点击蓝字,关注我们
01
概述
大数据必然涉及海量数据,所谓海量数据,就是数据量太大,要么在短时间内无法计算出结果,要么因为数据太大无法一次性装入内存。
针对时间,我们可以使用巧妙的算法搭配合适的数据结构,如bitmap/堆/trie树等进行优化。
针对空间,就一个办法,大而化小,分而治之,常采用hash映射等方法。
02
hash映射
这里的hash映射是指通过一种哈希算法,将海量数据均匀分布在对应的内存或更小的文件中,这是一种分而治之的实现思想。
使用Hash映射有个最重要的特点是: Hash值相同的两个串不一定一样,但是两个一样的字符串hash值一定相等(如果不相等会存在严重安全问题,比如两个人的账号信息经过哈希后映射到同一个值)。
如下所示:
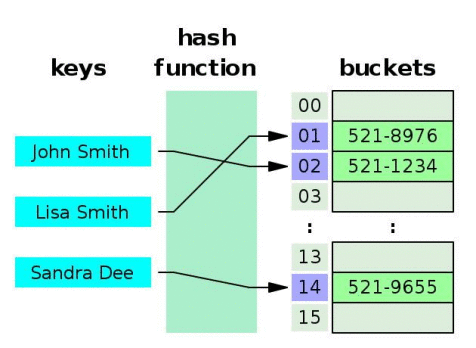
在使用hash映射的时候,选择合适高效的Hash函数是关键,选择的不好不仅浪费空间,而且效率不高,存在冲突的可能性较大。当出现冲突的时候,还需要借助各种冲突检测方法去解决。
03
bitmap
用1个(或几个)bit位来标记某个元素对应的value(如果是1bitmap,就只能是元素是否存在;如果是x-bitmap,还可以是元素出现的次数等信息)。使用bit位来存储信息,在需要的存储空间方面可以大大节省。
应用场景有:
1、排序(如果是1-bitmap,就只能对无重复的数排序)
2、判断某个元素是否存在
例如,某文件中有若干8位数字的电话号码,要求统计一共有多少个不同的电话号码?
分析:8位最多99 999 999, 如果1Byte(8bit)表示1个号码是否存在,需要99999999Byte=99999999/1024KB=99999999/1024/1024MB≈95MB空间,但是如果采用1bit表示1个号码是否存在,则只需要 95/8=12MB 的空间。这时,数字k(0~99 999 999)与bit位的对应关系是:
#define MAXSIZE 15*1024*1024char a[MAXSIZE];memset(a,0,MAXSIZE);a[k/8] &#61; a[k/8] | (0x01 <8))
04
Trie树
Trie&#xff0c;又叫前缀树&#xff0c;字典树等等。它有很多变种&#xff0c;如后缀树&#xff0c;Radix Tree(基树&#xff0c;Linux内核采用这种数据结构用以实现快速查找)。
与二叉查找树不同&#xff0c;键不是直接保存在节点中&#xff0c;而是由节点在树中的位置决定。一个节点的所有子孙都有相同的前缀&#xff0c;也就是这个节点对应的字符串&#xff0c;而根节点对应空字符串。
例如&#xff0c;要想实现某个单词的快速查找&#xff0c;可以采用如下Trie树将每个单词存储起来&#xff1a;
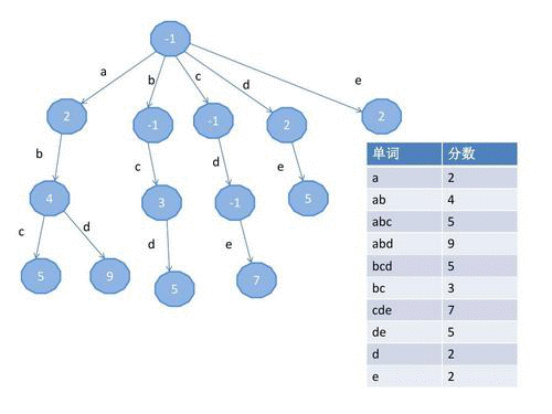
这样存储的好处就在于&#xff0c;要想查找的时候可以根据单词排除大量非关联分支&#xff0c;提高查询速度。
05
数据库索引
索引使用的数据结构多是B树或B&#43;树。
B树和B&#43;树广泛应用于文件存储系统和数据库系统中&#xff0c;mysql使用的是B&#43;树&#xff0c;oracle使用的是B树&#xff0c;Mysql也支持多种索引类型&#xff0c;如b-tree 索引&#xff0c;哈希索引&#xff0c;全文索引等。
一般来说&#xff0c;索引本身也很大&#xff0c;不可能全部存储在内存中&#xff0c;因此索引往往以索引文件的形式存储的磁盘上。索引查找过程中就要产生磁盘I/O消耗&#xff0c;相对于内存存取&#xff0c;I/O存取的消耗要高几个数量级&#xff0c;所以评价一个数据结构作为索引的优劣最重要的指标就是在查找过程中磁盘I/O操作次数的渐进复杂度。换句话说&#xff0c;索引的结构组织要尽量减少查找过程中磁盘I/O的存取次数。
