最近就计算与存储分离的一套组合: Spark + OSS的性能进行了调优,取得了一些数据,这里记录一下。我测试的工作负载如下:
这里测试的具体的数据是一个Parquet格式保存的数据,每个数据文件10G左右。Spark集群的配置是每个Executor4C16G, 几十个Executor的一个集群。
计算与存储分离从架构上来说可以让分工更进一步细化: 做计算引擎的专心做计算引擎,做存储的专心做存储;从用户角度来说让用户可以避免Vendor Locked In, 把数据以公开的格式保存在对象存储上, 用户如果什么时候想迁移到其它平台,只要把数据复制走就好了。但是对性能调优也带来了挑战,原本紧密结合的计算和存储被拆开,调优的时候需要通盘考虑。
OSS参数调优
计算跟存储分离之后,很影响速度的一块是从存储拉取数据的速度,开源引擎(Spark, Presto) 在跟这些对象存储(AWS S3, Aliyun OSS)打交道都是通过Hadoop File System的接口, Aliyun OSS也实现了HDFS的接口, 在它的官方文档上暴露了一些可以进行调优的参数: https://hadoop.apache.org/docs/r3.2.0/hadoop-aliyun/tools/hadoop-aliyun/index.html 。
fs.oss.multipart.download.size
从Aliyun OSS读取数据的每个请求获取数据的大小。
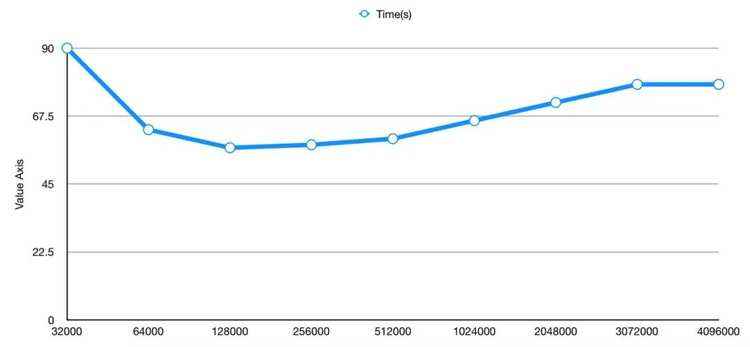
可以看出,在指定的工作负载下 128000 是个最优值,当Download Size小于这个值的时候可能又太多时间花在来回Round Trip上,因此比较耗时,如果Download Size大于这个值的话,单次获取数据花费时间过长,导致后续计算流程饥饿,因此性能会下降(猜测)。
fs.oss.multipart.download.ahead.part.max.number
OSS预读取的个数。
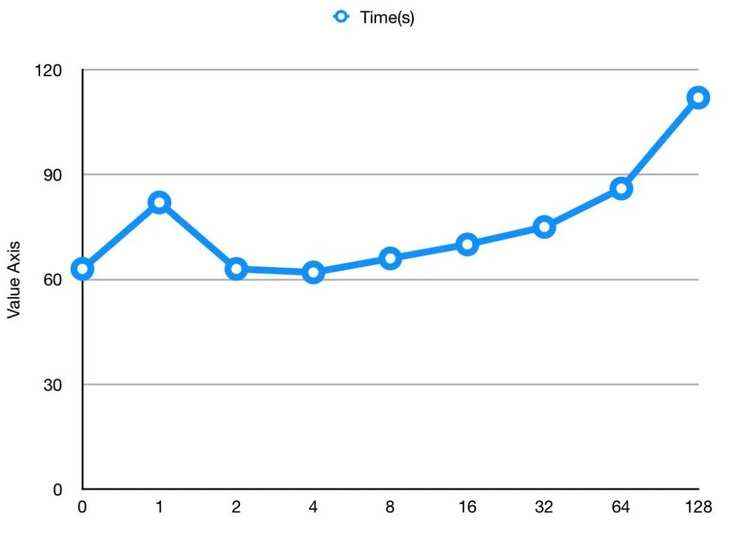
在我的工作负载下,最优值是 4, 在预读取数值过小的时候没有起到预读取的效果,而在预读取数据过多的时候,对于ORC/Parquet这种列存数据,会存在多次seek操作,过多的预读会造成数据浪费和网络阻塞。
fs.oss.multipart.download.threads
OSS同时下载数据的线程数。
2: 68s
4: 62s
8: 64s
16: 62s
32: 64s
如果从平均时间来看,选择不同的线程数性能差距不是太大,但是如果线程数太少(2), 性能确实会比线程数多一点的时候差一点,因为没有充分利用多核的性能。
Spark的性能
spark.sql.files.maxPartitionBytes
这个参数控制Spark任务一个partition的数据量大小。这个参数会影响读取OSS数据的时候产生的Task的个数。
