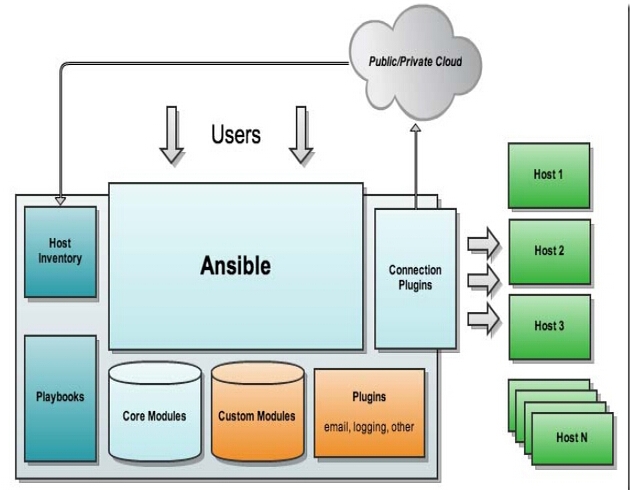
5.x版本 logstash中 elasticsearch插件的workers,无法配置大于1,会提示 This plugin uses the shared and doesn't need this option
这个的意思是进到logstash本身的配置文件pipeline.output.workers。
不要一开始就修改workers个数。这也许是一个误区。虽然确实可以起到一些作用。
检查cpu
请注意CPU是否被大量使用。 在Linux / Unix上,运行top -H以查看线程分解的进程统计信息,以及总CPU统计信息。
如果CPU使用率很高,请跳到有关检查JVM堆的部分,然后阅读有关调整Logstash工作线程设置的部分。
检查内存
请注意Logstash在Java VM上运行的事实。 这意味着Logstash将始终使用您分配给它的最大内存量。
查找使用大量内存的其他应用程序,并可能导致Logstash切换到磁盘。 如果应用程序使用的总内存超过物理内存,则会发生这种情况。
检查IO
监视磁盘I / O以检查磁盘饱和。
如果使用Logstash插件(例如文件输出),可能会使存储饱和,则可能会出现磁盘饱和。
磁盘饱和也可能发生,如果你遇到很多错误,强制Logstash生成大的错误日志。
在Linux上,可以使用iostat,dstat或类似于监视磁盘I / O的东西。
监视网络I / O以实现网络饱和。
如果使用执行大量网络操作的输入/输出,则可能发生网络饱和。
在Linux上,可以使用诸如dstat或iftop之类的工具来监视网络。
通常情况下,如果堆大小太低,CPU利用率经常过限制(百分之百),导致JVM不断进行垃圾回收。
检查此问题的快速方法是将堆大小加倍,并查看性能是否提高。 不要增加超过物理内存量的堆大小。 为操作系统和其他进程保留至少1GB的空闲空间。
可以使用随Java分发的jmap命令行实用程序或使用VisualVM对JVM堆进行更准确的度量。
调整Logstash工作线程设置:
首先使用-w标志扩大管道工作线程的数量。 这将增加可用于过滤器和输出的线程数。 如果需要,可以安全地将其扩展到多个CPU内核,因为线程可以在I / O上变为空闲。
默认情况下,每个输出只能在单个管道工作线程中处于活动状态。 可以通过更改每个输出的配置块中的workers设置来增加此值。 不要使此值大于管道工人的数量。
还可以调整输出批处理大小。 对于许多输出,例如Elasticsearch输出,此设置将对应于I / O操作的大小。 在Elasticsearch输出的情况下,此设置对应于批处理大小。
pipeline.batch.size设置定义单个工作线程在尝试执行过滤器和输出之前收集的最大事件数。 较大的批量大小通常更高效,但增加了内存开销。 某些硬件配置要求您通过设置LS_HEAP_SIZE变量来增加JVM堆大小,以避免使用此选项导致性能下降。 此参数的值超过最佳范围会导致由于频繁的垃圾回收或与内存不足异常相关的JVM崩溃而导致性能下降。 输出插件可以将每个批处理作为逻辑单元处理。 例如,Elasticsearch输出针对接收的每个批生产批量请求。 调整pipeline.batch.size设置可调整发送到Elasticsearch的批量请求的大小。
pipeline.batch.delay设置很少需要调整。 此设置调整Logstash管道的延迟。 流水线批处理延迟是Logstash在当前管道工作线程中接收到事件后等待新消息的最大时间(毫秒)。 在此时间过后,Logstash开始执行过滤器和输出.Logstash在接收事件和在过滤器中处理该事件之间等待的最大时间是pipeline.batch.delay和pipeline.batch.size设置的乘积。
如果计划修改默认管道设置,请考虑以下建议:
事件的总数由pipeline.workers和pipeline.batch.size设置的乘积确定。称为流动计数。 在调整pipeline.workers和pipeline.batch.size设置时,请记住流动计数的值。 以不规则间隔间歇接收大型事件的管道需要足够的内存来处理这些尖峰。 相应地配置LS_HEAP_SIZE变量。
测量每个更改以确保其性能提高,而不是降低。
确保留下足够的内存可用来应付突然增加的事件大小。 例如,生成表示为大文本块的异常的应用程序。
工作程序的数量可以设置为高于CPU核心的数量,因为输出经常在I / O等待条件中花费空闲时间。
Java中的线程具有名称,可以使用jstack,top和VisualVM图形工具来确定给定线程使用的资源。
在Linux平台上,Logstash标记了所有可以描述的线程。 例如,输入显示为[base]








 京公网安备 11010802041100号
京公网安备 11010802041100号