Zookper是一种分布式的,开源的,应用于分布式应用的协作服务。它提供了一些简单的操作,使得分布式应用可以基于这些接口实现诸如
Zookper是一种分布式的,开源的,应用于分布式应用的协作服务。它提供了一些简单的操作,使得分布式应用可以基于这些接口实现诸如同步、配置维护和分集群或者命名的服务。 网上有很多的安装教程,有些确实很不错,但总有一些比较坑的,误导了大家的安装,这次把自己亲身经历,安装的步骤和在安装中遇到的一些问题发布出来,供大家共同学习。
首先,当然是下载zookeeper的安装包。下载地址: 通过下面的命令:wget
然后进入该目录,直接解压: tar zxvf zookeeper-3.4.5.tar.gz
修改 zookeeper-3.4.5/conf目录下面的zoo_sample.cfg为zoo.cfg 。通过命令 : mv zoo_sample.cfg zoo.cfg
并且进一步配置文件的内容如下所示:
tickTime=2000
dataDir=/home/Hadoop/zookeeper/data
clientPort=2181
initLimit=10
syncLimit=5
server.1=Master.Hadoop:2888:3888
server.2=Slave1.Hadoop:2888:3888
server.3=Slave2.Hadoop:2888:3888
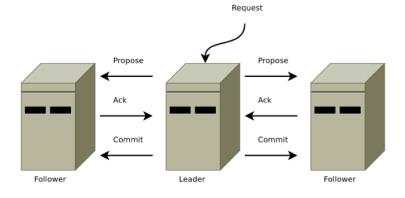
其中各个字段都有自己的含义,有兴趣的可以自己查阅相关字段的意义。下面的server.1,server.2,server.3标签表示的是3个zookeeper节点,他们都是相同的地位,,在工作的时候他们通过一个算法来推举出来一个leader其他的都是follower,在后面的验证中可以看到。他的服务如下图所示:

发布到其他的两个节点,(执行前注意自己的所在目录):
scp -r zookeeper-3.4.5/ hadoop@Slave1.Hadoop:~/zookeeper/
scp -r zookeeper-3.4.5/ hadoop@Slave2.Hadoop:~/zookeeper/
设置myid 在我们配置的dataDir指定的目录下面,创建一个myid文件,里面内容为一个数字,用来标识当前主机,conf/zoo.cfg文件中配置的server.X中X为什么数字,则myid文件中就输入这个数字,例如:
hadoop@Master:~/zookeeper$ echo "1" > /home/hadoop/zookeeper/myid
hadoop@Slave1:~/zookeeper$ echo "2" > /home/hadoop/zookeeper/myid
hadoop@Slave2:~/zookeeper$ echo "3" > /home/hadoop/zookeeper/myid
启动zookeeper
hadoop@Master:~/zookeeper/zookeeper-3.3.4$ bin/zkServer.sh start
hadoop@Slave1:~/zookeeper/zookeeper-3.3.4$ bin/zkServer.sh start
hadoop@Slave2:~/zookeeper/zookeeper-3.3.4$ bin/zkServer.sh start
因为3个节点的启动是有顺序的所以在陆续启动三个节点的时候,前面先启动的节点连接未启动的节点的时候会报出一些错误。可以忽略。
出现的一个问题。下面是查看日志的截图:

经过检查发现时在配置文件 zoo.cfg中写的目录有问题。配置的目录和新建myid的目录不一样造成的。在第6步中容易发现问题。修改myid的目录。
查看是否成功。

后面检测三个节点的状态:



ZooKeeper 的详细介绍:请点这里
ZooKeeper 的下载地址:请点这里
相关阅读:
ZooKeeper集群配置
使用ZooKeeper实现分布式共享锁
分布式服务框架 ZooKeeper -- 管理分布式环境中的数据
ZooKeeper集群环境搭建实践
ZooKeeper服务器集群环境配置实测
ZooKeeper集群安装











 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有