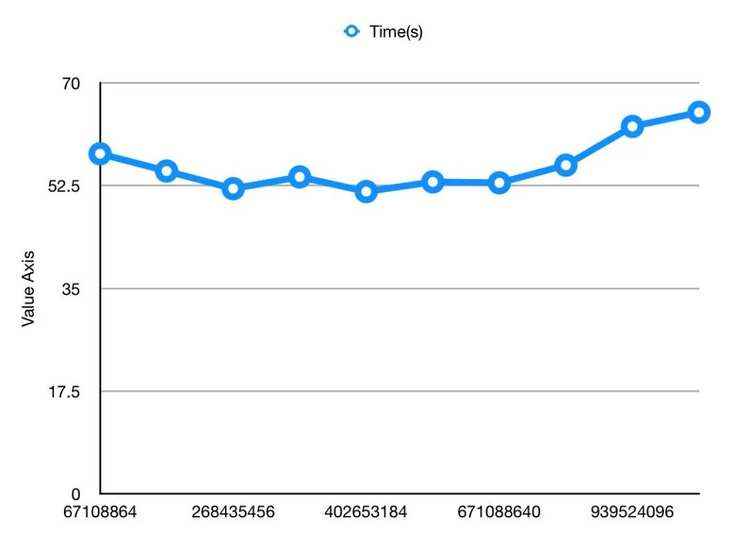
从数据可以看出,134217728 * 3是最优值,Max Partition Bytes太小的时候Task数太多,需要太多轮才能执行完所有的Task;而如果太大前面花过多时间在数据读取上,造成后续计算资源饥饿(猜测)。
总结
这次优化的思路是从底向上,从存储到计算挨个调优,从存储本身的格式,到OSS拉取数据的效率,最后到Spark切分分区的个数。不过这里得到的参数实在特定的负载下进行的测试,不代表它们是通用的最优值。
计算引擎跟Object Store配合工作需要做更多的调优工作,原因在于Object Store其实不是一个真正的文件系统[1],很多在文件系统上很高效的操作在Object Store上面比较低效,比如rename, 在文件系统上面rename一个目录是很轻量级的操作,但是在Object Store上面需要对目录下面每个具体的文件进行rename操作,而每个rename操作背后都可能对应一个http请求,因此把Object Store当做文件系统使用需要做专门的性能调优。比如spark关于写入操作就有一个针对Object Store的优化算法,以减少rename的调用次数: spark.hadoop.mapreduce.fileoutputcommitter.algorithm.version=2[1]。
关于针对Object Store查询的优化,Qubole做过很多事情,主要的优化点是Split Calculation, 在查询开始的初期计算引擎需要获取所有文件的元数据,比如文件大小,以决定哪些文件应该归入一个Split,如果文件比较多的话,这个过程会耗费很多时间,Qubole做的一项优化就是批量获取元信息,大大减少Split Calculation的时间,极端情况下可以优化几十倍。[2][3][4]。
参考资料
Spark: Integration with Cloud Infrastructures
SparkSQL in the Cloud: Optimized Split Calculation
Optimizing Hadoop for S3 – Part 1
Optimizing S3 Bulk Listings for Performant Hive Queries
后记
数据湖开发者社区由 阿里云开发者社区 与 阿里云Data Lake Analytics团队 共同发起,致力于推广数据湖相关技术,包括hudi、delta、spark、presto、oss、元数据、存储加速、格式发现等,学习如何构建数据湖分析系统,打造适合业务的数据架构。
阿里云Data Lake Analytics是Serverless化的交互式联邦查询服务。使用标准SQL即可轻松分析与集成对象存储(OSS)、数据库(PostgreSQL/MySQL等)、NoSQL(TableStore等)数据源的数据。









 京公网安备 11010802041100号
京公网安备 11010802041100号