06
倒排索引
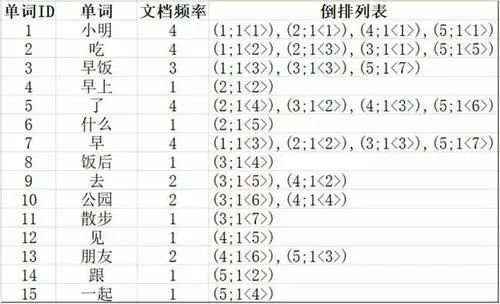
也叫反向索引。是文档检索系统中最常用的数据结构。
倒排索引的索引表中的每一项都包含一个属性值和具有该属性值的各记录的地址。因为不是由记录来确定属性值&#xff0c;而是由属性来确定记录&#xff0c;因而成为倒排索引(inverted index)。
倒排列表记录了某个单词位于哪些文档中。在给定的文档语料中&#xff0c;一般会有多个文档包含某单词&#xff0c;每个文档有唯一的编号(DocID)&#xff0c;单词在这个文档中出现的次数(TF)及单词在文档中哪些位置出现等信息&#xff0c;与一个文档相关的信息被称做倒排索引项(Posting)&#xff0c;包含这个单词的一系列倒排索引项形成了列表结构&#xff0c;这就是某个单词对应的倒排列表。
07
外排序
外排序即对磁盘文件的排序。如果待处理的数据不能一次装入内存&#xff0c;先读入部分数据排序后输出到临时文件&#xff0c;采用「排序-归并」的策略。在归并阶段将这些临时文件组合为一个大的有序文件&#xff0c;也即排序结果。
例如&#xff0c;要对900 MB的数据进行排序&#xff0c;但机器上只有100 MB的可用内存时&#xff0c;外归并排序按如下方法操作&#xff1a;
1、读入100 MB的数据至内存中&#xff0c;用某种常规方式(如快速排序、堆排序、归并排序等方法)在内存中完成排序&#xff1b;
2、将排序完成的数据写入磁盘&#xff1b;
3、重复步骤1和2直到所有的数据都存入了不同的100 MB的块(临时文件)中&#xff0c;最终会产生9个临时文件。
4、读入每个临时文件的前10 MB(100 MB / (9块 &#43; 1))的数据放入内存中的输入缓冲区&#xff0c;最后的10 MB作为输出缓冲区&#xff1b;
5、执行九路归并算法&#xff0c;将结果输出到输出缓冲区。一旦输出缓冲区满&#xff0c;将缓冲区中的数据写出至目标文件&#xff0c;清空缓冲区。一旦9个输入缓冲区中的一个变空&#xff0c;就从这个缓冲区关联的文件&#xff0c;读入下一个10M数据&#xff0c;除非这个文件已读完。这是“外归并排序”能在主存外完成排序的关键步骤 &#xff1a;因为“归并算法”(merge algorithm)对每一个大块只是顺序地做一轮访问(进行归并)&#xff0c;每个大块不用完全载入主存。
08
simhash算法
假设存在这样的应用场景&#xff1a;快速比较两种论文的相似程度&#xff0c;该如何设计算法&#xff1f;
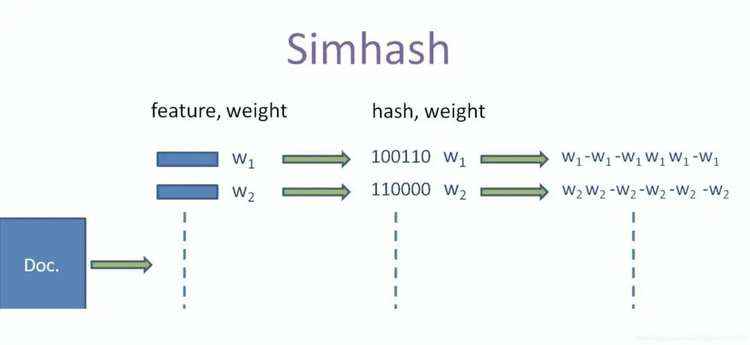
simhash算法分为5个步骤&#xff1a;
1、分词&#xff1a;对待考察文档进行分词&#xff0c;把得到的分词称为特征&#xff0c;然后为每一个特征设置N等级别的权重。如给定一段语句&#xff1a;“云计算通俗讲义的作者程序员姜戈”&#xff0c;分词后为&#xff1a;“云计算 通俗 讲义 的 作者 程序员 姜戈”&#xff0c;然后为每个特征向量赋予权值&#xff1a;云计算(5)通俗(2)讲义(2)的(1)作者(4)程序员(5)姜戈(5)&#xff0c;权重代表了这个特征在整条语句中的重要程度。
2、hash&#xff1a;通过hash算法计算各个特征向量的hash值&#xff0c;hash值为二进制数组成的n位签名。
3、加权&#xff1a;W&#61;hash*weight&#xff0c;W(云计算)&#61;101011*5&#61;5-55-555&#xff0c;W(作者)&#61;100101*4&#61;4-4-44-44。
