

大家好,基于Python的数据科学实践课程又到来了,大家尽情学习吧。本期内容主要由智亿同学与政委联合推出。
Q:
经过上一章的学习,大家应该已经熟悉了火锅团购数据与团购的业务。我相信大家也可以读入火锅团购数据了。那么数据科学的下一步是什么?
A:
清洗与处理数据,即把数据处理成,我们想要的样子。Python提供了一个强大的库,叫做Pandas,帮我们完成这一步骤。值得提及的是,Pandas的开发者都声称,其实是模仿R语言中的DataFrame的数据结构构建的Pandas。所以熟悉R语言的小伙伴会有似曾相识的感觉。
首先,小伙伴们可别小瞧了数据清洗,以为“数据科学”只和那些“高大上”的模型有关。实际上,在完整的数据分析的项目中,数据清洗和预处理上占的时间往往在80%左右,剩下的20%才是数据建模(毕竟好多时候都会先使用,经过大量实践证明效果好的成熟模型,往往几行代码搞定)。所以,掌握了Pandas,你的“Python数据科学之路”才算是启程了。
其次,学习Pandas可不容易,Pandas的官方文档的页数有将近2000页。初学时,学了后面忘了前面是常有的事情。为此,这一章只讲解在实际项目中最最常用的一些函数与思想,学完后,至少能完成80%的数据清洗工作。
最后,不要忘记政委是个公认的吃货,尤爱火锅烧烤。这两天可犯了愁:熊大过两天就要来西安考察工作,亟需找个高端大气上档次的饭馆!可是饭馆这么多,怎么挑个合适的!正犯愁呢,政委灵机一动:赶紧翻出上一章使用的火锅团购数据,正好可以用Pandas分析分析,找到性价比最高能够招待熊大的饭馆,打开Jupyter就开干!

初级篇—相遇Pandas
本期,我们将学会:
 1、读入数据—数据分析的"米"
1、读入数据—数据分析的"米"首先,做数据分析第一步是获取数据。俗话说,巧妇难为无米之炊。在数据分析领域,数据就是我们的“米”。获取数据的途径有两种:1. 使用爬虫从互联网上爬取数据;2. 从现有数据库中下载。本章假设火锅团购数据是现成的,所以直接读入数据即可,后续章节会讲解如何爬取现有的火锅团购数据。
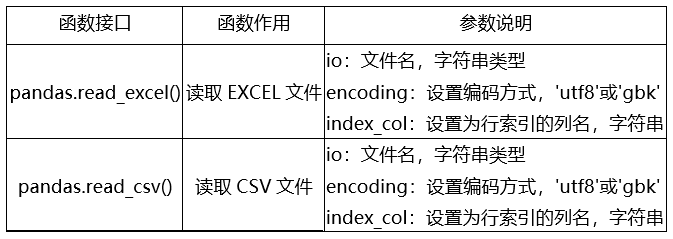
表1 读入文件函数说明
例1 读入文件
1import pandas as pd # 导入Pandas模块
2raw_data=pd.read_excel("https://github.com/xiangyuchang/xiangyuchang.github.io/blob/master/BearData/shops_nm.xlsx?raw=true") #读入数据
3print('数据的维度是:', raw_data.shape) #返回值为(699,9)
4raw_data.head() #查看数据的前5行
运行结果如图1:
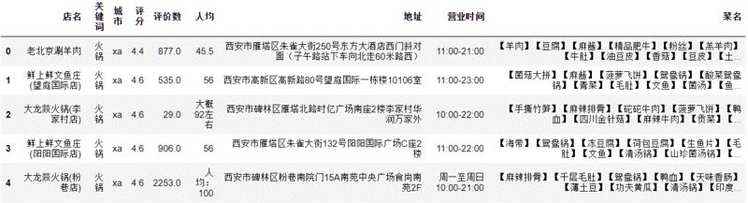
图1 读入文件运行结果
在这里,使用了pandas.read_excel()读入excel文件,并输出前5行观察数据。如果想打开csv文件,则需要使用pandas.read_csv()即可。

