名字。第三项研究与其他的研究严重偏离,可能会影响模型的稳健性,进一步的分析可剔除此研究。
下一讲:应用R软件gemtc程序包实现网状Meta分析






 京公网安备 11010802041100号
京公网安备 11010802041100号