wordcount-java:
pom.xml文件如下:
junit
junit
3.8.1
test
org.apache.spark
spark-core_2.10
1.3.0
org.apache.spark
spark-sql_2.10
1.3.0
org.apache.spark
spark-hive_2.10
1.3.0
org.apache.spark
spark-streaming_2.10
1.3.0
org.apache.hadoop
hadoop-client
2.4.1
org.apache.spark
spark-streaming-kafka_2.10
1.3.0
package cn.spark.study.core;
import java.util.Arrays;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.api.java.function.VoidFunction;
import scala.Tuple2;
public class WordCount3 {
public static void main(String[] args) {
SparkConf cOnf=new SparkConf().setAppName("WorldCountLocal").setMaster("local");
JavaSparkContext sc=new JavaSparkContext(conf);
JavaRDD lines=sc.textFile("C:\\Users\\wanglonglong\\Desktop\\word.txt");
JavaRDD words=lines.flatMap(new FlatMapFunction() {
@Override
public Iterable call(String t) throws Exception {
// TODO Auto-generated method stub
return Arrays.asList(t.split(" "));
}
});
JavaPairRDD pairs = words.mapToPair(new PairFunction() {
private static final long serialVersiOnUID=1;
@Override
public Tuple2 call(String word) throws Exception {
return new Tuple2(word,1);
}
});
JavaPairRDD wordCounts = pairs.reduceByKey(
new Function2() {
private static final long serialVersiOnUID= 1L;
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
});
wordCounts.foreach(new VoidFunction>() {
private static final long serialVersiOnUID= 1L;
public void call(Tuple2 wordCount) throws Exception {
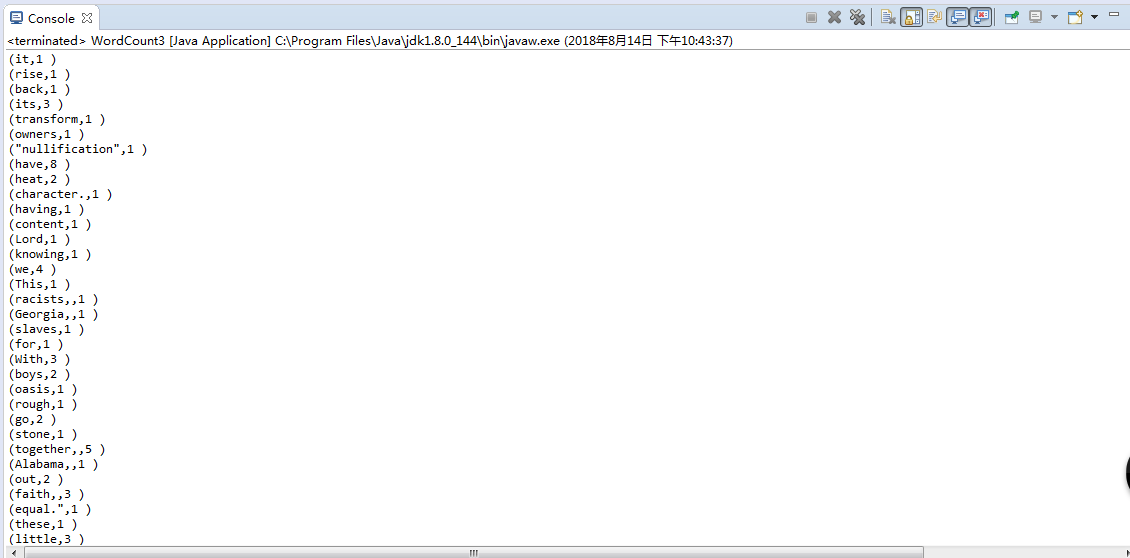
System.out.println("("+wordCount._1 + "," + wordCount._2 + " )");
}
});
sc.close();
}
}












 京公网安备 11010802041100号
京公网安备 11010802041100号