★ 本次主要学习如何使用pandas对数据进行分析统计,特别是groupby
” 本次项目主要总结如下知识点:
将文件保存在特定的文件夹下 在数据分析的过程中,会生成新的数据和图表,为了将产生的图表放置在相同的目录下,需要生成一个新的文件夹,具体的代码操作如下:
import os'.' './output' if not os.path.exits(output_path):
改段代码表示:如果不存在当前目录output_pathoutput_path = './output'
灵活运用groupby groupbypandas
分割步骤将DataFrame按照指定的键分割成若干组 应用步骤对每个组应用函数,通常是累积、转换或过滤函数 基本步骤如下:
举一个简单的应用例子:我们要查看某家咖啡店销量的产品,如Classic Espresso Drinks , Frappuccino® Blended Coffee , Frappuccino® Light Blended Coffee 等产品的总的品类,然后求每一款茶品的平均热量。例如Coffee 有四款茶品,每一种茶品有一个卡路里热量值,我们需要求Coffee 这款饮品的热量值。这时groupby
import pandas as pd'./coffee_menu.csv' ',' ,encoding = 'utf-8' )#print(df.head()) "Beverage_category" )["Calories" ].mean()"Beverage_category" )["Calories" ].count()
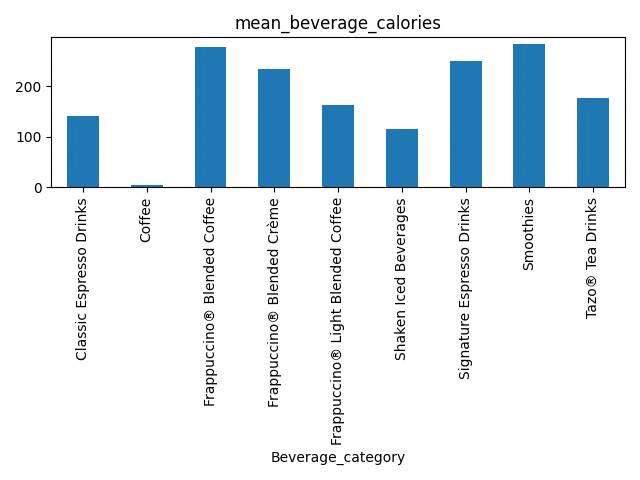
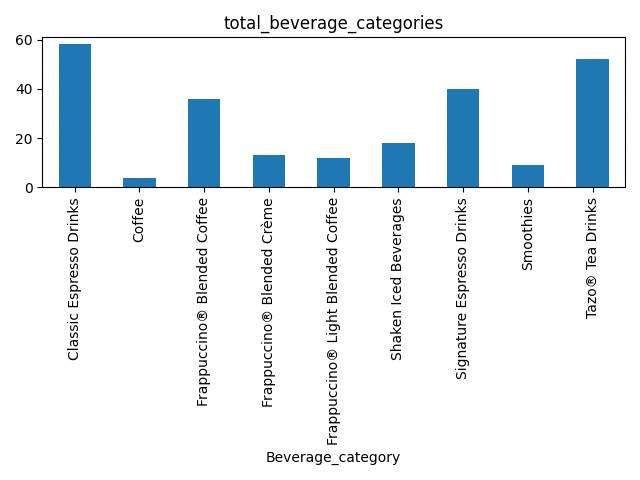
输出的结果为:
Beverage_category58 4 36 13 12 18 40 9 52 140.172414 4.250000 276.944444 233.076923 162.500000 114.444444 250.000000 282.222222 177.307692
我们理清了整体关键步骤之后,我们需要保存相关数据和图片:完整的代码如下:
import pandas as pdimport osimport matplotlib.pyply as plt""" './coffee_menu.csv' './output_002' if not os.path.exists(output_path):def collect_data () :',' ,encoding = 'utf-8' )return dfdef analyse_data (df) :"Beverage_category" )["Calories" ].count()"Beverage_category" )["Calories" ].mean()return bervage_categories__total,beverage_categories_calories_meandef save_and_show_data (bervage_categories_total,beverage_categories_calories_mean) :#保存数据 'total_categories.csv' ))'mean_calories.csv' ))#保存图表 'bar' )"total_beverage_categories" )'total_berage_categories.png' ))'bar' )"mean_beverage_calories" )'mean_bervage_calories.png' ))def main () :if __name__ == '__main__' :
输出表格为:
(完)
★往期回顾 美国PM2.5污染变化图 用python绘制中国地区 项目学习(3) 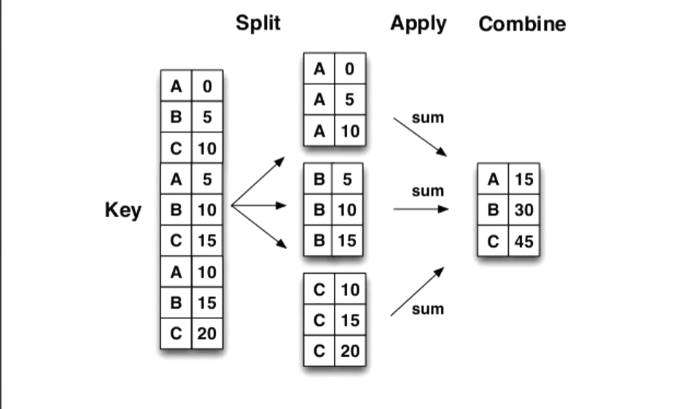
 项目总结:
项目总结:



 京公网安备 11010802041100号
京公网安备 11010802041100号