HBase是Hadoop的数据库,基于Hadoop运行,是一种NoSQL数据库。 特点:分布式、多版本、面向列的存储模型,能够大规模的数据实时随机读写,可直接使用本地文件系统。 不适合:与关系型数据库相比,模型简单,API很少;不适合小规模的数据。 数据存放的位置叫
HBase是Hadoop的数据库,基于Hadoop运行,是一种NoSQL数据库。
特点:分布式、多版本、面向列的存储模型,能够大规模的数据实时随机读写,可直接使用本地文件系统。
不适合:与关系型数据库相比,模型简单,API很少;不适合小规模的数据。
数据存放的位置叫做单元(cell),其中的数据可以有多个版本,根据时间戳(timestamp)来区别。
安装:
tar xfz hbase-0.94.18.tar.gz
cd hbase*
cd conf
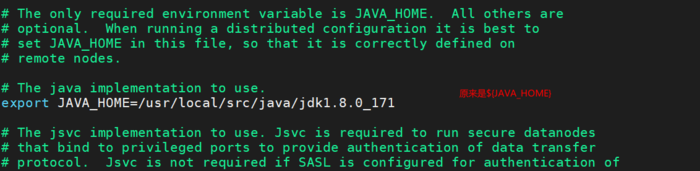
vi hbase-env.sh
export JAVA_HOME = /usr/jdk1.6.0_45
vi hbase-site.xml
hbase.rootdir
hdfs://localhost:9000/hbase
数据存放的位置。
dfs.replication
1
指定副本个数为1,因为伪分布式。
以上配置完成后,启动hadoop,
cd ../hadoop
bin/start-all.sh
jps 检查是否启动成功。
然后启动hbase,
cd ../hbase*
bin/start-hbase.sh
jps检查hbase是否启动成功,
成功会有HMaster
也可通过浏览器,http://localhost:60010查看
bin/hbase shell 可进入hbase命令行工具。
HBase Shell 支持多种命令
–一般的有
? status, version
–数据定义语言(DDL)
? alter, create, describe, disable, drop, enable, exists, is_disabled,
is_enabled, list
–数据控制语言 (DML)
? count, delete, deleteall, get, get_counter, incr, put, scan, truncate
–集群管理
? balancer, close_region, compact, flush, major_compact, move, split,
unassign, zk_dump, add_peer,disable_peer, enable_peer,
remove_peer, start_replication, stop_replication
? 查看每个命令的使用方法
–hbase> help ""
>list #列出hbase存在的表
>status #返回集群的状态信息
创建一张表,hbase有多种建表的方式:
--hbase> create 't1', {NAME => 'f1', VERSIONS => 5}
–hbase> create 't1', {NAME => 'f1', VERSIONS => 1,
TTL => 2592000, BLOCKCACHE => true}
–hbase> create 't1', {NAME => 'f1'}, {NAME => 'f2'},
{NAME => 'f3'}
–hbase> create 't1', 'f1', 'f2', 'f3'
如,create 'blog', {NAME=>'info'}, {NAME=>'content'}
list查看hbase中的表
建好表之后,添加数据到表中
格式如下:
put 'table', 'row_id', 'family:column', 'value'
put 'Blog', 'Matt-001', 'info:title', 'Elephant'
put 'Blog', 'Matt-001', 'info:author', 'Matt'
put 'Blog', 'Matt-001', 'info:date', '2014.04.26'
count 'table_name' 查看列数
get 'table', 'row_id' 获取表中的某一列数据
scan 'table_name' 返回整张表的全部数据
scan 'table', {COLUMNS=>['col1', 'col2']} 也可以加条件
编辑数据:
用的还是put 命令,即put在列不存在的时候执行添加,存在的话就执行修改。
修改的时候会保留之前的版本,默认会保留3份。
delete 'table', 'rowId', 'column' 删除数据,不加条件会删除所有版本。
删除表,首先要将表的状态改成离线,disable 'table_name'
才能删除,drop 'table_name'

本文原创发布php中文网,转载请注明出处,感谢您的尊重!







 京公网安备 11010802041100号
京公网安备 11010802041100号