一、Logistic回归的认知与应用场景
Logistic回归为概率型非线性回归模型,是研究二分类观察结果与一些影响因素之间关系的
一种多变量分析方法。通常的问题是,研究某些因素条件下某个结果是否发生,比如医学中根据病人的一些症状
来判断它是否患有某种病。
二、LR分类器
LR分类器,即Logistic Regression Classifier。
在分类情形下,经过学习后的LR分类器是一组权值,当测试样本的数据输入时,这组权值与测试数据按
照线性加和得到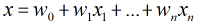 ,这里
,这里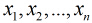 是每个样本的个特征。
是每个样本的个特征。
按照sigmoid函数的形式求出 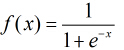 ,其中sigmoid函数的定义域为
,其中sigmoid函数的定义域为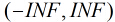 ,值域为
,值域为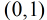 ,因此最基本的LR分类器适合对两类目标进行分类。
,因此最基本的LR分类器适合对两类目标进行分类。
所以Logistic回归最关键的问题就是研究如何求得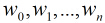 这组权值。这个问题是用极大似然估计来做的。
这组权值。这个问题是用极大似然估计来做的。
三、Logistic回归模型
考虑具有个独立变量的向量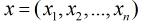 ,设条件慨率
,设条件慨率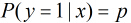 为
为
根据观测量相对于某事件发生的概率。那么Logistic回归模型可以表示为 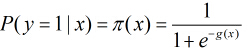
这里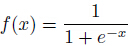 称为Logistic函数。其中
称为Logistic函数。其中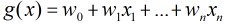 。
。
那么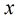 在条件
在条件 下不发生的概率为
下不发生的概率为 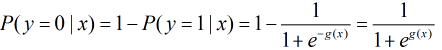
所以事件发生与不发生的概率之比为: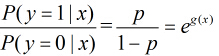
这个比值称为事件的发生比(the odds of experiencing an event),简记为odds。
————————————————
小结:
一般来说,回归不用在分类问题上,因为回归是连续型模型,而且受噪声影响比较大。
如果非要应用在分类问题上,可以使用logistic回归。
logistic回归本质上是线性回归,只是在特征到结果的映射中加入了一层函数映射,
即先把特征线性求和,然后使用函数g(z)将做为假设函数来预测。g(z)可以将连续值映射到0和1上。
————————————————
其主要参数
Cs &#xff1a; 浮点数列表或int&#xff0c;可选&#xff08;默认值&#61; 10&#xff09;Cs中的每个值描述正则化强度的倒数。如果Cs为int&#xff0c;则以1e-4和1e4之间的对数标度选择Cs值网格。与支持向量机一样&#xff0c;较小的值指定更强的正则化。fit_intercept &#xff1a; bool&#xff0c;optional&#xff08;默认&#61; True&#xff09;指定是否应将常量&#xff08;也称为偏差或截距&#xff09;添加到决策函数中。cv &#xff1a; int或交叉验证生成器&#xff0c;可选&#xff08;默认&#61;无&#xff09;使用的默认交叉验证生成器是分层K-Folds。如果提供了整数&#xff0c;则它是使用的折叠数。默认5倍dual &#xff1a; bool&#xff0c;可选&#xff08;默认&#61; False&#xff09;双重或原始配方。使用liblinear解算器&#xff0c;双重公式仅实现l2惩罚。当n_samples> n_features时&#xff0c;首选dual &#61; False。penaly :str&#xff0c;&#39;l1&#39;&#xff0c;&#39;l2&#39;或&#39;elasticnet&#39;&#xff0c;可选&#xff08;默认&#61;&#39;l2&#39;&#xff09;用于指定惩罚中使用的规范。