Sql Server 会有以下方法来查找您需要的数据记录: 1. 【Table Scan】:遍历整个表,查找所匹配的记录行。这个操作将会一行一行的检查,当然,效率也是最差的。 2. 【Index Scan】:根据索引,从表中过滤出来一部分记录,再查找所匹配的记录行,显示比第一种
Sql Server 会有以下方法来查找您需要的数据记录:
1. 【Table Scan】:遍历整个表,查找所匹配的记录行。这个操作将会一行一行的检查,当然,效率也是最差的。
2. 【Index Scan】:根据索引,从表中过滤出来一部分记录,再查找所匹配的记录行,显示比第一种方式的查找范围要小,因此比【Table Scan】要快。
3. 【Index Seek】:根据索引,定位(获取)记录的存放位置,然后取得记录,因此,比起前二种方式会更快。
4. 【Clustered Index Scan】:和【Table Scan】一样。注意:不要以为这里有个Index,就认为不一样了。其实它的意思是说:按聚集索引来逐行扫描每一行记录,因为记录就是按聚集索引来顺序存放的。而【Table Scan】只是说:要扫描的表没有聚集索引而已,因此这二个操作本质上也是一样的。
5. 【Clustered Index Seek】:直接根据聚集索引获取记录,最快!
在Sql Server中,我们每个join命令,都会在内部执行时,采用三种更具体的方式来运行:
1. 【Nested Loops join】,如果一个联接输入很小,而另一个联接输入很大而且已在其联接列上创建了索引,则索引 Nested Loops 连接是最快的联接操作,因为它们需要的 I/O 和比较都最少。
嵌套循环联接也称为“嵌套迭代”,它将一个联接输入用作外部输入表(显示为图形执行计划中的顶端输入),将另一个联接输入用作内部(底端)输入表。外部循环逐行处理外部输入表。内部循环会针对每个外部行执行,在内部输入表中搜索匹配行。可以用下面的伪码来理解:
foreach(row r1 in outer table)
foreach(row r2 in inner table)
if( r1, r2 符合匹配条件 )
output(r1, r2);
最简单的情况是,搜索时扫描整个表或索引;这称为“单纯嵌套循环联接”。如果搜索时使用索引,则称为“索引嵌套循环联接”。如果将索引生成为查询计划的一部分(并在查询完成后立即将索引破坏),则称为“临时索引嵌套循环联接”。查询优化器考虑了所有这些不同情况。
如果外部输入较小而内部输入较大且预先创建了索引,则嵌套循环联接尤其有效。在许多小事务中(如那些只影响较小的一组行的事务),索引嵌套循环联接优于合并联接和哈希联接。但在大型查询中,嵌套循环联接通常不是最佳选择。
2. 【Merge Join】,如果两个联接输入并不小但已在二者联接列上排序(例如,如果它们是通过扫描已排序的索引获得的),则合并联接是最快的联接操作。如果两个联接输入都很大,而且这两个输入的大小差不多,则预先排序的合并联接提供的性能与哈希联接相近。但是,如果这两个输入的大小相差很大,则哈希联接操作通常快得多。
合并联接要求两个输入都在合并列上排序,而合并列由联接谓词的等效 (ON) 子句定义。通常,查询优化器扫描索引(如果在适当的一组列上存在索引),或在合并联接的下面放一个排序运算符。在极少数情况下,虽然可能有多个等效子句,但只用其中一些可用的等效子句获得合并列。
由于每个输入都已排序,因此 Merge Join 运算符将从每个输入获取一行并将其进行比较。例如,对于内联接操作,如果行相等则返回。如果行不相等,则废弃值较小的行并从该输入获得另一行。这一过程将重复进行,直到处理完所有的行为止。
合并联接操作可以是常规操作,也可以是多对多操作。多对多合并联接使用临时表存储行(会影响效率)。如果每个输入中有重复值,则在处理其中一个输入中的每个重复项时,另一个输入必须重绕到重复项的开始位置。可以创建唯一索引告诉SqlServer不会有重复值。
如果存在驻留谓词,则所有满足合并谓词的行都将对该驻留谓词取值,而只返回那些满足该驻留谓词的行。
合并联接本身的速度很快,但如果需要排序操作,选择合并联接就会非常费时。然而,如果数据量很大且能够从现有 B 树索引中获得预排序的所需数据,则合并联接通常是最快的可用联接算法。
