Logstash附带了许多input,codec,filter和output插件,可用于从各种应用程序,服务器和网络通道中检索,转换,过滤和发送日志和事件。如果大家对Logstash还没有初步的了解,请参阅我之前的文章:
在本文中,我们将继续探索Logstash输入插件的丰富世界,重点关注Beats系列(例如Filebeat和Metricbeat),各种文件和系统输入插件,网络,电子邮件和聊天协议,云平台,Web应用程序, 和消息代理/平台。 Logstash当前支持50多个输入插件-将来还会有更多插件-因此不可能在一篇文章中介绍所有这些插件。 因此,我们决定概述一些最受欢迎的输入插件类别,以大致了解Logstash的用途。
什么是Logstash input 插件Logstash用作日志管道,用于侦听来自已配置日志源(例如,应用程序,数据库,消息代理)的事件,使用过滤器和编解码器对其进行转换和格式化,并运送到输出位置(例如,Elasticsearch或Kafka)(请参见 下图)。
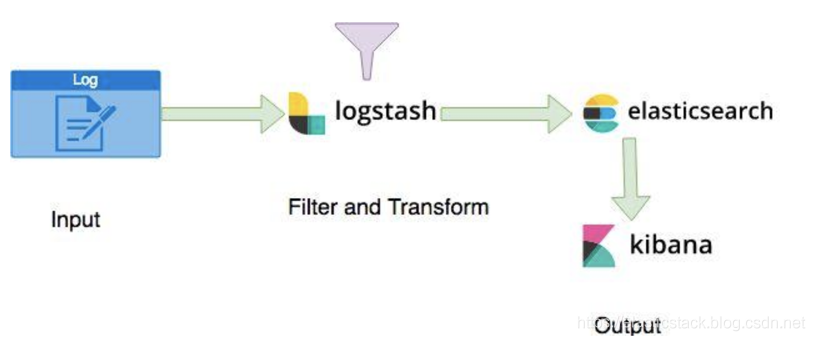
Logstash如此强大,因为它可以聚合来自多个源(例如Redis,Apache HTTP或Apache Kafka)的日志,这些源位于多个节点上,并将它们放入由多个工作程序和线程管理的高效日志处理队列中。 Logstash优化了输入和输出目标之间的日志流,从而确保了容错性能和数据完整性。 Logstash的最大优点之一是可以使用众多过滤器和编解码器,这些过滤器和编解码器可以从日志中提取模式并将日志转换为适合在Elasticsearch和Kibana中进行分析的丰富数据对象。 这些功能使原始日志能够快速转换为可操作的见解,从而使您的业务受益。
输入插件是Logstash管道的重要组件,它们充当输入日志源和Logstash过滤功能之间的中间件。 通常,每个输入插件都允许连接到指定的日志源提供程序并使用其API提取日志。
查看Logstash的所有input插件在logststash的安装目录下,通过如下的命令来查询所有内置的Logstash的输入插件:
./bin/logstash-plugin list --group input
显示结果如下:
logstash-input-azure_event_hubs
logstash-input-beats
logstash-input-couchdb_changes
logstash-input-elasticsearch
logstash-input-exec
logstash-input-file
logstash-input-ganglia
logstash-input-gelf
logstash-input-generator
logstash-input-graphite
logstash-input-heartbeat
logstash-input-http
logstash-input-http_poller
logstash-input-imap
logstash-input-jdbc
logstash-input-jms
logstash-input-pipe
logstash-input-redis
logstash-input-s3
logstash-input-snmp
logstash-input-snmptrap
logstash-input-sqs
logstash-input-stdin
logstash-input-syslog
logstash-input-tcp
logstash-input-twitter
logstash-input-udp
logstash-input-unix
在我们之前的一些教程中,我们已经探讨了其中的一些输入插件的使用了。在今天的内容中,我们将介绍其中的一些。
Logstash input pluginsElastic Beats系列包括许多针对各种数据(日志,指标,事件等)的摄入。在以前的教程中,我们广泛介绍了Filebeat用于日志传送,Packetbeat用于网络数据传送以及Metricbeat用于系统和应用程序指标监视。 Elasticsearch还提供Windows事件日志的Winlogbeat,审计数据的Auditbeat和正常运行时间监视的Heartbeat。其中的一些发件人(例如Filebeat)允许将日志直接传送到您的Elasticsearch索引。
随之而来的自然问题是:为什么要使用Logstash呢?
