作者:mobiledu2502908793 | 来源:互联网 | 2023-09-17 05:39
一、meta到底是什么?英文解释:ThetagprovidesmetadataabouttheHTMLdocument.Metadatawillnotbedisplay
一、meta到底是什么?
英文解释:The tag provides metadata about the HTML document. Metadata will not be displayed on the page, but will be machine parsable.
翻译过来就是:标签提供metadata,中文名叫元数据是用于描述数据的数据。它不会显示在页面上,但是机器却可以识别。
二、meta有什么用?
文档中查看到:Meta elements are typically used to specify page description, keywords, author of the document, last modified, and other metadata.
翻译过来就是:meta常用于定义页面的说明,关键字,最后修改日期,和其它的元数据。这些元数据将服务于浏览器(如何布局或重载页面),搜索引擎和其它网络服务。
三、meta的属性
content属性,http-equiv属性,name属性,scheme属性
1. name属性
name属性主要用于描述网页,比如网页的关键词,叙述等。与之对应的属性值为content,content中的内容是对name填入类型的具体描述,便于搜索引擎抓取。meta标签中name属性语法格式是:
<meta name="参数" cOntent="具体的描述">。
其中name属性共有以下几种参数。(A-C为常用属性)
A. keywords(关键字)
说明:用于告诉搜索引擎,你网页的关键字。举例:
<meta name="keywords" cOntent="Lxxyx,博客,文科生,前端">
B. description(网站内容的描述)
说明:用于告诉搜索引擎,你网站的主要内容。举例:
<meta name="description" cOntent="文科生,热爱前端与编程。目前大二,这是我的前端博客">
C. viewport(移动端的窗口)
说明:这个概念较为复杂,具体的会在下篇博文中讲述。这个属性常用于设计移动端网页。在用bootstrap,AmazeUI等框架时候都有用过viewport。
举例(常用范例):
<meta name="viewport" cOntent=">
D. robots(定义搜索引擎爬虫的索引方式)
说明:robots用来告诉爬虫哪些页面需要索引,哪些页面不需要索引。content的参数有all,none,index,noindex,follow,nofollow。默认是all。
举例:
<meta name="robots" cOntent="none">
具体参数如下:
1.none : 搜索引擎将忽略此网页,等价于noindex,nofollow。
2.noindex : 搜索引擎不索引此网页。
3.nofollow: 搜索引擎不继续通过此网页的链接索引搜索其它的网页。
4.all : 搜索引擎将索引此网页与继续通过此网页的链接索引,等价于index,follow。
5.index : 搜索引擎索引此网页。
6.follow : 搜索引擎继续通过此网页的链接索引搜索其它的网页。
E. author(作者)
说明:用于标注网页作者举例:
<meta name="author" cOntent="Lxxyx,841380530@qq.com">
F. generator(网页制作软件)
说明:用于标明网页是什么软件做的举例: (不知道能不能这样写):
<meta name="generator" cOntent="Sublime Text3">
G. copyright(版权)
说明:用于标注版权信息举例:
"copyright" cOntent="Lxxyx">
H. revisit-after(搜索引擎爬虫重访时间)
说明:如果页面不是经常更新,为了减轻搜索引擎爬虫对服务器带来的压力,可以设置一个爬虫的重访时间。如果重访时间过短,爬虫将按它们定义的默认时间来访问。举例:
<meta name="revisit-after" cOntent="7 days" >
I. renderer(双核浏览器渲染方式)
说明:renderer是为双核浏览器准备的,用于指定双核浏览器默认以何种方式渲染页面。比如说360浏览器。举例:
"renderer" cOntent="webkit">
2. http-equiv属性
该属性表示相当于HTTP的作用,比如说定义些HTTP参数啥的。
meta标签中http-equiv属性语法格式是:
<meta http-equiv="参数" cOntent="具体的描述">
其中http-equiv属性主要有以下几种参数:
A. content-Type(设定网页字符集)(推荐使用HTML5的方式)
形式:Content-Type: [type]/[subtype]; parameter
说明:表示后面的文档属于什么MIME类型,用于设定网页字符集,便于浏览器解析与渲染页面举例:
"content-Type" cOntent="text/html;charset=utf-8">
更多type类型参数
Text:用于标准化地表示的文本信息,文本消息可以是多种字符集和或者多种格式的;
Multipart:用于连接消息体的多个部分构成一个消息,这些部分可以是不同类型的数据;
Application:用于传输应用程序数据或者二进制数据;
Message:用于包装一个E-mail消息;
Image:用于传输静态图片数据;
Audio:用于传输音频或者音声数据;
Video:用于传输动态影像数据,可以是与音频编辑在一起的视频数据格式。
B. X-UA-Compatible(浏览器采取何种版本渲染当前页面)
说明:用于告知浏览器以何种版本来渲染页面。(一般都设置为最新模式,在各大框架中这个设置也很常见。)举例:
"X-UA-Compatible" cOntent="IE=edge,chrome=1"/> //指定IE和Chrome使用最新版本渲染当前页面
C. cache-control(指定请求和响应遵循的缓存机制)
用法1.
