lucene:apache下的一个开放源代码的全文检索引擎工具包(jar),通过它可以实现全文检索。
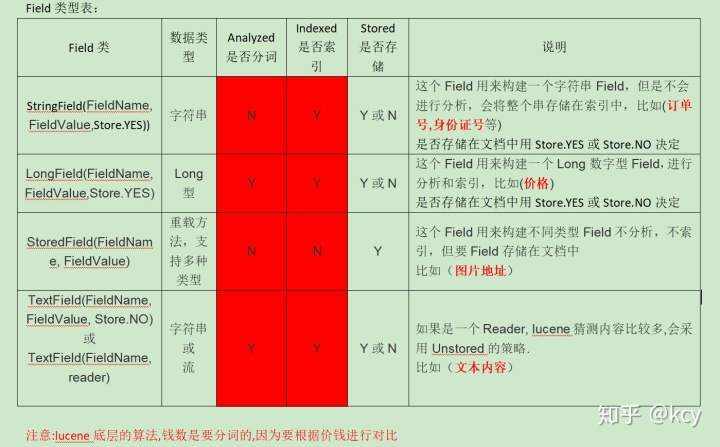
Field 域的详细介绍
是否分词:是否对域的内容进行分词处理。
比如:订单号、身份证号不需要分词
是否索引:将Field分析后的词进行索引,只有索引方可搜索到。
比如:商品名称、商品简介分析后进行索引,订单号、身份证号不用分析但也要索引,这些将来都要作为查询条件。
是否存储:将Field值存储在文档中,存储在文档中的Field才可以从Document中获取
比如:商品名称、订单号,凡是将来要从Document中获取的Field都要存储。
1、标准
- 分词:是否有意义
- 索引:是否要进行检索
- 存储:是否要显示
2、field的类型
分词 索引 存储
TextField y y y|n
StringField n y y|n
StoredField n n y
LongField y y y|n
----------------------------------------------------------------------
中文分词器 IK-analyzer
第一步:把jar包添加到工程pom文件中
第二步:把配置文件和扩展词典和停用词词典添加到项目中
----------------------------------------------------------------------
lucene实现全文检索:
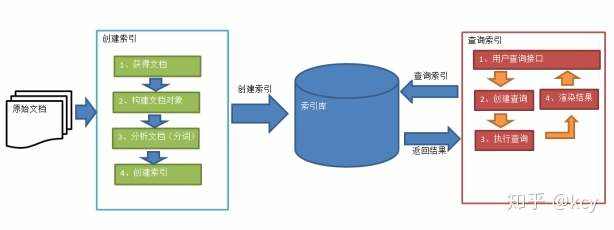
索引和检索流程图:
1、绿色表示索引过程,对要搜索的原始内容进行索引构建一个索引库,索引过程包括:获得原始文档à创建文档对象à分析文档à创建索引
2、红色表示搜索过程,从索引库中搜索内容,搜索过程包括:用户通过搜索界面à创建查询à执行搜索,从索引库搜索à渲染搜索结果
1.创建索引
2.创建文档对象
//文档对象,文件系统中的一个文件就是一个Docuemnt对象
3. Ik中文分词器
4.创建索引
第二步:查询索引
第一步:创建一个Directory对象,并指定索引和文档的目录。
第二步:创建一个indexReader对象,并指定Directory对象。
第三步:创建一个indexsearcher对象,并指定IndexReader对象
第四步:创建一个QueryParser对象,并指定(默认收索域、分词器)和查询的关键词。
(Ik中文分词器)
//创建分词器(创建索引和所有时所用的分词器必须一致)
第五步:执行查询。
//搜索:第一个参数为查询语句对象, 第二个参数:指定显示多少条
第六步:返回查询结果。遍历查询结果并输出。
第七步:关闭IndexReader对象










 京公网安备 11010802041100号
京公网安备 11010802041100号