主要有两个原因:
在Logstash中使用Beats组件非常简单:
input {
beats {
port => 5044
}
}
output {
elasticsearch {
hosts => ["IP Address 1:port1", "IP Address 2:port2", "IP Address 3"]
}
}
例如,上面的输入配置告诉Logstash监听5044端口上的Beats事件,并将它们直接发送到Elasticsearch。在我的github中有一个具体的例子,你可以在地址https://github.com/liu-xiao-guo/beats-getstarted找到相应的文件。
Logstash非常适合从操作系统中的文件,bash命令,syslog和其他常见日志源中传送日志。 我们将只讨论该类别中的两个输入插件:Exec输入插件和File输入插件。 其他可用的解决方案包括用于从长时间运行的命令管道中读取事件的Pipe input plugin和用于通过网络读取系统日志消息和事件的Syslog plugin。
让我们从Exec输入插件开始。 该插件使您可以定期在系统中运行bash命令,并将其输出发送到Logstash。 此功能对于监视系统状态并在Kibana中可视化它可能很有用。 例如,如果您对主机上当前正在运行的顶级进程感兴趣,则可以告诉Logstash每30秒运行一次Linux top命令,以显示当前正在运行的进程。
top.conf
input {
exec {
command => "top -l 1"
interval => 5
}
}
output {
stdout {
codec => rubydebug
}
elasticsearch {
index => "top"
hosts => "localhost:9200"
document_type => "_doc"
}
}
您可以类似的方式使用系统支持的任何命令。
该组中的另一个插件,即File input plugin,允许通过类似于类似Unix的系统上的tail -0F命令的方式尾随事件来流式处理文件中的事件。 本质上,此插件用作文件监视程序,将文件末尾的新行视为新事件。 此功能使该插件可用于在添加新行时跟踪更改的日志文件。 另外一个好处是,该插件将当前位置存储在它跟踪的每个文件中,这样它就可以从停止和重新启动Logstash时从中断处开始。
input {
file {
path => "/var/log/*.log"
}
}
该插件支持上述示例中的Globe模式。 此输入配置告诉插件在/var/log/文件夹中监视扩展名为.log的所有文件。
如果您想有一个具体的例子,请参阅我之前的文章“Logstash:处理多个input”。
Logstash为各种网络,进程间通信(IPC),聊天和电子邮件协议生成的事件和日志提供了出色的支持。 让我们从常见的网络和IPC协议开始。 Logstash支持UDP,Unix域套接字,Websocket,HTTP等。
该插件允许通过UDP通过网络将消息作为事件读取。 插件唯一需要的配置字段是port,它指定Logstash侦听事件的UDP端口。
udp.conf
input {
udp {
port => 25000
workers => 4
codec => json
}
}
output {
stdout {
codec => rubydebug
}
elasticsearch {
index => "udp"
hosts => "localhost:9200"
document_type => "_doc"
}
}
当我们运行起来我们的logstash,我们可以使用如下的命令在另外一个console中运行如下的命令:
nc -u localhost 25000

