今天搜索spark mongo的资料,意外发现了MongoDB的一些知识,这些都是之前没有接触过的,所以专门记录下。
一、BSON文档
1、BSON文档尺寸:一个document文档最大尺寸为16M;大于16M的文档需要存储在GridFS中。
2、文档内嵌深度:BSON文档的结构(tree)深度最大为100。
二、Namespaces
1、collection命名空间:.,最大长度为120字节。这也限定了database和collection的名字不能太长。
2、命名空间的个数:对于MMAPV1引擎,个数最大为大约为24000个,每个collection以及index都是一个namespace;对于wiredTiger引擎则没有这个限制。
3、namespace文件的大小:对于MMAPV1引擎而言,默认大小为16M,可以通过在配置文件中修改。wiredTiger不受此限制。
三、indexes
1、index key:每条索引的key不得超过1024个字节,如果index key的长度超过此值,将会导致write操作失败。
2、每个collection中索引的个数不得超过64个。
3、索引名称:我们可以为index设定名称,最终全名为..$,最长不得超过128个字节。默认情况下为filed名称与index类型的组合,我们可以在创建索引时显式的指定index名字,参见createIndex()方法。
4、组合索引最多能包含31个field。
四、Data
1、Capped Collection:如果你在创建“Capped”类型的collection时指定了文档的最大个数,那么此个数不能超过2的32次方,如果没有指定最大个数,则没有限制。
2、Database Size:MMAPV1引擎而言,每个database不得持有超过16000个数据文件,即单个database的总数据量最大为32TB,可以通过设置“smallFiles”来限定到8TB。
3、Data Size:对于MMAVPV1引擎而言,单个mongod不能管理超过最大虚拟内存地址空间的数据集,比如linux(64位)下每个mongod实例最多可以维护64T数据。wiredTiger引擎没有此限制。
4、每个Database中collection个数:对于MMAPV1引擎而然,每个database所能持有的collections个数取决于namespace文件大小(用来保存namespace)以及每个collection中indexes的个数,最终总尺寸不超过namespace文件的大小(16M)。wiredTiger引擎不受到此限制。
五、Replica Sets
1、每个replica set中最多支持50个members。
2、replica set中最多可以有7个voting members。(投票者)
3、如果没有显式的指定oplog的尺寸,其最大不会超过50G。
六、Sharded Clusters
1、group聚合函数,在sharding模式下不可用。请使用mapreduce或者aggregate方法。
2、Coverd Queries:即查询条件中的Fields必须是index的一部分,且返回结果只包含index中的fields;对于sharding集群,如果query中不包含shard key,索引则无法进行覆盖。虽然_id不是“shard key”,但是如果查询条件中只包含_id,且返回的结果中也只需要_id字段值,则可以使用覆盖查询,不过这个查询似乎并没有什么意义(除非是检测此_id的document是否存在)。
3、对于已经存有数据的collections开启sharding(原来非sharding),则其最大数据不得超过256G。当collection被sharding之后,那么它可以存储任意多的数据。
4、对于sharded collection,update、remove对单条数据操作(操作选项为multi:false或者justOne),必须指定shard key或者_id字段;否则将会抛出error。
5、唯一索引:shards之间不支持唯一索引,除非这个“shard key”是唯一索引的最左前缀。比如collection的shard key为{"zipcode":1,"name": 1},如果你想对collection创建唯一索引,那么唯一索引必须将zipcode和name作为索引的最左前缀,比如:collection.createIndex({"zipcode":1,"name":1,"company":1},{unique:true})。
