Shuffle过程
Hadoop的shuffle过程就是从map端输出到reduce端输入之间的过程shuffle是MR的心脏。
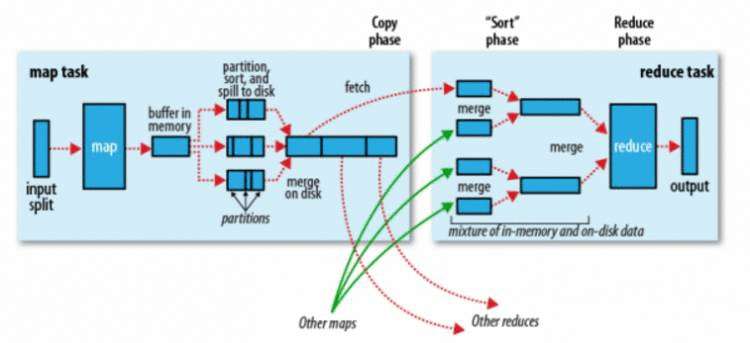
- map 端
当Map程序开始产生结果的时候,并不是直接写到文件的,而是利用缓存做一些排序方面的预处理操作
每个Map任务都有一个循环内存缓冲区(默认100MB, 可改io.sort.mb进行调整),当缓存的内容达到80%时,后台线程开始将内容溢出到(spill)磁盘(linux文件中, 并非hdfs),此时map输出继续写到缓冲区,但如果缓冲区满了,map会被阻塞直到写磁盘过程完成。
写文件使用round-robin(轮询)方式。在写入文件之前,线程先将数据按照Reduce进行分区。对于每一个分区,都会在内存中根据key进行排序,如果配置了Combiner,则排序后执行Combiner(Combine之后可以减少写入文件和传输的数据)
每次结果达到缓冲区的阀值时,都会创建一个文件,在Map结束时,可能会产生大量的文件。在Map完成前,会将这些文件进行合并和排序。如果文件的数量超过3个,则会再次运行Combiner(1、2个文件就没有必要了)
如果配置了压缩,则最终写入的文件会先进行压缩,这样可以减少写入和传输的数据
一旦Map完成,则通知任务管理器,此时Reduce就可以开始复制结果数据
- reduce 端
每个节点的map都将结果写入了本地磁盘中,reduce需要将map的结果通过集群拉取过来,这里要注意的是,需要等到所有map任务结束后reduce才会对map的结果进行拷贝,由于reduce函数有几个复制线程,以至于它可以同时拉取多个map的输出结果。默认的为5个线程(可通过修改配置mapreduce.reduce.shuffle.parallelcopies来修改其个数)
这里有个问题,那么reducers怎么知道从哪些机器拉取数据呢?
当所有map的任务结束后,applicationMaster通过心跳机制(heartbeat mechanism),由它知道mapping的输出结果与机器host,所以reducer会定时的通过一个线程访问applicationmaster请求map的输出结果。
Map的结果将会被拷贝到reduce task的JVM的内存中(内存大小可在mapreduce.reduce.shuffle.input.buffer.percent中设置)如果不够用,则会写入磁盘。当内存缓冲区的大小到达一定比例时(可通过mapreduce.reduce.shuffle.merge.percent设置)或map的输出结果文件过多时(可通过配置mapreduce.reduce.merge.inmen.threshold),将会除法合并(merged)随之写入磁盘。
这时要注意,所有的map结果这时都是被压缩过的,需要先在内存中进行解压缩,以便后续合并它们。(合并最终文件的数量可通过mapreduce.task.io.sort.factor进行配置) 最终reduce进行运算进行输出。







 京公网安备 11010802041100号
京公网安备 11010802041100号