本发明属于自然语言处理技术领域,具体涉及一种从自然语言自动生成python代码的方法。
背景技术:
语义分析任务是自然语言处理领域中的一类任务,主要研究的是如何将给定的自然语言描述文本转换成一种计算机能够理解并且可以执行的一种逻辑表示,比如sql,python,java等形式。传统的方法是根据程序设计语言的特点设计出固定的模板,然后使用模式匹配的方式将自然语言描述解析成模板中的一个个实例。随着深度学习技术的发展,encoder-decoder等深度学习框架也被引入到语义分析分析任务中,比如采用机器翻译的方法将自然描述语言序列直接翻译成编程语言序列,又或者是在生成代码的时候,引入编程语言的语法,先生成程序的抽象语法树,然后再将抽象语法树转换成程序代码。但是上述encoder-decoder模型在处理从自然语言到编程语言之间的转换的时候,encoder和decoder分别处理两种不同语言,由于encoder和decoder使用的神经网络的不同,以及网络的深度,自然语言描述的语义在程序代码生成的过程中会逐步丢失,因此缺少一个强的语义约束的训练模型。
技术实现要素:
针对于上述问题,本发明提出来一种从自然语言自动生成python代码的方法。本发明旨在通过判别器提高生成器根据自然语言描述生成程序片段的效果,学习到自然语言和编程语言的分布之间的联系。
本发明的技术方案是:
一种从自然语言自动生成python代码的方法,步骤如下:
步骤1:采用gan网络的生成器根据自然语言描述生成程序片段的抽象语法树。
生成器是一个encoder-decoder深度学习框架,encoder负责对自然语言描述序列进行编码,decoder则根据encoder的编码结果,将自然语言描述的语义解码成程序片段的抽象语法树。
步骤1.1:采用双向lstm网络作为encoder,对自然语言描述序列进行编码;
步骤1.1.1:从左到右以及从右到左两个方向对自然语言描述序列进行编码,得到每个字符的中间隐藏向量
步骤1.1.2:将中间隐藏向量进行concat操作即为自然语言描述字符的编码向量,并把每个字符的编码向量保存下来,以待后面decoder使用。
步骤1.1.3:将最后一个字符的中间隐藏向量作为decoder的初始状态hend。
步骤1.2:采用单向lstm网络作为decoder,将encoder编码的自然语言语义解码构建为程序的抽象语法树。
这一步骤将编程语言的语法规则引入到生成过程中。以深度优先遍历的方式生成抽象语法树,每一个生成步骤,是对上下文无关文法产生式的应用。语法规则为抽象语法树的生成提供先验知识,缩小搜索空间。
步骤1.2.1:将1.1.3中的hend作为decoder的初始状态,并使用注意力机制计算hend的内容向量,然后将该内容向量作为lstm的输入。
步骤1.2.2:采用softmax对1.2.1的lstm输出结果进行多分类,这些类别分别对应生成抽象语法树的动作。
步骤1.2.3:对于1.2.2生成的抽象语法树的动作,该动作一类是生成叶子节点,该动作另一类是生成非叶子节点。
对于生成非叶子节点的动作来说,是上下文无关文法扩展;而生成叶子节点的动作,则是生成具体的字符,也就是程序片段中的序列字符,可以采用复制的方式从自然语言描述序列中将字符复制过来,也可以根据由模型生成相应的字符。
步骤1.2.4:按照深度优先遍历的方式应用1.2.3的抽象语法树的动作构建抽象语法树。
步骤1.2.5:将1.2.4的输出结果作为1.2.1的输入,重复1.2.1到1.2.4操作,最终得到一棵完整的抽象语法树,即自然语言描述语义对应的程序片段的抽象法树。
步骤1.2.6:将抽象语法树解析成程序片段。
