今天继续介绍分布式系统当中常用的数据结构,今天要介绍的数据结构非常了不起,和之前介绍的布隆过滤器一样,是一个功能强大原理简单的数据结构。并且它的缺点和短板更少,应用更加广泛,比如广泛使用的Redis就有用到它。
SkipList简介
SkipList是一个实现快速查找、增删数据的数据结构,可以做到 O(logN)复杂度的增删查。从时间复杂度上来看,似乎和平衡树差不多,但是和平衡树比较起来,它的编码复杂度更低,实现起来更加简单。学过数据结构的同学应该都有了解,平衡树经常需要旋转操作来维护两边子树的平衡,不仅编码复杂,理解困难,而且debug也非常不方便。SkipList克服了这些缺点,原理简单,实现起来也非常方便。
原理
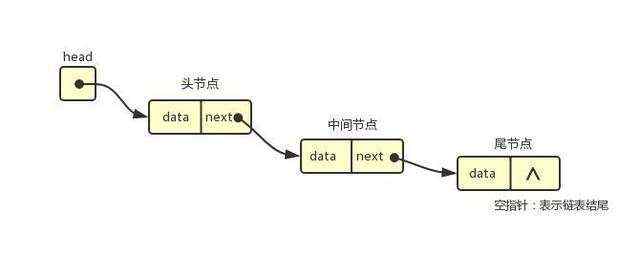
SkipList的本质是List,也就是链表。我们都知道,链表是线性结构的,每次只能移动一个节点,这也是为什么链表获取元素和删除元素的复杂度都是 O(n)。
如果我们要优化这个问题,可以在当中一般的节点上增加一个指针,指向后面两个的元素。这样我们遍历的速度可以提升一倍,最快就可以在 O(n/2)的时间内遍历完整个链表了。
同样的道理,如果我们继续增加节点上指针的个数,那么这个速度还可以进一步加快。理论上来说,如果我们设置log n个指针,完全可以在 log n的时间内完成元素的查找,这也是SkipList的精髓。
但是有一个问题是我们光实现快速查找是不够的,我们还需要保证元素的有序性,否则查找也就无从谈起。但是元素添加的顺序并不一定是有序的,我们怎么保证节点分配到的指针数量合理呢?
为了解决这个问题,SkipList引入了随机深度的机制,也就是一个节点能够拥有的指针数量是随机的。同样这种策略来保证元素尽可能分散均匀,使得不会发生数据倾斜的情况。
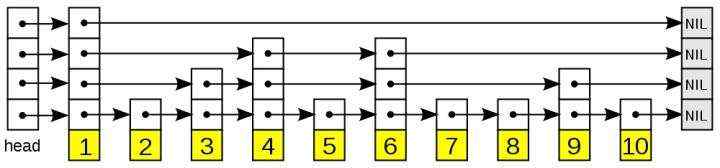
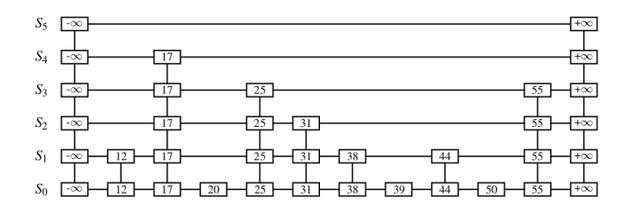
我觉得这个图放出来应该都能看懂,可以把每一个节点想象成一栋小楼。每个节点的多个指针可以看成是小楼的各个楼层,很显然,由于所有的小楼都排成一排,所以每栋楼的每一层都只能看到同样高度最近的一栋。
比如上图当中的2只有一层,那么它只能看到最近的一楼也就是3的位置。4有三层,它的第一层只能看到5,但是第二和第三层可以看到6。6也有三层,由于6之后没有节点有超过两层的,所以它的第三层可以直接看到结尾。
由于每个节点的高度是随机的,所以每个节点能看到的情况是分散的,可以防止数据聚集不平均等问题,从而可以保证运行效率。
实现Node
数据结构的原理我想大家都可以看懂,但是想要上手实现的话会发现还是有些困难,会有很多细节和边界问题。这是正常的,我个人的经验是可以先从简单的部分开始写,把困难的部分留到最后。随着进度的推进,对于问题的理解和解决问题的能力都会提升,这样受到的痛苦最小,半途而废的可能性最低。
