摘要:海量数据浪涌促成大数据集群不断升级扩容,为减少数据搬迁、避免跨集群用数,大集群出现是发展的必然。
随着社会各行各业的数字化进程,未来几年,数据将指数级增长。据预测,2025年移动终端设备将达到400亿部,IoT设备将达到25万亿个。全球每天产生的数据量更将从2018年的33ZB快速增长到2025年的180ZB。例如,每辆自动驾驶汽车每天产生的数据量约为64TB,按照每台服务器存储120T有效数据来计算,意味着每辆汽车每天产生的数据就需要消耗0.5台服务器存储空间;再比如,某城市200万摄像头,每天产生的数据量为80PB,意味着每天需要消耗的服务器数量为130台。
这些变化都为数据存储、计算、分析和安全等带来全新的挑战和需求:
第一点:数据量的快速增长,意味着Hadoop原生态2000节点的集群规模已经无法满足数据存储需求,更大规模的集群节点,更大的存储容量,以及与之匹配的计算性能,成为大数据发展的趋势之一;
第二点:数据的多样性含义也得到了扩展,从最初的数据类型的多样性,扩大到数据分布的多样性、数据使用方式的多样性,批处理、流处理、实时检索、交互式分析多种数据使用方式融合,才能满足用户业务场景的需求;
第三点:虽然大数据强调快速,但并不意味着时效性就好。把数据从数据源集成到大数据集群通常都需要经历几个步骤,包括:通过工具把数据库的数据转化为文件,通过数据集成工具把文件批量加载到大数据集群,从数据的产生到数据消费,时效性通常是T+1,这对“反欺诈”、“实时预警”等时效性要求高的业务,带来了风险。
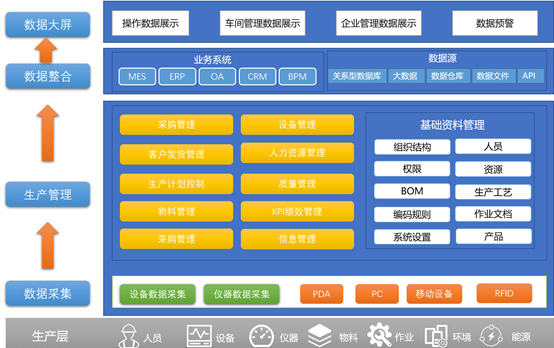
华为云FusionInsight MRS大数据就是在不断理解客户场景需求,感受客户使用痛点,积累丰富经验,打造领先的解决方案。
华为云FusionInsight解决方案首席架构师洪福成
大集群:支持单集群2万节点,树立行业新标杆
海量数据浪涌促成大数据集群不断升级扩容,为减少数据搬迁、避免跨集群用数,大集群出现是发展的必然,其需求主要表现在被动、主动、自我驱动三个方面。
- 被动因数:数据量爆发式增长,存储空间需求急剧增长;
- 主动因数:多数据融合在一个数据湖内,消除数据孤岛;
- 自我驱动:跨部门、跨业务融合分析,业务创新。
面对政企对大集群的需求,华为云FusionInsight给出了完美解决方案,华为云FusionInsight MRS通过以下四个关键要素实现单集群突破2万节点,树立行业新标杆:
首先,华为自研Superior超级调度器,性能相比开源提升20+倍,可以调度2万+节点规模;
其次,FusionInsight MRS支持数据跨机房、跨DC分布,并且计算任务和数据采用NDP原则就近计算,尽量避免数据跨DC流动,解决机房空间不足问题;
再次,FusionInsight MRS支持滚动升级,运用Hadoop多数据备份,多服务器分布的特点,在升级软件时,分批次、小规模地进行升级和重启,直到整个集群完成升级,业务也不会出现中断。
最后,在HDFS文件目录、元数据缓存、管理信息等方面也做了大量的优化和实践,2020年6月,MRS 2万节点大集群通过信通院测试,性能和稳定性均表现优良,树立了行业新标杆。
湖仓一体:批处理和交互式查询融合, “0”数据搬移
在分析型场景,大数据擅长做批处理加工和离线分析,对时延存在较大的容忍空间。数据仓库擅长做交互式分析,在数据存储容量和数据加工方面存在成本高的问题。因此,传统的做法是把大数据和数据仓库组合起来,大数据存储大量的明细数据,并执行批处理加工任务;然后把加工的结果数据(专题数据),通过工具加载到另外一个数据仓库集群,对外进行高性能交互式分析。这种方案存在查询慢、效率低、成本高等三大难题。
FusionInsight MRS通过湖仓一体的解决方案完美解决上述问题。在湖仓一体解决方案中,数据在同一HDFS存储层内部闭环,数据加工和分析不出湖,数据“0”搬迁;Hive批加工引擎和HetuEngine交互式查询引擎基于YARN进行统一资源调度,资源利用率高,成本更低;MRS构建了多租户体系,可以为Hive加工、HetuEngine交互式分析配置不同的租户,实现多部门业务并行处理,安全性和可扩展性较好。
实时数据湖:数据T+0实时入库、消费、分析
面对传统大数据平台在数据存储中遇到的时延问题,华为云FusionInsight MRS提供了实时数据湖解决方案,支持数据T+0实时入库、消费、分析。
引入CarbonData作为新的存储引擎,CarbonData具备2大特点:查询加速和数据更新。
1.通过增加索引提升数据查询效率,通过支持ACID事务,保障数据的Update和数据一致性;通过高性能查询引擎HetuEngine,对CarbonData的数据和索引进行高性能分析;
2.通过Flink或DAYU-CDM来对数据进行实时获取,实时insert或update到CarbonData中。
数据从入库到查询,都采用了最好的方式,确保时延、性能达到最佳。1TB数据从更新到查询,可以在30秒内完成。
一个企业一个湖:集约高效、易管理
部分客户在使用大数据时,还是采用一个业务一个集群的方式来构建,这里既有缺乏统一数据湖规划的因素,也有开源Hadoop单集群无法满足多种业务场景以及安全隔离的因素。在面对海量数据浪涌时,这种独立式集群建设方式暴露出严重的问题,如资源利用率低、分析效率低、运维管理困难等。
华为云FusionInsight MRS领先的解决方案,包括:大集群、湖仓一体、实时数据湖等,使一个企业一个湖成为可能。
数据湖内部全量数据批处理、流处理、交互式多引擎融合,采用YARN做统一资源调度,资源利用率可以提升至90%。同时,采用多租户为不同业务分配不同资源和数据权限隔离,支撑不同的业务需求。
分析效率也极大提升,数据在统一数据湖内,无需跨集群流转,数据流转链路最短,分析效率最高。
此外,作为统一数据湖,软件版本只有一个,也容易进行统一管理。
点击关注,第一时间了解华为云新鲜技术~









![hive和mysql的区别是什么[mysql教程]](https://img1.php1.cn/3cd4a/25047/ae9/df36f34f7ab80f36.jpeg)

 京公网安备 11010802041100号
京公网安备 11010802041100号