步骤2:采用gan的判别器判断生成器生成的抽象语法树的语义是否与给定的自然语言描述的语义是否一致,这也是对生成器生成的一种强的语义约束。训练判别器的数据分为三种:a训练数据中的自然语言描述和与之对应的程序的抽象语法树。b给定自然语言描述和生成器生成的抽象语法树。c自然语言描述序列和与之无关的程序的抽象语法树。对于训练数据a给定标签为一致,而训练数据b,c给定标签为不一致。
步骤2.1:采用gan生成器中encoder的方法对自然语言描述序列进行编码,这一步只要得到最后的语义向量。
步骤2.2:采用树型lstm网络,自底向上对抽象语法树进行编码,一直编码到抽象语法树的根节点,也就是这个抽象语法树对应的语义向量。
步骤2.3:将2.1和2.2中的自然语言语义向量和抽象语法树的语义向量进行向量乘法。
步骤2.4:重复2.1和2.3,对步骤2中的训练数据b和训练数据c进行同样的操作。
步骤2.5:对2.4中的训练数据对进行二分类预测,及判断这三种情况下自然语言和程序抽象语法树的语义是否一致。
步骤3:训练gancoder,将gan网络的生成器和判别器一起训练。在优化的时候,生成器和判别器交替优化。在训练之前,先分别对生成器和判别器进行预训练,然后再一起博弈训练。
进一步的,由一种从自然语言自动生成python代码的方法生成的模型gancoder包含两个部分:生成器和判别器,其中生成器负责实现从自然语言到编程语言程序片段的生成,而判别器则识别出生成器生成的程序片段。训练的时候,生成器和判别器处于博弈训练的状态,相互提高,到最后判别器不能识别出编程语言程序片段是原始训练集的数据还是由生成器生成的数据。
本发明具备的有益效果:
本发明通过生成对抗网络优化训练,生成一个代码生成系统,该系统可以根据用户给定的对于一个功能的自然语言描述,然后生成一段具有相同功能的程序代码。相较于传统的优化方法,使用生成对抗网络进行对抗博弈训练,生成器能够更有效地学习到自然语言和编程语言的语言模型。
附图说明
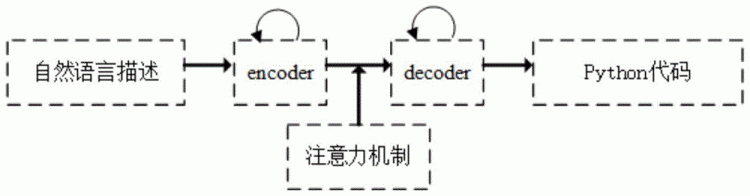
图1是基于encoder-decoder模型的语义分析器。
图2是一个python程序对应的抽象语法树。
图3是本发明gancoder的总体框架。
图4是gancoder的生成器的框架表示图。
图5是使用树型lstm网络对抽象法树进行编码。
具体实施方式
以下结合技术方案和附图详细叙述本发明的具体实施方式。
一种从自然语言自动生成python代码的方法,提出的gancoder系统,总体上是一个生成对抗网络,包含生成器和判别器两个部分,如图3所示。其中生成器是一个encoder-decoder模型,如图4所示,encoder负责对自然语言描述序列进行编码,使用双向lstm网络,而decoder则将encoder编码的语义解码成程序的抽象语法树,使用单向lstm网络;而判别器主要负责判断自然语言描述和抽象语法树的语义是否一致,对于自然语言描述的语义编码使用生成器encoder,对于抽象语法树的编码则采用树型lstm网络,树型lstm网络如图5所示,以自底向上的方式对程序的抽象语法树进行编码,抽象语法树的根节点的编码向量为抽象语法树的语义向量。
步骤1:采用gan网络的生成器根据自然语言描述生成程序片段的抽象语法树。
生成器是一个encoder-decoder深度学习模型,如图4所示,图中左边是encoder,是一个双向lstm网络,负责对自然语言描述序列进行编码;图中右边是decoder,是一个单向lstm网络,它则根据encoder的编码结果,将自然语言描述的语义解码成程序片段的抽象语法树。
步骤1.1:采用双向lstm网络作为encoder,对自然语言描述序列进行编码。图4encoder中左右两个方向表示lstm网络的编码顺序。