那么在我们的Kibana中,我们可以看到:
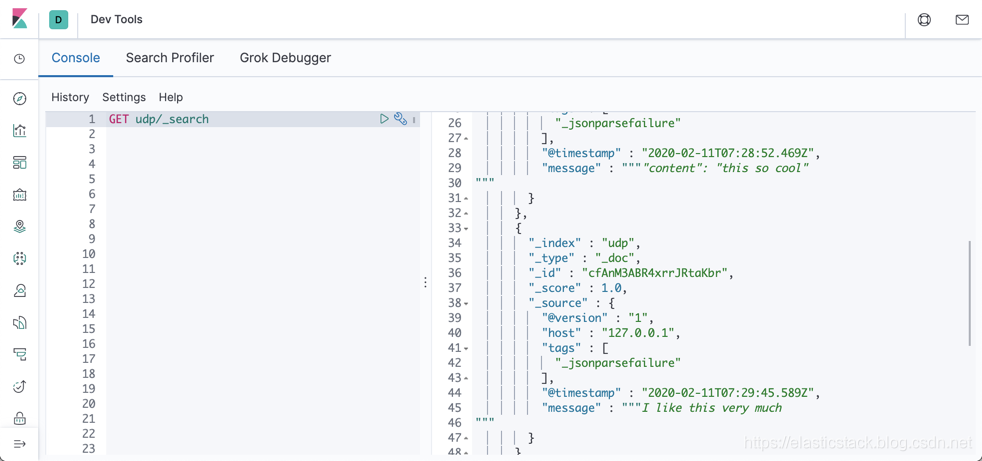
如以上示例所示,您可以选择使用JSON编解码器将UDP消息转换为JSON对象,以便在Elasticsearch中进行更好的处理。 您还可以使用queue_size参数控制消息队列的大小,并使用worker参数指定用于处理UDP数据包的工作线程数。
UNIX套接字是一种进程间通信(IPC)机制,它允许在同一计算机上运行的进程之间进行双向数据交换。 您可以使用此插件捕获应用程序发出的Unix域套接字事件(消息)。 与文件输入插件类似,每个事件等于套接字发出的一行文本。 该插件支持两种模式:服务器和客户端。 在服务器模式下,它将监听客户端连接,在客户端模式下,观察客户端何时连接到服务器。
socket.conf
input {
unix {
mode => "server"
path => "/var/logstash/ls"
data_timeout => 2
}
}
output {
stdout {
codec => rubydebug
}
elasticsearch {
index => "udp"
hosts => "localhost:9200"
document_type => "_doc"
}
}
在上面的输入配置中,我们在服务器模式下使用插件,并将其配置为侦听在/var/logstash/ls路径中生成的Unix域套接字事件。
WebSocket协议使Web客户端(例如,浏览器)和Web服务器之间的交互具有较低的开销,从而实现了实时数据传输并允许在保持连接打开的同时来回传递消息。 Websocket插件允许从打开的Websocket连接读取事件。 唯一必需的参数是打开Websocket连接的URL。
这个websocket的 Input plugin是在默认的情况下没有安装的,我们需要按照如下的方法来进行安装:
bin/logstash-plugin install logstash-input-websocket
websocket.conf
input {
websocket {
mode => "client"
url => "ws://127.0.0.1:8081/"
type => "string"
}
}
output {
stdout {
codec => rubydebug
}
elasticsearch {
index => "udp"
hosts => "localhost:9200"
document_type => "_doc"
}
}
插件当前支持的唯一模式是客户端模式,在该模式下,插件连接到Websocket服务器并从该服务器接收事件作为Websocket消息。
我们首先可以用如下的一个Websocket 服务器来做测试:
git clone https://github.com/sitepoint-editors/websocket-demo.git
cd websocket-demo
npm install
npm start
这样我们就可以启动一个ws的服务器,它运行于这个口地址ws://127.0.0.1:8081/。
接下来我们启动我们的logstash,然后我们可以在console中看到:
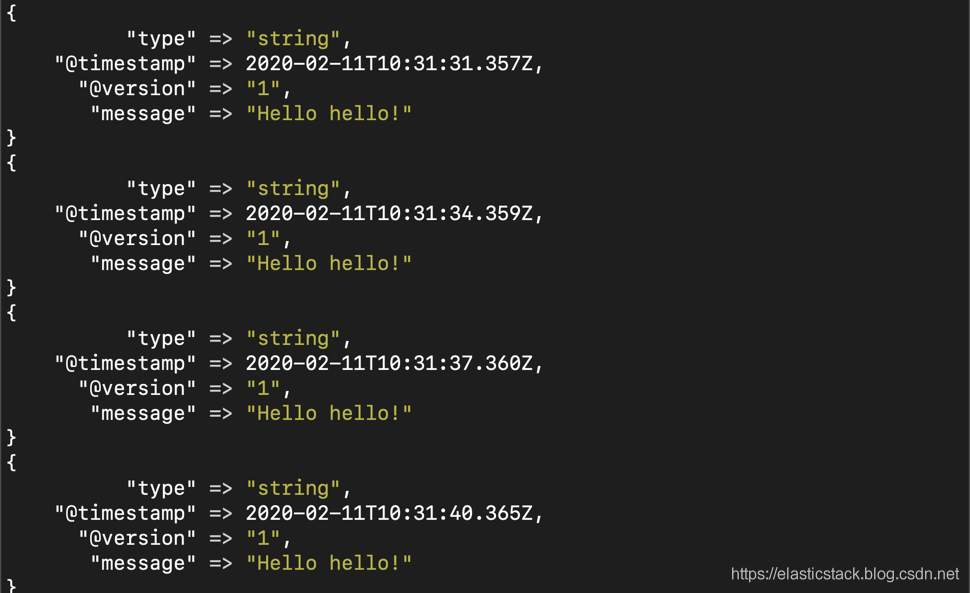
这个是在我们的websocket_demo中定时发送给websocket的信息。
HTTP Input Plugin将HTTP Post请求(带有由应用程序发送的正文)转换为插件指定的端点,Logstash会将消息转换为事件。 应用程序可以将JSON,纯文本或任何格式的数据传递到端点,并使用相应的编解码器来转换消息。 该插件还可用于接收Webhook请求以与其他应用程序和服务集成(类似于GitHub Webhook输入所做的事情)。
