Deep Learning for 3D Point Clouds: A Survey
论文链接:https://arxiv.org/abs/1912.12033
摘要
点云学习因其在计算机视觉、自动驾驶、机器人等领域的广泛应用而受到越来越多的关注。深度学习作为人工智能的主流技术,已经成功地应用于解决各种二维视觉问题。然而,由于用深度神经网络处理点云所面临的独特挑战,点云的深度学习仍处于起步阶段。最近,关于点云的深入学习变得更加繁荣,有许多方法被提出来解决这一领域的不同问题。为了促进未来的研究,本文综述了点云深度学习方法的最新进展。它包括三个主要任务,包括三维形状分类、三维目标检测与跟踪和三维点云分割。它还提供了几个公开数据集的比较结果,以及富有洞察力的观察和启发未来的研究方向。
INTRODUCTION
随着3D采集技术的快速发展,3D传感器变得越来越可用且价格实惠,包括各种类型的3D扫描仪、激光雷达和RGB-D相机(如Kinect、RealSense和Apple深度相机)。这些传感器获取的三维数据可以提供丰富的几何、形状和比例信息。借助于二维图像,三维数据为更好地了解机器周围环境提供了机会。三维数据在不同领域有着广泛的应用,包括自动驾驶、机器人技术、遥感和医疗。
三维数据通常可以用不同的格式表示,包括深度图像、点云、网格和体积网格。点云表示作为一种常用的表示格式,在三维空间中保留了原始的几何信息,而不需要进行任何离散化。因此,它是许多场景理解相关应用的首选表示,如自主驾驶和机器人技术。近年来,深度学习技术已成为计算机视觉、语音识别、自然语言处理等领域的研究热点。然而,三维点云的深度学习仍然面临着几个重大的挑战,如数据集的小规模、高维性和三维点云的非结构化性质。在此基础上,重点分析了用于三维点云处理的深度学习方法。
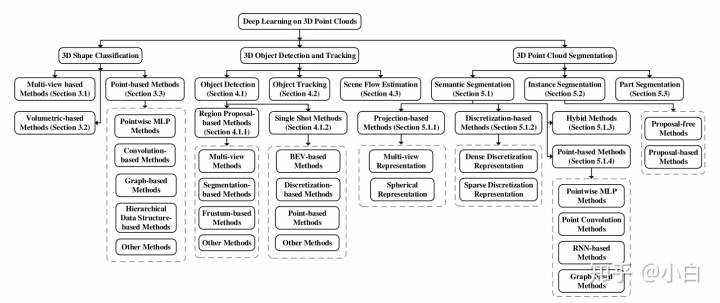
点云的深度学习越来越受到人们的关注,特别是近五年来。还发布了一些公开数据集,例如 ModelNet、ScanObjectNN、ShapeNet、PartNet、S3DIS、ScanNet、Semantic3D、ApololCar3D和KITTI Vision基准套件。这些数据集进一步推动了三维点云深度学习的研究,越来越多的方法被提出来解决与点云处理相关的各种问题,包括三维形状分类、三维目标检测与跟踪、三维点云分割、三维点云配准等,六自由度姿态估计和三维重建。关于三维数据的深度学习的调查也很少,我们的论文是第一次专门关注点云理解的深度学习方法。图1显示了一个现有的点云学习方法。
图1:三维点云深度学习方法的分类。3D SHAPE CLASSIFICATION
Public Datasets
- ModelNet (CVPR'15) [paper] [project page]
- ModelNet10 [data] [results]
- ModelNet40 [data] [results]
- PartNet (CVPR'19) [paper] [data] [project page]
- ScanObjectNN (ICCV'19) [paper] [data] [project page]
此任务的方法通常是先学习每个点的嵌入,然后使用聚合方法从整个点云中提取全局形状嵌入。最后通过将全局嵌入嵌入到几个完全连通的层中来实现分类。根据神经网络输入的数据类型,现有的三维形状分类方法可分为基于多视图、基于体积和基于点的方法。
基于多视图的方法将非结构化点云投影到二维图像中,而基于体积的方法将点云转换为三维体积表示。然后,利用成熟的二维或三维卷积网络实现形状分类。相比之下,基于点的方法直接在原始点云上工作,而不需要任何体素化或投影。基于点的方法不会引入显性信息丢失并日益流行。