敲黑板:CSV文件的编码格式默认为UTF8,但是Office的CSV文件的编码不是UTF8,而是GBK,使用时需要注意。大家可以使用encoding参数修改编码。
Pandas常用的基本数据结构主要是两类:Series和DataFrame。
什么是DataFrame呢?所谓DataFrame,就是类似于Excel那样,如图2所示的具有行和列两个维度的特殊数据结构。肯定有人会认为这不就是矩阵吗?这里需要大家仔细去思考,真实业务场景面对的数据是如上图导入的火锅团购数据的结果一样。第一列店名是文本;第四列评分是数字。所以,这与矩阵等平时被使用的结构的区别就在于,每一列的数据类型要相同,但是不同列可以不同。基于这个理念,可以通过构建字典或数组的方式生成DataFrame。其实在上面的例子中,读入的数据就已经被自动转换成DataFrame了。
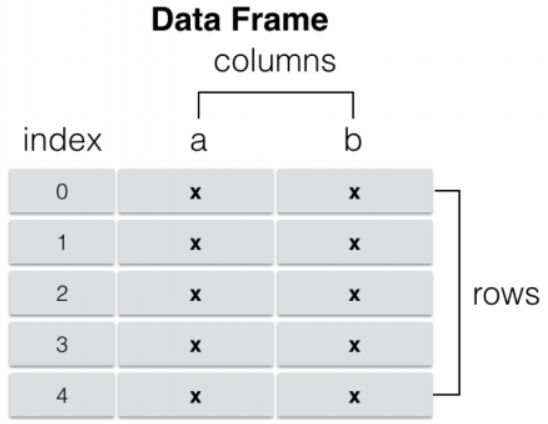
图2 DataFrame数据结构
什么是Series呢?所谓Series,简单理解,就是DataFrame中的一列(并不完全准确,但可以这么理解,见图3)。

图3 Series数据结构
2、检查重复—重复的东西咱不要获取到的原始数据往往存在各种问题,最容易解决的是:重复值。为什么会有重复值存在?就互联网上获取到的数据而言,可能是商家付了一笔不菲的“流量费”,平台在多个位置展示同一商家的信息,这样商家有更大概率获取流量。好奇的宝宝可以进入“大众点评”、“美团”、“百度糯米”随意查看。
把数据读入后,第一步要做的是检查数据重复、缺失的情况。对于重复值,直接剔除即可;对于缺失值,可采用剔除缺失值或插值法填充数据。
表2 判断、丢弃重复值函数说明
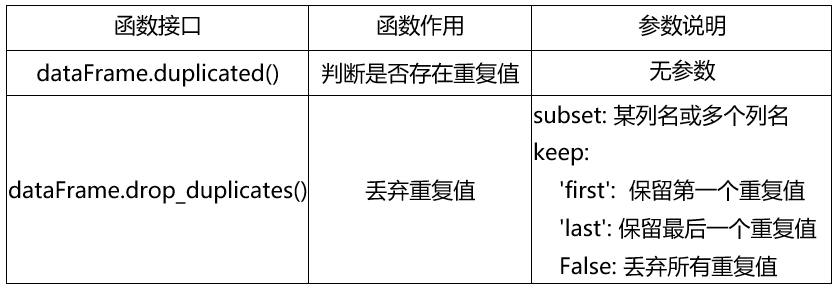
例2 判断、丢弃重复值
1# 判断是否存在完全一致的数据行
2duplicated_data = raw_data[raw_data.duplicated() == True]
3if len(duplicated_data) == 0:
4 print('不存在完全一致的数据行')
5else:
6 print(duplicated_data)
运行结果:不存在完全一致的数据行。那么,现在制造一个完全重复的数据行。我们把数据框中的第一行赋值给第二行。
1print(raw_data.iloc[0,:])
2raw_data.iloc[1,:] = raw_data.iloc[0,:]
其显示结果为:

大家可以再次运行前一部分的代码块,它就能帮你自动发现第二个商户的信息与第一个商户完全相同。同样的方式,可以检查店名是否有重复的。显然只有第二个商户是我们赋值的重复信息,所以返回值为“老北京帅羊肉”。
1# 判断是否存在重复的店名
2duplicated_shops = raw_data['店名'][raw_data['店名'].duplicated() == True]
3if len(duplicated_shops) == 0:
4 print('不存在重复的店名')
5else:
6 print(duplicated_shops)
7# 返回值为:老北京刷羊肉
下面终于要drop_duplicates函数出场了。
1# 等价于raw_data = raw_data[raw_data['店名'].duplicated() == False]
2drop_duplicates_shops = raw_data.drop_duplicates(subset=['店名'])
3drop_duplicates_shops.head()
其运行结果返回了去重后的商户信息列表。