6、在chunk迁移时允许的最大文档个数:如果一个chunk中documents的个数超过250000(默认chunk大小为64M)时,或者document个数大于 1.3 *(chunk最大尺寸(有配置参数决定)/ document平均尺寸),此chunk将无法被“move”(无论是balancer还是人工干预),必须等待split之后才能被move。
七、shard key
shard key的长度不得超过512个字节。
“shard key索引”可以为基于shard key的正序索引,或者以shard key开头的组合索引。shard key索引不能是multikey索引(基于数组的索引)、text索引或者geo索引。
Shard key是不可变的,无论何时都不能修改document中的shard key值。如果需要变更shard key,则需要手动清洗数据,即全量dump原始数据,然后修改并保存在新的collection中。
单调递增(递减)的shard key会限制insert的吞吐量;如果_id是shard key,需要知道_id是ObjectId()生成,它也是自增值。对于单调递增的shard key,collection上的所有insert操作都会在一个shard节点上进行,那么此shard将会承载cluster的全部insert操作,因为单个shard节点的资源有限,因此整个cluster的insert量会因此受限。如果cluster主要是read、update操作,将不会有这方面的限制。为了避免这个问题,可以考虑使用“hashed shard key”或者选择一个非单调递增key作为shard key。(rang shard key 和hashed shard key各有优缺点,需要根据query的情况而定)。
八、Operations
如果mongodb不能使用索引排序来获取documents,那么参与排序的documents尺寸需要小于32M。
Aggregation Pileline操作。Pipeline stages限制在100M内存,如果stage超过此限制将会发生错误,为了能处理较大的数据集,请开启“allowDiskUse”选项,即允许pipeline stages将额外的数据写入临时文件。
九、命名规则
database的命名区分大小写。
database名称中不要包含&#xff1a;/ \.&#39;&#39;$*<>:|?
database名称长度不能超过64个字符。
collection名称可以以“_”或者字母字符开头&#xff0c;但是不能包含"$"符号&#xff0c;不能为空字符或者null&#xff0c;不能以“system.”开头&#xff0c;因为这是系统保留字。
document字段名不能包含“.”或者null&#xff0c;且不能以“$”开头&#xff0c;因为$是一个“引用符号”。
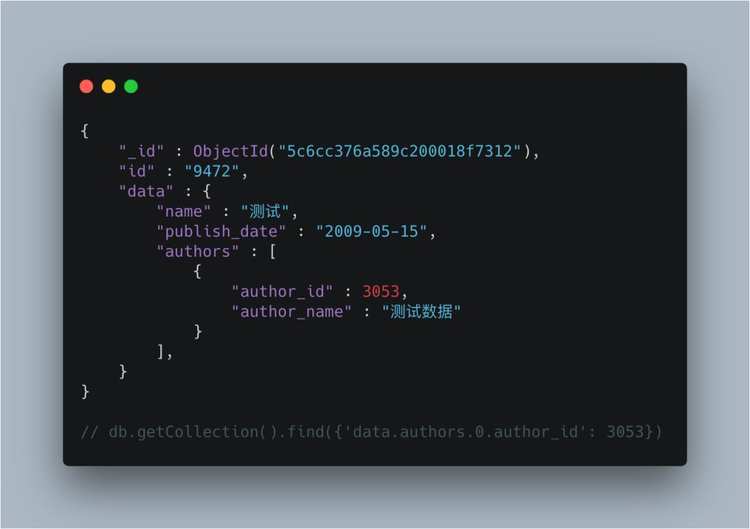
最后记录下json嵌套中含有列表的查询方法&#xff0c;样例数据&#xff1a;
{
"_id" : ObjectId("5c6cc376a589c200018f7312"),
"id" : "9472",
"data" : {
"name" : "测试",
"publish_date" : "2009-05-15",
"authors" : [
{
"author_id" : 3053,
"author_name" : "测试数据"
}
],
}
}
我要查询authors中的author_id&#xff0c;query可以这样写&#xff1a;
db.getCollection().find({&#39;data.authors.0.author_id&#39;: 3053})
用0来代表第一个索引&#xff0c;点代表嵌套结构。但是spark mongo中是不能这样导入的&#xff0c;需要使用别的方法。







 京公网安备 11010802041100号
京公网安备 11010802041100号