通过利用Logstash中可用的庞大插件生态系统,您可以直接在应用程序中触发Logstash中的可操作事件,并将其发送到Elasticsearch。 该插件支持HTTP基本身份验证标头和SSL,可通过https安全地发送数据,并提供验证客户端证书的选项。
如果大家想了解一个具体的例子,请参阅我之前的文章“Logstash:运用jdbc_streaming来丰富我们的数据”。
HTTP Poller插件是Logstash中另一个基于HTTP的输入插件,它允许调用HTTP API,将响应消息转换为事件并将消息沿管道发送(例如,发送到Elasticsearch)。
例如,下面配置的插件从路由到Elasticsearch集群的URL中读取,使用JSON编解码器解码和转换响应的主体,并将编码后的数据保存在metas_target变量中。 配置看起来像这样:
input {
http_poller {
urls => {
test1 => "http://localhost:9200"
test2 => {
# Supports all options supported by ruby's Manticore HTTP client
method => get
user => "AzureDiamond"
password => "hunter2"
url => "http://localhost:9200/_cluster/health"
headers => {
Accept => "application/json"
}
}
}
request_timeout => 60
# Supports "cron", "every", "at" and "in" schedules by rufus scheduler
schedule => { cron => "* * * * * UTC"}
codec => "json"
# A hash of request metadata info (timing, response headers, etc.) will be sent here
metadata_target => "http_poller_metadata"
}
}
output {
stdout {
codec => rubydebug
}
}
我们可以看到像如下的输出:
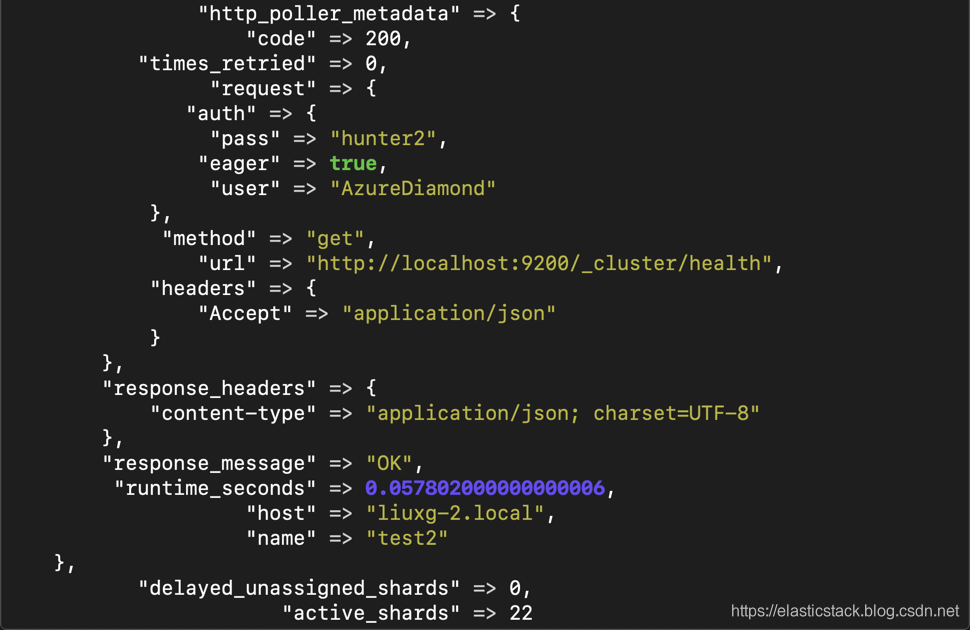
如果您对一个具体的例子感兴趣,请参阅我的另外一篇文章“Logstash:使用ELK堆栈进行API分析”。
在物联网,微服务和实时应用程序时代,应用程序之间的数据流和实时消息传递非常流行。 Logstash对各种消息代理和数据流平台都有很好的支持。 在本节中,我们将仅讨论其中的一些。 让我们开始吧!
Google Cloud Pub/Sub为云中的应用程序实现了发布/订阅消息传递模式。 它是一种中间件,为发布者提供API来创建某些主题以向其发送消息,为发布者提供API来为这些主题创建订阅。 该平台以低延迟和强大的安全性支持多对多和异步消息传递。 您可以轻松地通过Google Pub / Sub从Google Pub / Sub API提取事件,还可以根据需要使用Stackdriver Logging消息。
要使用该插件,如果您在Google平台之外运行Logstash,则必须设置一个Google项目和一个Google Cloud Platform服务帐户。 为了使插件正常工作,您还应该手动创建主题,指定订阅并在Logstash配置文件中引用它们。
以下是该插件的基本配置:
input {
google_pubsub {