Multi-view based Methods 首先将一个三维图形投影到多个视图中,然后提取各个视图的特征,然后融合这些特征进行精确的形状分类。如何将多视图特征聚合成一个有区别的全局表示是这些方法的一个关键挑战。
- MVCNN(CVPR'15)[paper][code][video][翻译]
Multi-view Convolutional Neural Networks for 3D Shape Recognition(MVCNN)是一个开创性的工作,它简单地将多视图特性汇集到一个全局描述符中。但是,最大池只保留特定视图中的最大元素,从而导致信息丢失。
Volumetric-based Methods 通常将点云体素化为三维网格,然后将三维卷积神经网络(CNN)应用于体表示进行形状分类。
- VoxNet(IROS'15)[paper][code][翻译]
VoxNet: A 3D convolutional neural network for real-time object recognition(VoxNet)网络、基于卷积深信度的三维形状网,虽然已经取得了令人鼓舞的性能,但由于计算量和内存占用随着分辨率的增加而呈立方体增长,因此这些方法无法很好地适应密集的三维数据。
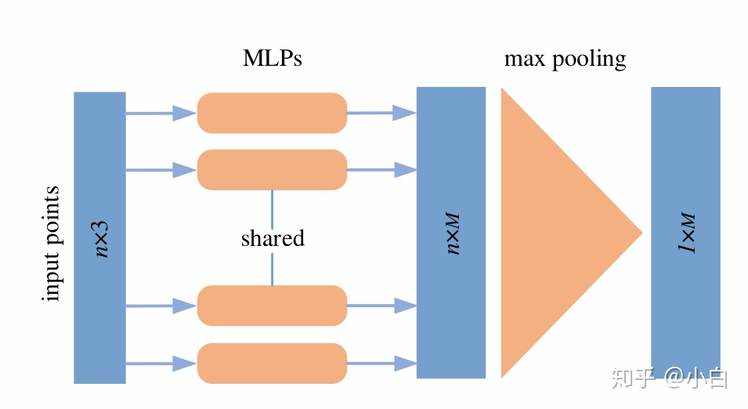
Pointwise MLP Methods 使用多个共享多层感知器(MLP)独立地对每个点建模,然后使用对称聚合函数聚合全局特征,如图3所示。典型的二维图像深度学习方法由于其固有的数据不规则性而不能直接应用于三维点云。
图3:PointNet的轻量级架构。n表示输入点的个数,M表示每个点学习特征的维数。- PointNet[paper][code][翻译]
- PointNet++[paper][code][翻译]
PointNet: Deep learning on point sets for 3D classification and segmentation(PointNet) 直接以点云作为输入并实现对称函数的置换不变性。PointNet使用几个MLP层独立地学习点态特征,并使用最大池化层提取全局特征。由于PointNet中每个点的特征都是独立学习的,因此无法获取点之间的局部结构信息。因此,提出了一种层次网络pointnet++来从每个点的邻域中捕捉精细的几何结构。作为PointNet++层次结构的核心,其集合抽象层由三层组成:采样层、分组层和基于PointNet的学习层。通过叠加多个集合抽象层次,pointnet++从局部几何结构中学习特征,并逐层抽象局部特征。
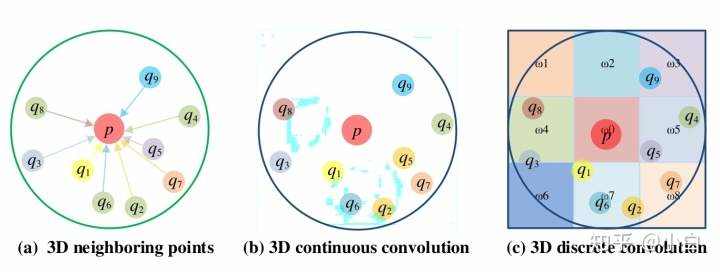
Convolution-based Methods 与二维网格结构(如图像)上定义的卷积核相比,由于点云的不规则性,三维点云的卷积核很难设计。根据卷积核的类型,目前的三维卷积方法可分为连续卷积法和离散卷积法,如图4所示。
图4:一个点的局部邻域的连续和离散卷积的图示。(a)表示以点p为中心的局部邻域qi;(b)和(c)分别表示三维连续卷积和离散卷积3D Continuous Convolution Methods 定义了连续空间上的卷积核,其中相邻点的权重与相对于中心点的空间分布有关。
PointConv(CVPR'19)[paper][code][翻译]
ConvPoint(Computers & Graphics)[journal paper] [conference paper][code]
3D Discrete Convolution Methods 在规则网格上定义卷积核,其中相邻点的权重与相对于中心点的偏移量有关。