步骤1.1.1:从左到右以及从右到左两个方向对自然语言描述序列进行编码,得到每个字符的中间隐藏向量如图4encoder中lstm网络的两个编码方向一样。
步骤1.1.2:将1.1的进行concat操作,得到即为自然语言描述字符的编码向量,并把每个字符的编码向量保存下来,以待后面decoder使用。
步骤1.1.3:将最后一个字符的中间隐藏向量作为decoder的初始状态hend。
步骤1.2:采用单向lstm网络作为decoder,将encoder编码的自然语言语义解码构建为程序的抽象语法树。
这一步骤将编程语言的语法规则引入到代码生成过程中。以深度优先遍历的方式生成抽象语法树,每一个生成步骤,是对上下文无关文法产生式的应用。语法规则为抽象语法树的生成提供先验知识,缩小搜索空间。
步骤1.2.1:如图4,decoder将1.1.3中的hend作为始状态,并使用注意力机制计算hend的内容向量c1,然后将该内容向量作为lstm的输入。
步骤1.2.2:采用softmax对lstm输出结果进行多分类,这些类别分别对应生成抽象语法树的动作,对应如图2中右图抽象语法树的每个节点。
步骤1.2.3:对于1.2.2预测的动作,一类是生成叶子节点,另一类是生成非叶子节点,也就是图2中抽象语法树中叶子节点和非叶子节点。对于生成非叶子节点的动作来说,是上下文无关文法扩展,每一条为上下文文法规则;而生成叶子节点的动作,则是生成具体的字符,也就是程序片段中的序列字符,可以采用复制的方式从自然语言描述序列中将字符复制过来,也可以根据由模型生成相应的字符。
步骤1.2.4:按照深度优先遍历的方式应用1.2.3预测动作构建抽象语法树。图2中的抽象语法树节点用实线箭头表示的顺序为建立抽象语法树中每个节点构建的顺序。
步骤1.2.5:将1.2.4的输出结果作为1.2.1的输入,如图2,上一个节点的信息传递给下一节点,其中信息包括上一步骤的状态,也就是实线箭头表示的,还有父节点的信息,虚线箭头传递的信息。然后重复1.2.1到1.2.4操作,最终得到一棵完整的抽象语法树,即自然语言描述语义对应的程序片段的抽象语法树。
步骤1.2.6:将完整的抽象语法树解析成程序片段。
步骤2:采用gan的判别器判断生成器生成的抽象语法树的语义是否与给定的自然语言描述的语义是否一致,这也是对生成器生成的一种强的语义约束。训练判别器的数据分为三种:1.训练数据中的自然语言描述和与之对应的程序的抽象语法树。2.给定自然语言描述和生成器生成的抽象语法树。3.自然语言描述序列和与之无关的程序的抽象语法树。对于1来说,给定标签为一致,而2,3两种数据,给定标签为不一致。
步骤2.1:采用gan生成器中encoder的方法对自然语言描述序列进行编码,这一步只要得到最后的语义向量,encoder的结构如图4所示。
步骤2.2:采用树型lstm网络,如图5所示,自底向上地对抽象语法树进行编码,抽象语法树的孩子节点是父节点编码的输入,一直编码到抽象语法树的根节点,也就是这个抽象语法树对应的语义向量。
步骤2.3:将2.1和2.2中的自然语言语义向量和抽象语法树的语义向量进行向量乘法。
步骤2.4:重复2.1和2.3,对步骤2中的训练数据2和训练数据3进行同样的操作。
步骤2.5:对2.4中的训练数据对进行二分类预测,及判断这三种情况下自然语言和程序抽象语法树的语义是否一致。
步骤3:训练gancoder,将gan网络的生成器和判别器一起训练。在优化的时候,生成器和判别器交替优化。在训练之前,先对生成器和判别器进行预训练,然后再一起博弈训练,如图3所示,判别器的信息会反馈到生成器。













 京公网安备 11010802041100号
京公网安备 11010802041100号