# Your GCP project id (name)
project_id => "my-project-99234"
# A topic to read messages from
topic => "logstash-test-log"
subscription => "logstash-sub"
# If you are running logstash within GCE, it will use
# Application Default Credentials and use GCE's metadata
# service to fetch tokens. However, if you are running logstash
# outside of GCE, you will need to specify the service account's
# JSON key file below.
#json_key_file => "/home/erjohnso/pkey.json"
}
}
output { stdout { codec => rubydebug } }
Apache Kafka是一个流平台,结合了消息队列和发布/订阅功能。 Kafka对于为系统或应用程序构建实时流数据管道以及构建对数据流进行转换或做出反应的实时流应用程序非常有用。与Google Pub/Sub相似,Kafka包括可以创建提取任意数据的主题的发布者,以及可以订阅一个或多个这些主题的消费者。此外,Kafka包括Streams API,该API允许应用程序作为流处理器运行,以转换数据并将其传递到某些输出。 Kafka是一个分布式且可扩展的系统,其中的主题可以分为多个分区,这些分区分布在集群中的多个节点上。
Logstash Kafka插件可轻松与Kafka Producer和Consumer API集成。您可以使用默认偏移量管理策略指定多个要订阅的主题。该插件的一个强大功能是,您可以运行多个读取同一主题的Logstash实例,以便在多个物理机之间分配负载。要使用此功能,您需要指定一个group_id,该组创建一个由多个处理器组成的单个逻辑订户。主题中的消息将分发到具有相同group_id的所有Logstash实例。
input {
kafka {
bootstrap_servers => "localhost:9092"
topics => "test"
group_id => "99ds9932"
}
}
RabbitMQ是流行的消息传递代理,用于存储和交换消息。 它支持使用各种方法(例如发布/订阅模式,工作队列和异步处理)进行数据传递。 所有这些都支持多种消息协议和分布式消息环境。
默认情况下,如果启用了@metadata_enabled设置,RabbitMQ输入插件将侦听RabbitMQ队列中的所有消息,并将消息属性保存在[@metadata] [rabbitmq_properties]字段中。 例如,要将RabbitMQ邮件的timestamp属性保存到Logstash事件的@timestamp字段中,则可以使用日期过滤器来解析[@metadata] [rabbitmq_properties] [timestamp]字段:
filter {
if [@metadata][rabbitmq_properties][timestamp] {
date {
match => ["[@metadata][rabbitmq_properties][timestamp]", "UNIX"]
}
}
}
Logstash对各种云提供商服务(如Amazon S3)和Web应用程序(如Salesforce和Twitter)提供了强大的支持。 该类别中有太多输入插件需要提及,因此我们仅关注其中一些。
