作者:走丢的鞋带2702934823 | 来源:互联网 | 2023-09-23 16:36
A文件:比如,我想筛选出“设计井别”、“投产井别”、“目前井别”三列数据都为11的数据,结果如下:当然,这里的筛选条件可以根据用户需要自由调整,代码如下:#-*-coding:ut
A文件:
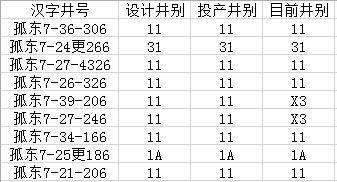
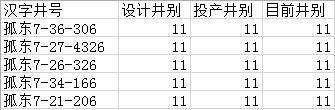
比如,我想筛选出“设计井别”、“投产井别”、“目前井别”三列数据都为11的数据,结果如下:
当然,这里的筛选条件可以根据用户需要自由调整,代码如下:
# -*- coding: utf-8 -*-
import pandas as pd
#input.csv是那个大文件,有很多很多行
df1 = pd.read_csv(u'input.csv', encoding='gbk')
#加encoding=‘gbk’是因为文件中存在中文,不加可能出现乱码
#这里的筛选条件可以根据用户需要进行修改
outfile = df1[(df1[u'设计井别']=='11') & (df1[u'投产井别']=='11') &(df1[u'目前井别']=='11')]
outfile.to_csv('outfile.csv', index=False, encoding='gbk')
有时我们也会有相反的一个需求,需要删除“设计井别”、“投产井别”、“目前井别”三列数据都为11的那些行,效果如下:
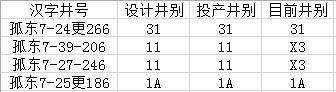
代码如下:
#input.csv是那个大文件,有很多很多行
df1 = pd.read_csv(u'input.csv', encoding='gbk')
df2 = pd.read_csv(u'outfile.csv', encoding='gbk')
#加encoding=‘gbk’是因为文件中存在中文,不加可能出现乱码
index = ~df1[u'汉字井号'].isin(df2[u'汉字井号'])
df4 = df1[index]
df4.to_csv('outfile1.csv', index=False, encoding='gbk')

 京公网安备 11010802041100号
京公网安备 11010802041100号