&#39;newton-cg&#39;&#xff0c;&#39;sag&#39;和&#39;lbfgs&#39;解算器仅支持l2处罚。&#39;elasticnet&#39;仅由&#39;saga&#39;解算器支持。solver&#xff1a;逻辑回归损失函数的优化方法&#xff0c;有四种算法供选择‘newton-cg’&#xff1a;坐标轴下降法来迭代优化损失函数 ‘lbfgs’&#xff1a;, ‘liblinear’&#xff1a;牛顿法变种 ‘sag’&#xff1a;随机梯度下降其中‘newton-cg’, ‘lbfgs’, ‘sag’只适用于L2惩罚项的优化&#xff0c;liblinear两种都适用。因为L1正则化的损失函数不是连续可导的&#xff0c;而{‘newton-cg’, ‘lbfgs’,‘sag’}这三种优化算法时都需要损失函数的一阶或者二阶连续导数。而‘liblinear’并没有这个依赖。当样本数目比较大时&#xff0c;使用sag效果较好&#xff0c;因为它只使用一部分样本进行训练。a) liblinear&#xff1a;使用了开源的liblinear库实现&#xff0c;内部使用了坐标轴下降法来迭代优化损失函数。b) lbfgs&#xff1a;拟牛顿法的一种&#xff0c;利用损失函数二阶导数矩阵即海森矩阵来迭代优化损失函数。c) newton-cg&#xff1a;也是牛顿法家族的一种&#xff0c;利用损失函数二阶导数矩阵即海森矩阵来迭代优化损失函数。d) sag&#xff1a;即随机平均梯度下降&#xff0c;是梯度下降法的变种&#xff0c;和普通梯度下降法的区别是每次迭代仅仅用一部分的样本来计算梯度&#xff0c;适合于样本数据多的时候。维度<10000时&#xff0c;lbfgs法比较好&#xff0c; 维度>10000时&#xff0c; cg法比较好&#xff0c;显卡计算的时候&#xff0c;lbfgs和cg都比seg快tol &#xff1a; float&#xff0c;optional&#xff08;默认值&#61; 1e-4&#xff09;容忍停止标准。max_iter &#xff1a; int&#xff0c;optional&#xff08;默认值&#61; 100&#xff09; 优化算法的最大迭代次数。class_weight &#xff1a; dict或&#39;balanced&#39;&#xff0c;可选&#xff08;默认&#61;无&#xff09;与表单中的类相关联的权重。如果没有给出&#xff0c;所有课程都应该有一个重量。{class_label: weight}“平衡”模式使用y的值自动调整与输入数据中的类频率成反比的权重。n_samples / (n_classes * np.bincount(y))请注意&#xff0c;如果指定了sample_weight&#xff0c;这些权重将与sample_weight&#xff08;通过fit方法传递&#xff09;相乘。版本0.17中的新功能&#xff1a; class_weight &#61;&#61;&#39;balanced&#39;n_jobs &#xff1a; int或None&#xff0c;可选&#xff08;默认&#61;无&#xff09;交叉验证循环期间使用的CPU核心数。 None除非在joblib.parallel_backend上下文中&#xff0c;否则表示1 。 -1表示使用所有处理器。有关 详细信息&#xff0c;请参阅词汇表。verbose &#xff1a; int&#xff0c;optional&#xff08;默认值&#61; 0&#xff09;对于&#39;liblinear&#39;&#xff0c;&#39;sag&#39;和&#39;lbfgs&#39;求解器将详细设置为任何正数以表示详细程度。refit &#xff1a; bool&#xff0c;optional&#xff08;默认&#61; True&#xff09;如果设置为True&#xff0c;则在所有折叠中对得分进行平均&#xff0c;并且获取对应于最佳得分的coefs和C&#xff0c;并且使用这些参数进行最终的改装。否则&#xff0c;对应于折叠的最佳分数的coefs&#xff0c;intercepts和C被平均。intercept_scaling &#xff1a; float&#xff0c;optional&#xff08;默认值&#61; 1&#xff09;仅在使用求解器“liblinear”且self.fit_intercept设置为True时有用。