Graph-based Methods 将点云中的每个点看作图的顶点,并根据每个点的邻域生成有向边。然后在空间或光谱域中进行特征学习。典型的基于图的网络如图5所示。
图5:基于图的网络示意图。3D Object Detection
Public Datasets
- KITTI (CVPR'12) [paper] [project page]
- 3D objecct detection [data] [results]
- BEV [data] [results]
- ApolloScape (TPAMI'19) [paper] [data] [results]
- Argoverse (CVPR'19) [paper] [data] [project page]
- A*3D (arXiv'19) [paper] [data] [project page]
- Waymo (arXiv'19) [paper] [data] [project page]
典型的3D对象检测器以场景的点云为输入,在每个检测到的对象周围生成一个定向的3D边界框,如图6所示。与图像中的目标检测相似,三维目标检测方法可分为两类:基于区域建议的方法和单次拍摄方法。
图6:3D物体检测的图示。3D Point Cloud Segmentation
Public Datasets
- Semantic3D (ISPRS'17) [paper] [project page]
- semantic-8 [data] [results]
- reduced-8 [data] [results]
- S3DIS (CVPR'17) [paper] [data] [project page]
- ScanNet (CVPR'17) [paper] [data] [project page] [results]
- NPM3D (IJRR'18) [paper] [data] [project page] [results]
- SemanticKITTI (ICCV'19) [paper] [data] [project page] [results]
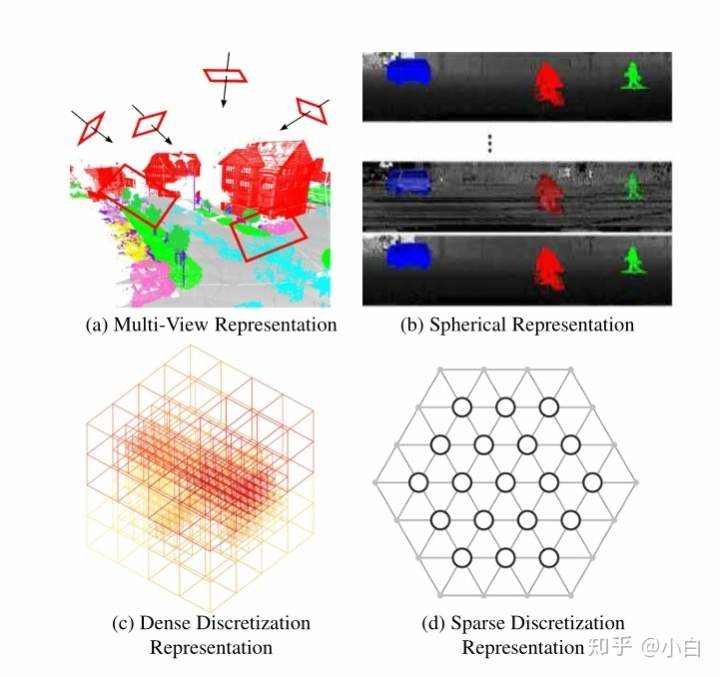
给定一个点云,语义分割的目标是根据点的语义将其分割成若干个子集。语义分割有四种模式:基于投影、基于离散化、基于点和混合方法。基于投影和离散化的方法的第一步都是将点云转换为中间正则表示,如多视图、球面、体积、全自动晶格和混合表示,如图11所示。然后将中间分割结果投影回原始点云。相比之下,基于点的方法直接作用于不规则的点云。
图11:中间表示的图示。需要进一步研究的问题有:
- 基于点的网络是最常被研究的方法。然而,点表示自然不具有显式的邻近信息,现有的大多数基于点的方法不得不借助于昂贵的邻近搜索机制(如KNN或ball query)。这从本质上限制了这些方法的效率,因为邻居搜索机制既需要很高的计算成本,又需要不规则的内存访问。
- 从不平衡数据中学习仍然是点云分割中一个具有挑战性的问题。虽然有几种的方法取得了显著的综合成绩,但它们在类标很少的情况下表现仍然有限。例如,RandLA-Net在Semantic3D的reduced-8子集上获得了76.0%的整体IoU,而在hardscape类上获得了41.1%的非常低的IoU。
- 大多数现有的方法都适用于小点云(如1m*1m,共4096个点)。在实际中,深度传感器获取的点云通常是巨大的、大规模的。因此,有必要进一步研究大规模点云的有效分割问题。
- 已有少数文献开始研究动态点云的时空信息。预期时空信息可以帮助提高后续任务的性能,如三维目标识别、分割和完成。
仅作为个人学习笔记总结。
欢迎技术交流。










 京公网安备 11010802041100号
京公网安备 11010802041100号