这篇文章主要介绍了spring boot整合kafka过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下
一、启动kafka
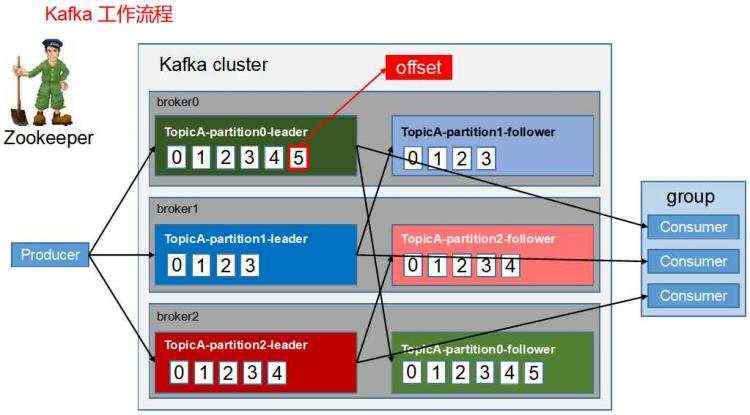
启动kafka之前一定要启动zookeeper,因为要使用kafka必须要使用zookeeper。
windows环境下启动,直接使用kafka自带的zookeeper:
E:\kafka_2.12-2.4.0\bin\windows zookeeper-server-start.bat ..\..\config\zookeeper.properties
接下来启动kafka
E:\kafka_2.12-2.4.0\bin\windows kafka-server-start.bat ..\..\config\server.properties
二、spring boot整合kafka项目实例
1.导入的maven
org.springframework.kafka spring-kafka
配置文件:
server.port=80 #kafka地址,可以有多个 spring.kafka.bootstrap-servers=127.0.0.1:9092 #------生产者配置文件--------- #指定kafka消息体和key的编码格式 spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializer spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer #设置等待acks返回的机制,有三个值 # 0:不等待返回的acks(可能会丢数据,因为发送消息没有了失败重试机制,但是这是最低延迟) # 1:消息发送给kafka分区中的leader后就返回(如果follower没有同步完成leader就宕机了,就会丢数据) # -1(默认):等待所有follower同步完消息后再发送(绝对不会丢数据) spring.kafka.producer.acks=-1 # 消息累计到batch-size的值后,才会发送消息,默认为16384 spring.kafka.producer.batch-size=16384 #如果kafka迟迟不发送消息(这里指的是消息没堆积到指定数量),那么过了这个时间(单位:毫米)开始发送 spring.kafka.producer.properties.linger.ms=1 #设置缓冲区大小,默认是33554432 #这个缓冲区是kafka中两个线程里的共享变量 #这个两个线程是main和sender,main负责把消息发送到共享变量,sender从共享变量拉数据 spring.kafka.producer.buffer-memory=33554432 #失败重试发送的次数 spring.kafka.producer.retries=2 #------消费者配置文件--------- #指定kafka消息体和key的编码格式 spring.kafka.consumer.key-serializer=org.apache.kafka.common.serialization.StringSerializer spring.kafka.consumer.value-serializer=org.apache.kafka.common.serialization.StringSerializer #指定消费者组的group_id spring.kafka.consumer.group-id=kafka_test #kafka意外宕机时,再次开启消息消费的策略,共有三种策略 #earliest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费 #latest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据、 #none:当所有分区都存在已提交的offset时,从offset后开始消费;只要有一个分区不存在已提交的offset,则抛出异常 spring.kafka.consumer.auto-offset-reset=earliest #自动提交offset spring.kafka.consumer.enable-auto-commit=true #提交offset时间间隔 spring.kafka.consumer.auto-commit-interval=100 #消费监听接口监听的主题不存在时,默认会报错因此要关掉这个 spring.kafka.listener.missing-topics-fatal=false
2.创建topic
import org.apache.kafka.clients.admin.NewTopic;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* 使用代码创建的topic
* 三个参数意思:topic的名称;分区数量,新主题的复制因子;如果指定了副本分配,则为-1。
*/
@Configuration
public class KafkaTopic {
@Bean
public NewTopic batchTopic() {
return new NewTopic("testTopic", 8, (short) 1);
}
}
3.生产者代码
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
/**
* kafka生产者代码
*/
@RestController
public class ProductorController {
@Autowired
private KafkaTemplate kafkaTemplate;
@RequestMapping("/test")
public String show() {
kafkaTemplate.send("testTopic", "你好");
return "发送成功";
}
}
4.消费者代码
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.annotation.KafkaListener;
import java.util.Optional;
/**
* kafka消费者代码
*/
@Configuration
public class KafkaConsumer {
@KafkaListener(topics = "testTopic")
public void consumer(ConsumerRecord consumerRecord){
Optional kafkaMassage = Optional.ofNullable(consumerRecord.value());
if(kafkaMassage.isPresent()){
Object o = kafkaMassage.get();
System.out.println("接收到的消息是:"+o);
}
}
}
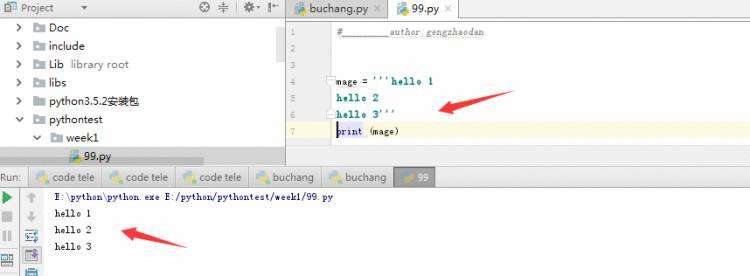
测试结果:

以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持。







 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有 