在这种情况下&#xff0c;x变为[x&#xff0c;self.intercept_scaling]&#xff0c;即具有等于intercept_scaling的常数值的“合成”特征被附加到实例向量。截距变成了。intercept_scaling * synthetic_feature_weight注意&#xff01;合成特征权重与所有其他特征一样经受l1 / l2正则化。为了减少正则化对合成特征权重&#xff08;并因此对截距&#xff09;的影响&#xff0c;必须增加intercept_scaling。multi_class &#xff1a; str&#xff0c;{&#39;ovr&#39;&#xff0c;&#39;multinomial&#39;&#xff0c;&#39;auto&#39;}&#xff0c;optional&#xff08;default &#61;&#39;ovr&#39;如果选择的选项是&#39;ovr&#39;&#xff0c;那么二进制问题适合每个标签。对于“多项式”&#xff0c;最小化的损失是整个概率分布中的多项式损失拟合&#xff0c;即使数据是二进制的。当solver &#61;&#39;liblinear&#39;时&#xff0c;&#39;multinomial&#39;不可用。如果数据是二进制的&#xff0c;或者如果solver &#61;&#39;liblinear&#39;&#xff0c;&#39;auto&#39;选择&#39;ovr&#39;&#xff0c;否则选择&#39;multinomial&#39;。版本0.18中的新功能&#xff1a;用于“多项式”情况的随机平均梯度下降求解器。版本0.20更改&#xff1a;默认值将在0.22中从“ovr”更改为“auto”。random_state &#xff1a; int&#xff0c;RandomState实例或None&#xff0c;可选&#xff08;默认&#61;无&#xff09;如果是int&#xff0c;则random_state是随机数生成器使用的种子; 如果是RandomState实例&#xff0c;则random_state是随机数生成器; 如果为None&#xff0c;则随机数生成器是由其使用的RandomState实例np.random。l1_ratios &#xff1a; float或None列表&#xff0c;可选&#xff08;默认&#61;无&#xff09;弹性网混合参数列表&#xff0c;带。仅用于。值0等于使用&#xff0c;而1等于使用 。因为&#xff0c;惩罚是L1和L2的组合。0 <&#61; l1_ratio <&#61; 1penalty&#61;&#39;elasticnet&#39;penalty&#61;&#39;l2&#39;penalty&#61;&#39;l1&#39;0 < l1_ratio <1
————————————————
版权声明&#xff1a;本文为CSDN博主「NongfuSpring-wu」的原创文章&#xff0c;遵循 CC 4.0 BY-SA 版权协议&#xff0c;转载请附上原文出处链接及本声明。
原文链接&#xff1a;https://blog.csdn.net/weixin_41690708/article/details/95171333
下面是一些重要参数&#xff1a;







除了上面的六个参数&#xff0c;还有一个参数&#xff0c;Cs&#xff0c;也就是正则化系数&#xff0c;相当于 LogisticRegression里的参数C。
通常使用np.logspace来生成几个正则化系数&#xff0c;供函数挨个尝试&#xff0c;选择一个最好的&#xff0c;这也就是交叉验证的过程。
然后参数cv控制几折交叉验证。
Cs&#61;np.logspace(-2, 2, 20)
顺便说一下吧&#xff0c;如果是LogisticRegression
sklearn.linear_model.LogisticRegression
LogisticRegression(penalty&#61;‘l2’, dual&#61;False,
tol&#61;0.0001, C&#61;1.0, fit_intercept&#61;True,
intercept_scaling&#61;1, class_weight&#61;None,
random_state&#61;None, solver&#61;‘warn’, max_iter&#61;100,
multi_class&#61;‘warn’, verbose&#61;0,
warm_start&#61;False, n_jobs&#61;None)
penalty&#xff1a;惩罚项&#xff0c;可为’l1’ or ‘l2’。‘netton-cg’, ‘sag’, ‘lbfgs’只支持’l2’。