3. 【Hash Join】,哈希联接可以有效处理未排序的大型非索引输入。它们对复杂查询的中间结果很有用,因为: 1. 中间结果未经索引(除非已经显式保存到磁盘上然后创建索引),而且通常不为查询计划中的下一个操作进行适当的排序。 2. 查询优化器只估计中间结果的大小。由于对于复杂查询,估计可能有很大的误差,因此如果中间结果比预期的大得多,则处理中间结果的算法不仅必须有效而且必须适度弱化。
哈希联接可以减少使用非规范化。非规范化一般通过减少联接操作获得更好的性能,尽管这样做有冗余之险(如不一致的更新)。哈希联接则减少使用非规范化的需要。哈希联接使垂直分区(用单独的文件或索引代表单个表中的几组列)得以成为物理数据库设计的可行选项。
哈希联接有两种输入:生成输入和探测输入。查询优化器指派这些角色,使两个输入中较小的那个作为生成输入。
哈希联接用于多种设置匹配操作:内部联接;左外部联接、右外部联接和完全外部联接;左半联接和右半联接;交集;联合和差异。此外,哈希联接的某种变形可以进行重复删除和分组,例如 SUM(salary) GROUP BY department。这些修改对生成和探测角色只使用一个输入。
哈希联接又分为3个类型:内存中的哈希联接、Grace 哈希联接和递归哈希联接。
内存中的哈希联接:哈希联接先扫描或计算整个生成输入,然后在内存中生成哈希表。根据计算得出的哈希键的哈希值,将每行插入哈希存储桶。如果整个生成输入小于可用内存,则可以将所有行都插入哈希表中。生成阶段之后是探测阶段。一次一行地对整个探测输入进行扫描或计算,并为每个探测行计算哈希键的值,扫描相应的哈希存储桶并生成匹配项。
Grace 哈希联接:如果生成输入大于内存,哈希联接将分为几步进行。这称为“Grace 哈希联接”。每一步都分为生成阶段和探测阶段。首先,消耗整个生成和探测输入并将其分区(使用哈希键上的哈希函数)为多个文件。对哈希键使用哈希函数可以保证任意两个联接记录一定位于相同的文件对中。因此,联接两个大输入的任务简化为相同任务的多个较小的实例。然后将哈希联接应用于每对分区文件。
递归哈希联接:如果生成输入非常大,以至于标准外部合并的输入需要多个合并级别,则需要多个分区步骤和多个分区级别。如果只有某些分区较大,则只需对那些分区使用附加的分区步骤。为了使所有分区步骤尽可能快,将使用大的异步 I/O 操作以便单个线程就能使多个磁盘驱动器繁忙工作。
在优化过程中不能始终确定使用哪种哈希联接。因此,SQL Server 开始时使用内存中的哈希联接,然后根据生成输入的大小逐渐转换到 Grace 哈希联接和递归哈希联接。
如果优化器错误地预计两个输入中哪个较小并由此确定哪个作为生成输入,生成角色和探测角色将动态反转。哈希联接确保使用较小的溢出文件作为生成输入。这一技术称为“角色反转”。至少一个文件溢出到磁盘后,哈希联接中才会发生角色反转。
说明:您也可以显式的指定联接方式,SqlServer会尽量尊重您的选择。比如你可以这样写:inner loop join, left outer merge join, inner hash join
但是,我还是建议您不要这样做,因为SqlServer的选择基本上都是正确的,不信您可以试一下。
我们再次回到【SQL Server Management Studio】,输入以下语句,然后执行。
set statistics profile on select v.OrderID, v.CustomerID, v.CustomerName, v.OrderDate, v.SumMoney, v.Finished from OrdersView as v where v.OrderDate >= '2010-12-1' and v.OrderDate <'2011-12-1';
注意:现在加了一句,【set statistics profile on 】,得到的结果如下:

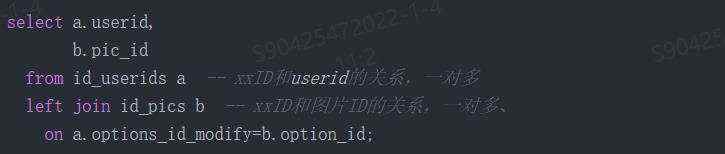




 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有