说明:指导浏览器如何缓存某个响应以及缓存多长时间。这一段内容我在网上找了很久,但都没有找到满意的。最后终于在Google Developers中发现了我想要的答案。
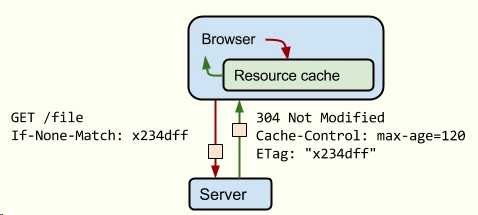
举例:
<meta http-equiv="cache-control" cOntent="no-cache">
共有以下几种用法:
-
no-cache: 先发送请求,与服务器确认该资源是否被更改,如果未被更改,则使用缓存。
-
no-store: 不允许缓存,每次都要去服务器上,下载完整的响应。(安全措施)
-
public : 缓存所有响应,但并非必须。因为max-age也可以做到相同效果
-
private : 只为单个用户缓存,因此不允许任何中继进行缓存。(比如说CDN就不允许缓存private的响应)
-
maxage : 表示当前请求开始,该响应在多久内能被缓存和重用,而不去服务器重新请求。例如:max-age=60表示响应可以再缓存和重用 60 秒。
用法2.(禁止百度自动转码)
说明:用于禁止当前页面在移动端浏览时,被百度自动转码。虽然百度的本意是好的,但是转码效果很多时候却不尽人意。所以可以在head中加入例子中的那句话,就可以避免百度自动转码了。举例:
<meta http-equiv="Cache-Control" cOntent="no-siteapp" />
D. expires(网页到期时间)
说明:用于设定网页的到期时间,过期后网页必须到服务器上重新传输。举例:
<meta http-equiv="expires" cOntent="Sunday 26 October 2016 01:00 GMT" />
E. refresh(自动刷新并指向某页面)
说明:网页将在设定的时间内,自动刷新并调向设定的网址。举例:
"refresh" cOntent="2;URL=http://www.lxxyx.win/">
F. Set-COOKIE(COOKIE设定)
说明:如果网页过期。那么这个网页存在本地的COOKIEs也会被自动删除。
"Set-COOKIE" cOntent="name, date">
G.MSThemeCompatible
说明:是否在ie里关闭xp的蓝色立体按钮系统显示样式
H.MSSmartTagsPreventParsing
说明:防止微软页面编辑软件在页面上自动添加,保证代码的原汁原味
3.content属性
content 属性提供了名称/值对中的值。该值可以是任何有效的字符串。
content 属性始终要和 name 属性或 http-equiv 属性一起使用。
4.scheme属性
scheme 属性用于指定要用来翻译属性值的方案。此方案应该在由 标签的 profile 属性指定的概况文件中进行了定义。
该文档转自 傻瓜不傻的博客
https://www.cnblogs.com/wangyang108/p/5995379.html
meta标签的总结

 京公网安备 11010802041100号
京公网安备 11010802041100号