在接下来的内容当中,我们也遵守这个原则,从简单的部分开始说起。
定义节点结构
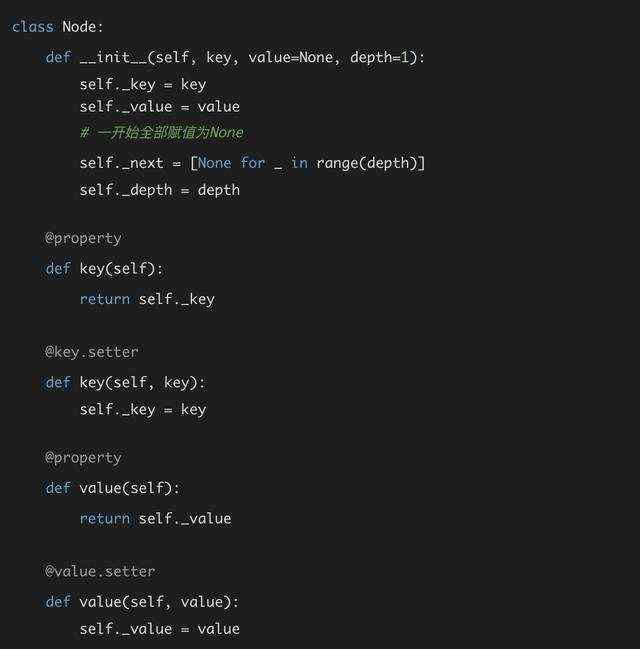
整个SkipList本质是一个链表,既然是链表,当然存在节点,所以我们可以先从定义节点的结构开始。由于我们需要一个字段来查找,一个字段存储结果,所以显然key和value是必须的字段。另外就是每个节点会有一个指针列表,记录可以指向的位置。于是这个Node类型的结构就出来了:
可能会有同学看不明白方法上面的注解,这里做一个简单的介绍。这是Python当中面向对象的规范,因为Python不像C++或者是Java做了public和private字段的区分,在Python当中所有的字段都是public的。显然这是不安全的,有时候我们并不希望调用方可以获取我们所有的信息。所以在Python当中,大家规定变量名前面添加下划线表示private变量,这样无论是调用方还是阅读代码的开发者,都会知道这是一个private变量。
在Java当中,我们默认会为需要用到的private变量提供public的get和set方法,Python当中也是一样。不过Python当中提供了强大的注解器,我们可以通过添加@property和@param.setter注解来简化代码的编写,有了注解之后,Python会自动将方法名和注解名映射起来。比如我们类内部定义的变量名是_key,但是通过注解,我们在类外部一样可以处通过node.key来调用,Python的解释器会自动执行我们加了注解的方法。以及我们在为它赋值的时候,也一样会调用对应的方法。
比如当我们运行: node.key = 3,Python内部实际上是执行了node.key(3)。当然我们也可以不用注解自己写set和get,这只是习惯问题,并没有什么问题。
添加节点方法
我们定义完了Node结构之后并没有结束,因为在这个问题当中我们需要访问节点第n个指针,当然我们也可以和上面一样为_next添加注解,然后通过注解和下标进行访问。但是这样毕竟比较麻烦,尤其是我们还会涉及到节点是否是None,以及是否能够看到tail的等等判断,为了方便代码的编写,我们可以将它们抽象成Node类的方法。
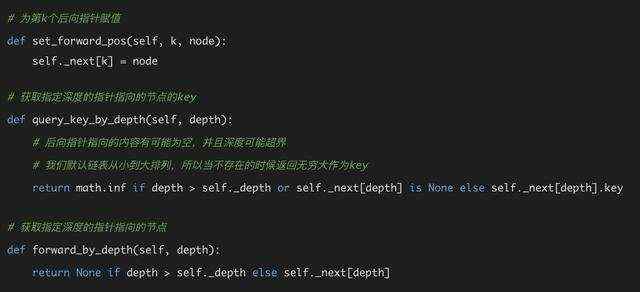
我们在Node类当中添加以下方法:
这三个方法应该都不难看懂,唯一有点问题的是query_key_by_depth这个方法,在这个方法当中,我们对不存在的情况范围了无穷大。这里返回无穷大的逻辑我们可以先放一放,等到后面实现skiplist的部分就能明白。
把这三个方法添加上去之后,我们Node类就实现好了,就可以进行下面SkipList主体的编写了。