4、合并&#xff1a;将上述每个特征的加权结果累加&#xff0c;变成一个序列串。如“5&#43;4&#xff0c;-5&#43;-4&#xff0c;5-4,-5&#43;4&#xff0c;5-4&#xff0c;5&#43;4”&#xff0c;得到“9,-9,1,-1,1”。
5、降维&#xff1a;对于n位签名的累加结果&#xff0c;如果大于0则置1&#xff0c;否则置0&#xff0c;从而得到该语句的simhash值&#xff0c;最后我们便可以根据不同语句simhash的海明距离来判断它们的相似度。例如把上面计算出来的“9,-9,1,-1,1,9”降维&#xff0c;得到“101011”&#xff0c;从而形成它们的simhash签名。
09
跳跃链表
跳跃链表对有序的链表附加辅助结构&#xff0c;在链表中的查找可以快速的跳过部分结点(因此得名)。跳跃链表是一种随机化数据结构&#xff0c;基于并联的链表&#xff0c;其效率与RBTree相当。具有简单、高效、动态的特点。查找、增加、删除的期望时间都是O(logN)。
跳跃列表是按层建造的。底层是一个普通的有序链表。每个更高层都充当下面列表的“快速跑道”&#xff0c;这里在层i中的元素按某个固定的概率p出现在层i&#43;1中。平均起来&#xff0c;每个元素都在1/(1-p)个列表中出现。
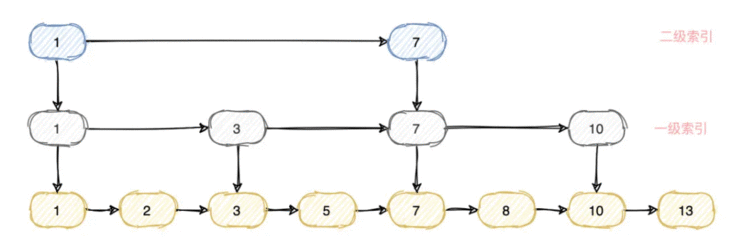
如果需要查找元素5&#xff0c;只需要遍历1->1->3-三个节点即可&#xff0c;如果需要查找元素13&#xff0c;则只需要遍历1->7->10->13四个节点即可。
跳跃链表在并行计算中非常有用&#xff0c;数据插入可以在跳表的不同部分并行进行&#xff0c;而不用全局的数据结构重新平衡。
10
MD5算法
MD5信息摘要算法(英语&#xff1a;MD5 Message-Digest Algorithm)&#xff0c;一种被广泛使用的密码散列函数&#xff0c;可以产生出一个128位(16字节)的散列值(hash value)&#xff0c;用于确保信息传输完整一致。
11
MapReduce
MapReduce是Google提出的一个软件架构&#xff0c;用于大规模数据集(大于1TB)的并行运算。
举例&#xff1a;我们需要查找近10年内数据库相关论文&#xff0c;出现最多的几个单词&#xff0c;以便了解该方向发展态势。
如果逐个查找那么费时费力&#xff0c;我们可以把论文集分成N份&#xff0c;分别放到N台机器上&#xff0c;一台机器跑一个作业&#xff0c;这样就可以并发执行任务。这个方法虽然速度快&#xff0c;但是有部署成本&#xff0c;我们需要把论文集分成不重复的N份&#xff0c;然后将查找程序拷贝到N台机器&#xff0c;而且还需要最后把N个运行结果整合起来。这种方法比较复杂&#xff0c;人工操作比较麻烦&#xff0c;MapReduce就是帮助我们解决这样拆分合并的问题&#xff0c;解放程序员的双手。
Map函数和Reduce函数是交给用户实现的&#xff0c;这两个函数定义了任务本身。
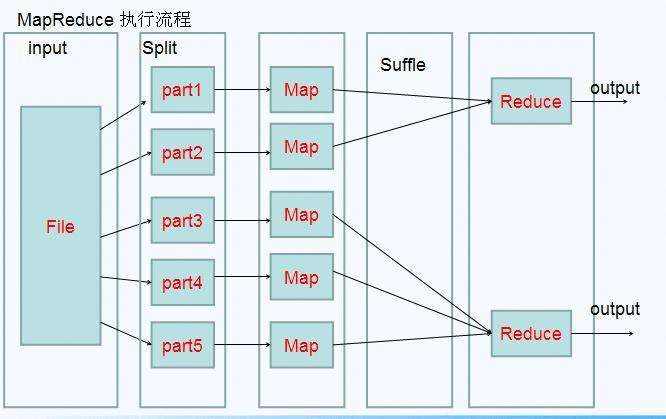
Map函数&#xff1a;接受一个键值对&#xff0c;产生一组中间键值对&#xff0c;Map操作是可以并发执行的。Reduce函数&#xff1a;接受一个键&#xff0c;以及相关的一组值&#xff0c;将这组值进行合并产生一组规模更小的值(通常只有一个或零个值)。
MapReduce框架会将map函数产生的中间键值对里键相同的值传递给一个reduce函数。

你们点点“分享”&#xff0c;给我充点儿电吧~











 京公网安备 11010802041100号
京公网安备 11010802041100号