‘l1’正则化的损失函数不是连续可导的&#xff0c;而’netton-cg’, ‘sag’, &#39;lbfgs’这三种算法需要损失函数的一阶或二阶连续可导。
调参时如果主要是为了解决过拟合&#xff0c;选择’l2’正则化就够了。若选择’l2’正则化还是过拟合&#xff0c;可考虑’l1’正则化。
若模型特征非常多&#xff0c;希望一些不重要的特征系数归零&#xff0c;从而让模型系数化的话&#xff0c;可使用’l1’正则化。
dual&#xff1a;选择目标函数为原始形式还是对偶形式。
将原始函数等价转化为一个新函数&#xff0c;该新函数称为对偶函数。对偶函数比原始函数更易于优化。
tol&#xff1a;优化算法停止的条件。当迭代前后的函数差值小于等于tol时就停止。
C&#xff1a;正则化系数。其越小&#xff0c;正则化越强。
fit_intercept&#xff1a;选择逻辑回归模型中是否会有常数项b
intercept_scaling&#xff1a;
class_weight&#xff1a;用于标示分类模型中各种类型的权重&#xff0c;{class_label: weight} or ‘balanced’。
‘balanced’&#xff1a;类库根据训练样本量来计算权重。某种类型的样本量越多&#xff0c;则权重越低。
若误分类代价很高&#xff0c;比如对合法用户和非法用户进行分类&#xff0c;可适当提高非法用户的权重。
样本高度失衡的。如合法用户9995条&#xff0c;非法用户5条&#xff0c;可选择’balanced’&#xff0c;让类库自动提高非法用户样本的权重。
random_state&#xff1a;随机数种子。
solver&#xff1a;逻辑回归损失函数的优化方法。
‘liblinear’&#xff1a;使用坐标轴下降法来迭代优化损失函数。
‘lbfgs’&#xff1a;拟牛顿法的一种。利用损失函数二阶导数矩阵即海森矩阵来迭代优化损失函数。
‘newton-cg’&#xff1a;牛顿法的一种。同上。
‘sag’&#xff1a;随机平均梯度下降。每次迭代仅仅用一部分的样本来计算梯度&#xff0c;适合于样本数据多的时候。
多元逻辑回归有OvR(one-vs-rest)和MvM(many-vs-many)两种&#xff0c;而MvM一般比OvR分类相对准确一些。但是&#xff0c;&#39;liblinear’只支持OvR。
max_iter&#xff1a;优化算法的迭代次数。
multi_class&#xff1a;‘ovr’ or ‘multinomial’。&#39;multinomial’即为MvM。
若是二元逻辑回归&#xff0c;二者区别不大。
对于MvM&#xff0c;若模型有T类&#xff0c;每次在所有的T类样本里面选择两类样本出来&#xff0c;把所有输出为该两类的样本放在一起&#xff0c;进行二元回归&#xff0c;得到模型参数&#xff0c;一共需要T(T-1)/2次分类。
verbose&#xff1a;控制是否print训练过程。
warm_start&#xff1a;
n_jobs&#xff1a;用cpu的几个核来跑程序。
有了sklearn包之后&#xff0c;很多这种机器学习的算法的代码都比较简单了&#xff0c;下面是logisticsRegression的代码&#xff0c;LogisticsRegressionCV的代码同理可以写出来。
from sklearn import linear_model
logistic &#61; linear_model.LogisticRegression()
#如果用正则化&#xff0c;可以添加参数penalty&#xff0c;可以是l1正则化&#xff08;可以更有效的抵抗共线性&#xff09;&#xff0c;也可以是l2正则化&#xff0c;如果是类别不均衡的数据集&#xff0c;可以添加class_weight参数&#xff0c;这个可以自己设置&#xff0c;也可以让模型自己计算
logistic &#61; linear_model.LogisticRegression( penalty&#61;&#39;l1&#39;, class_weight&#61;&#39;balanced&#39;)
logistic.fit(X_train,y_train)
y_pred &#61; logistic.predict( X_test)
#如果只想预测概率大小&#xff0c;可以用下面这个函数
y_pred &#61; logistic.predict_proba(X_test)




 京公网安备 11010802041100号
京公网安备 11010802041100号