实现SkipList
接下来就到了重头戏了,我们一样遵循先易后难的原则,先来实现其中比较简单的部分。
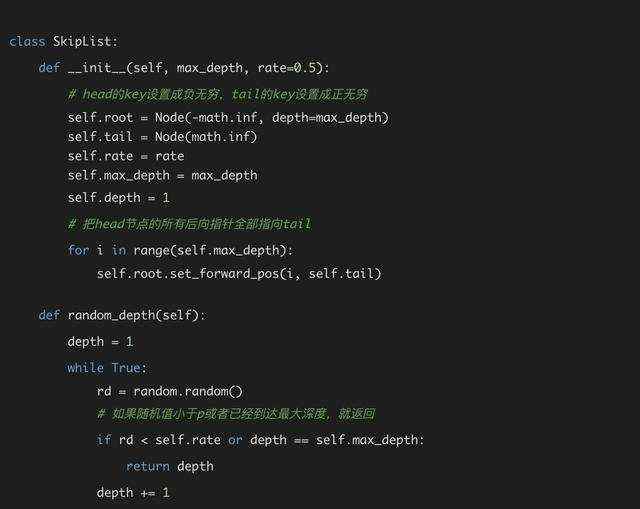
首先我们来实现SkipList的构造函数,以及随机生成节点深度的函数。关于节点深度,SkipList当中会设计一个概率p。每次随机一个0-1的浮点值,如果它大于p,那么深度加一,否则就返回当前深度,为了防止极端情况深度爆炸,我们也会设定一个最大深度。
在SkipList当中除了需要定义head节点之外,还需要节点tail节点,它表示链表的结尾。由于我们希望SkipList来实现快速查询,所以SkipList当中的元素是有序的,为了保证有序性,我们把head的key设置成无穷小,tail的key设置成无穷大。以及我们默认head的后向指针是满的,全部指向tail。这些逻辑理清楚之后,代码就不难了:
到这里,我们又往前迈进了一步,距离最终实现只剩下增删查三个方法了。改和查的逻辑基本一致,并且在这类数据结构当中,一般不会实现修改,因为修改可以通过删除和添加来代替,并且对于大数据的场景而言,也很少会出现修改。
query方法
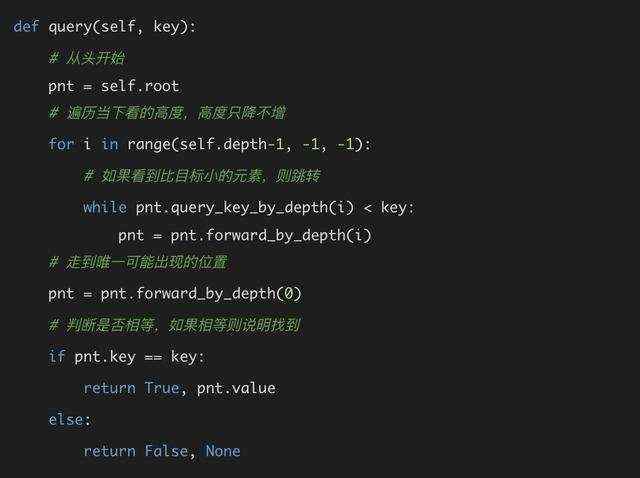
这三个方法当中,query是最简单的,因为我们之前已经理解了查找的逻辑。是一个类似于贪心的算法,说起来也很简单,我们每次都尝试从最高的楼层往后看,如果看到的数值小于当前查找的key,那么就跳跃过去,否则说明我们一下看得太远了,我们应该看近一些,于是往楼下走,再重复上述过程。
比如上图当中,假设我们要查找20,首先我们在head的位置的最高点往后看,直接看到了正无穷,它是大于20的,说明我们看太远了,应该往下走一层。于是我们走到4层,这次我们看到了17,它是小于20的,所以就移动过去。
移动到了17之后,我们还是从4层开始看起,然后发现每一层看到的元素都大于等于20,那么说明17就是距离20最近的元素(有可能20不存在)。那么我们从17开始往后移动一格,就是20可能出现的位置,如果这个位置不是20,那么说明20不存在。
这个逻辑应该很好理解,结合我们之前Node当中添加的几个工具方法,代码只有几行:
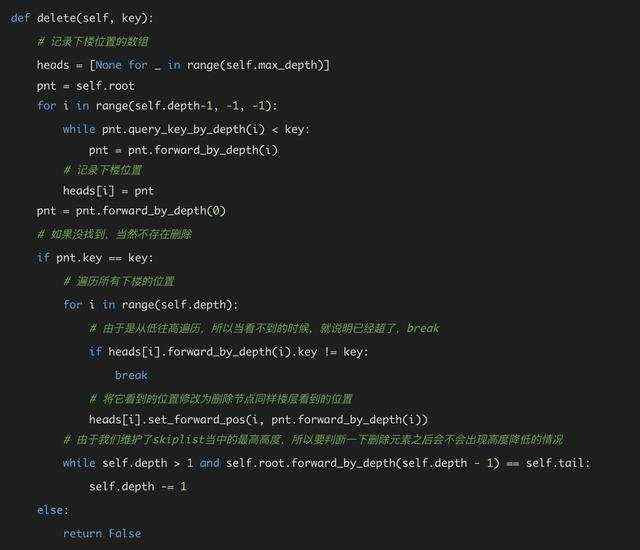
delete方法
query方法实现了,delete就不远了。因为我们要删除节点,显然需要先找到节点,所以我们可以复用查找的代码来找到待删除的节点可能存在的位置。
找到了位置并不是一删了之,我们删除它可能会影响其他的元素。
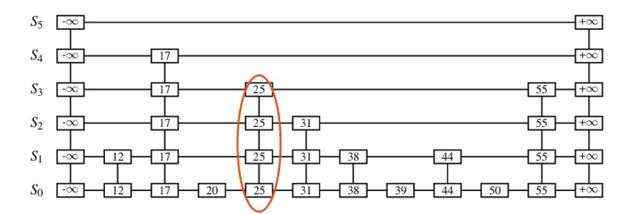
还拿上图举个例子,假设我们要删除掉25这个元素。那么会发生什么?