综上所述,数据框中的数据去重的方法为:首先通过duplicated()方法判断是否存在重复行,再通过Pandas特有的判断表达式就可以按条件输出符合条件的数据框。注意,删除重复值可以采用drop_duplicates()方法,也可以采用“duplicated() + Pandas判断表达式”的方法,二者有相同的效果。
3、判断表达式—更Pythonic熊大马上就要下飞机到西安了。我数据分析还没做完呢,到底带他去哪里吃饭呢。干脆来个简单粗暴的,把评分最高为5分的店都找出来,然后选吧,不犹豫了。这里就要使用Pandas特有的判断表达式,先看下面这个例子:
1for i in range(len(df1)):
2 if df1[column1].iloc[i] == value1:
3 print(df1[column1].iloc[i])
可以看到,这至少需要3行代码才能完成筛选某一列的值,非常麻烦不说,而且速度也很慢。那么,有没有办法简化操作呢?这就需要用到Pandas判断表达式了。
Pandas判断表达式本质上相当于for循环+if条件判断,但开发效率和运行效率更高。最关键的是,Pandas条件表达式也可以任性组合叠加!需要注意的是,组合叠加相当于“且”的关系,而非“或”的关系。
1# 筛选某一列的值,返回符合条件的所有行
2df1[df1[column1] == value1]
3
4# 筛选某一列的值,返回符合条件的某一列
5df1[column2][df1[column1] == value1]
6
7# 筛选多列的值,返回符合条件的所有行
8df1[df1[column1] == value1][df1[column2] == value2][...]
9
10# 筛选多列的值,返回符合该条件的多列
11df1[[column1, column2]][df1[column1] == value1][...]
从上面几个例子中,Pandas的条件判断式把for循环和if判断的语句从至少3行,缩减为一行,简直是装逼神器!
最后还是来找一下带熊大吃饭的店吧。
1print(raw_data[raw_data['评分']==5])
2# 显示共有67家店铺哦,赶紧找个带熊大去。
4、检查缺失—要命的缺失
敲黑板:相比于重复值,我们更关心是否存在缺失值。
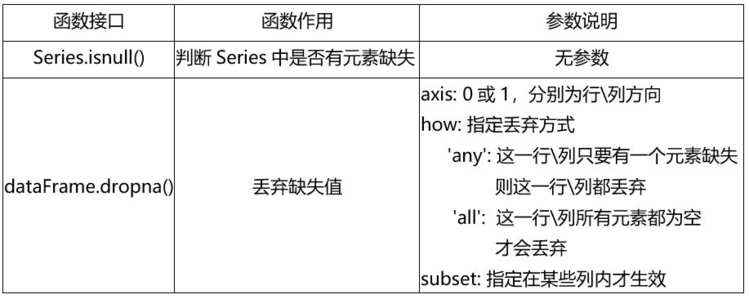
在过去,很多企业并不重视,或者说并没有意识到数据的重要性,对于数据的存储也仅仅是为了“存”,而非分析(这其实是在说,过去的大企业并不一定比现在的中小企业拥有更多的数据)。对数据的不重视导致存在大量的填写不规范,漏填、错填等,这些行为都会导致整一条数据无法使用或分析价值低。通过isnull()方法作用于某一列或某几列就可以判断是否为缺失值。
表3 判断缺失值
下面我们找一下是否有的商户的评价数是否有缺失。
例3 判断缺失值
1is_null_data = raw_data[raw_data['评价数'].isnull() == True]
2print(is_null_data)
3
4raw_data2 = raw_data[raw_data['评价数'].isnull() == False]
运行结果如图4所示。
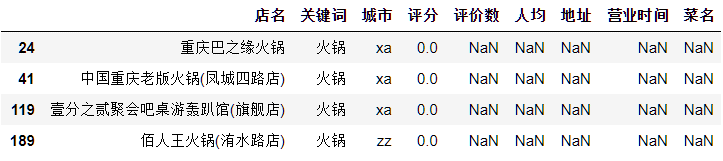
图4 判断缺失值
我们发现,存在4条数据有大量的缺失值,直接通过Pandas的判断表达式剔除即可。剔除后,数据维度变为(695,9)。去除缺失值后的DataFrame命名为raw_data2(好宝宝不重复命名相同变量)。

好了,今天就先介绍到这里。
作业
▼往期精彩回顾▼初步搭建数据科学工作环境
Conda的使用
Spyder入门
Jupyter入门
Markdown
简单读写数据
数据类型
数据结构
控制流
函数与模块
Numpy


点击这里阅读原文










 京公网安备 11010802041100号
京公网安备 11010802041100号