然后就可以打开Solr Admin的Page进行分词分析了。但当输入中文(华南理工大学)并点击“Analyse Values”进行分析时,会发现如下的错误: TokenStream contract violation: reset()/close() call missing, reset() called multiple times, or subclass does not call super.reset(). Please see Javadocs of TokenStream class for more information about the correct consuming workflow.
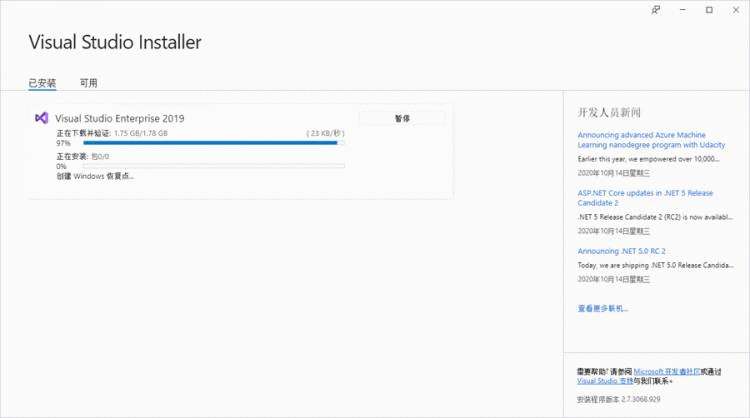
在使用 Visual Studio 2019 时,有时会在创建 Windows 恢复点时遇到卡顿问题。这可能是由于频繁的自动更新导致的,每次更新文件大小可能达到 1-2GB。尽管现代网络速度较快,但这些更新仍可能对系统性能产生影响。本文将探讨该问题的原因,并提供有效的解决方法,帮助用户提升开发效率。 ...
[详细]







 京公网安备 11010802041100号
京公网安备 11010802041100号