Amazon S3 Input插件与Amazon S3集成-对象存储旨在构建和存储网站和移动应用程序,公司软件以及IoT传感器和设备中的数据并从中检索数据。
Amazon S3输入插件可以采用与上述文件输入插件类似的方式从S3存储桶中的文件流式传输事件。 与File Input插件一样,S3存储桶中每个文件的每一行都会生成一个事件,Logstash将捕获该事件。 要使用此插件,您需要配置S3存储桶和AWS凭证才能访问该存储桶。
input{
s3{
bucket => 'bucket_name'
region => 'eu-west-1'
access_key_id => YOUR AWS ACCESS KEY
secret_access_key => YOUR AWS SECRET KEY
}
}
Twitter输入插件使使用ELK堆栈将Twitter数据发送到Elasticsearch并将其用于分析Twitter趋势变得简单。 该插件可以从Twitter Streaming API提取事件,并将其直接传送到Elasticsearch。 该API允许跟踪多个用户的推文和转发,并回复用户创建的任何推文,按语言,用户位置,文本中的关键字等过滤推文。您还可以使用Logstash过滤器进一步细化事件并创建 可以稍后在Elasticsearch中分析的字段。
input {
twitter {
consumer_key => "consumer_key"
consumer_secret => "consumer_secret"
oauth_token => "access_token"
oauth_token_secret => "access_token_secret"
keywords => ["AWS","Qbox","Elasticsearch"]
full_tweet => true
}
}
Amazon CloudWatch是一项AWS云监控服务,它允许监控AWS应用程序和实例以获取有关您的云部署的可行见解。 该平台收集各种类型的操作数据,例如日志,指标和事件。 您可以使用CloudWatch来配置高分辨率警报,可视化日志,执行自动操作,解决问题并发现见解。
您可以使用Logstash CloudWatch输入插件直接从AWS CloudWatch连接到事件流。 与其他AWS插件一样,您将需要AWS凭证才能使用CloudWatch输入。
将EC2指标数据流传输到Logstash的示例配置如下所示:
input {
cloudwatch {
namespace => "AWS/EC2"
metrics => [ "CPUUtilization" ]
filters => { "tag:Group" => "Production" }
region => "ap-southeast-2"
}
}
从上面的示例中可以看到,该插件允许配置各种过滤器,以定义要从CloudWatch获取的指标并设置返回数据点的粒度。
结论显然,Logstash支持各种流行的日志和事件源。 特别是,您可以将输入插件用于许多主要的网络协议,消息代理,IRC服务器,数据库,云服务和Web应用程序。
更重要的是,Logstash可以通过网络接收bash命令,系统日志和其他系统信息,本地文件和文件,将它们转换为有价值的事件,并过滤和丰富日志,以供ELK堆栈中的后续分析或您喜欢的任何其他日志分析解决方案 。 所有这些功能使Logstash成为用于传输和规范化数据的ELK堆栈的强大组件。
本概述中讨论的插件只是Logstash社区提供的冰山一角。 查看Logstash官方文档以了解更多信息-并继续关注即将推出的Logstash教程,以了解Logstash插件的特定用例。






 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有 