对于25以后的元素其实并不会影响,因为节点之后后向指针,会影响的是指向25的这些节点,在这个例子当中是17这个节点。由于25被删除,17的指针需要穿过25的位置继续往后,指向后面的元素,也就是55和31 。
比较容易想明白的是如果我们找到这些指向25的指针,它们修改之后的位置是比较容易确定的,因为其实就是25这个元素指向的位置。但是这些指向25的元素怎么获取呢?
如果光想似乎没有头绪,但是结合一下图,不难想明白,还记得我们查找的时候,每次都看得尽量远的贪心法吗?我们每次发生”下楼“操作的元素不就是最近的一个能看到25的位置吗?也就是说我们把查找过程中发生下楼的位置都记录下来即可。
想明白了,代码也就呼之欲出,和query的代码基本一样,无非多了几行关于这点的处理。
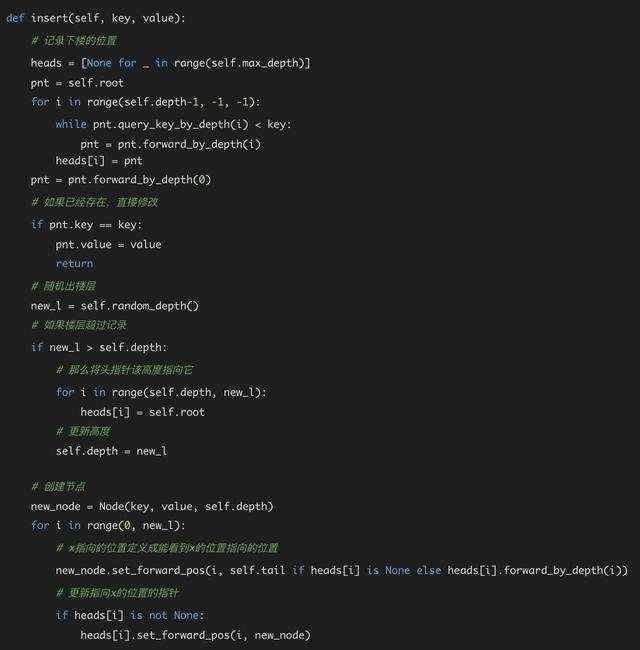
insert 方法
最后是插入元素的insert方法了,在insert之前,我们也同样需要查找,因为我们要将元素放到正确的位置。
如果这个位置已经有元素了,那么我们直接修改它的value,其实这就是修改操作了,如果设计成禁止修改,也可以返回失败。插入的过程同样会影响其他元素的指针指向的内容,我们分析一下就会发现,插入的过程和删除其实是相反的。删除的过程当中我们需要将指向x的指向x指向的位置,而插入则是相反,我们要把指向x后面的指针指向x,并且也需要更新x指向的位置,如果能理解delete,那么理解insert其实是板上钉钉的。
我们直接来看代码:
到这里,整个代码就结束了。怎么说呢,虽然它的原理不难理解,但是代码写起来由于涉及到了指针的操作和运算,所以还是挺麻烦的,想要写对并且调试出来不容易。但相比于臭名昭著的各类平衡树而言,已经算是非常简单的了。
SkipList在各类分布式系统和应用当中广泛使用,算是非常重要的基础构建,因此非常值得我们学习。并且我个人觉得,这个数据结构非常巧妙,无论是原理还是编码都很有意思,希望大家也能喜欢。
今天的文章就是这些,如果觉得有所收获,请顺手点个关注或转发吧,你们的举手之劳对我来说很重要。








 京公网安备 11010802041100号
京公网安备 11010802041100号