作者:簕竹仔_591 | 来源:互联网 | 2023-06-14 16:54
前言:
- ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
- 我们建立一个网站或应用程序,并要添加搜索功能,但是想要完成搜索工作的创建是非常困难的。我们希望搜索解决方案要运行速度快,我们希望能有一个零配置和一个完全免费的搜索模式,我们希望能够简单地使用JSON通过HTTP来索引数据,我们希望我们的搜索服务器始终可用,我们希望能够从一台开始并扩展到数百台,我们要实时搜索,我们要简单的多租户,我们希望建立一个云的解决方案。因此我们利用Elasticsearch来解决所有这些问题以及可能出现的更多其它问题。
1.准备
-
在微服务集成es之前先安装Elasticsearch 以及可视化工具Kibana;注意安装的版本一定要一致,不能版本不相同。
-
推荐使用docker安装,如何使用docker以及docker的容器安装请移步其他帖子。
安装移步es安装以及配置.
-
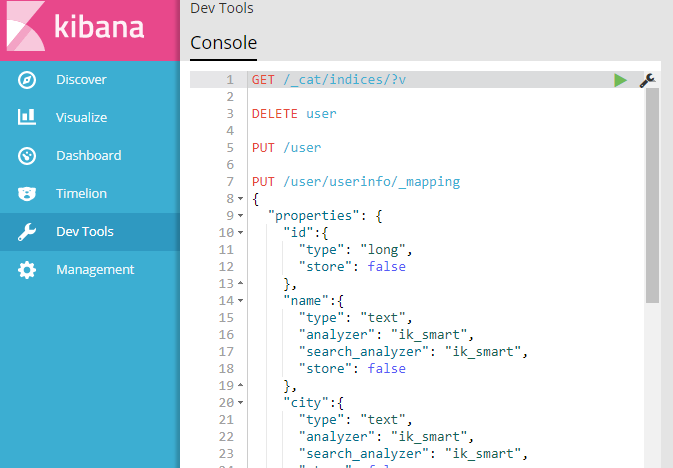
安装Kibana之后创建索引及类型:
-
这是相关索引指令:
GET /_cat/indices/?v #查询所有索引
DELETE user #删除索引
PUT /user #添加索引
PUT /user/userinfo/_mapping #增加索引 类型的映射关系 (相当于数据库建表)
{
“properties”: {
“id”:{
“type”: “long”,
“store”: false
},
“name”:{
“type”: “text”,
“analyzer”: “ik_smart”,
“search_analyzer”: “ik_smart”,
“store”: false
},
“city”:{
“type”: “text”,
“analyzer”: “ik_smart”,
“search_analyzer”: “ik_smart”,
“store”: false
},
“age”:{
“type”: “long”,
“store”: false
},
“remark”:{
“type”: “text”,
“analyzer”: “ik_smart”,
“search_analyzer”: “ik_smart”,
“store”: false
}
}
}
2.引入依赖
org.springframework.bootspring-boot-starter-data-elasticsearch
3.配置文件配置
spring:application:name: testdata:elasticsearch:cluster-name: my-application #elasticsearch.yml配置的节点名cluster-nodes: 10.10.0.233:9300 #es安装的ip及端口
4.准备实体类对应es索引类型的映射
package com.bwwl.hive.model;import lombok.Data;
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
import org.springframework.data.elasticsearch.annotations.FieldType;import java.io.Serializable;/***@author liuxingying*@description*@date 2020/9/29*/
@Data
@Document(indexName = "user",type = "userinfo") //对应索引库和类型
public class Userinfo implements Serializable {@Idprivate long id;@Field(type = FieldType.Text,analyzer = "ik_smart",searchAnalyzer = "ik_smart")private String name;@Field(type = FieldType.Text,analyzer = "ik_smart",searchAnalyzer = "ik_smart")private String city;@Field(type = FieldType.Long)private Integer age;@Field(type = FieldType.Text,analyzer = "ik_smart",searchAnalyzer = "ik_smart")private String remark;
}
5.准备dao
package com.bwwl.hive.dao;import com.bwwl.hive.model.Userinfo;
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
import org.springframework.stereotype.Repository;@Repository
//Userinfo对应实体 Long对应主键
public interface ElasticsearchDao extends ElasticsearchRepository {
}
6.将数据库数据导入到es
package com.bwwl.hive.service.impl;import com.bwwl.hive.dao.ElasticsearchDao;
import com.bwwl.hive.model.Userinfo;
import com.bwwl.hive.service.ElasticsearchService;
import com.bwwl.hive.service.GetData;
import org.elasticsearch.index.query.QueryBuilders;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.elasticsearch.core.ElasticsearchTemplate;
import org.springframework.data.elasticsearch.core.aggregation.AggregatedPage;
import org.springframework.data.elasticsearch.core.query.NativeSearchQueryBuilder;
import org.springframework.stereotype.Service;import java.util.List;/***@author liuxingying*@description*@date 2020/9/29*/
@Service
public class ElasticsearchServiceImpl implements ElasticsearchService {@Autowiredprivate GetData getData;@Autowiredprivate ElasticsearchDao dao;@Autowiredprivate ElasticsearchTemplate elasticsearchTemplate;/** @description 导入数据* @params []* @return void* @author lxy* @date 2020/9/29 11:06**/@Overridepublic void importData(){//从mysql查出所有数据 一般来说可以先查出来是一个对象javabean,然后转换成索引对象Userinfo就行,我这里是直接用的userinfo对象List user = getData.getAll();//导入到esdao.saveAll(user);}}
7.查询条件的构建与检索实现
package com.bwwl.hive.service.impl;import com.bwwl.hive.dao.ElasticsearchDao;
import com.bwwl.hive.model.Userinfo;
import com.bwwl.hive.service.ElasticsearchService;
import com.bwwl.hive.service.GetData;
import org.elasticsearch.index.query.QueryBuilders;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.elasticsearch.core.ElasticsearchTemplate;
import org.springframework.data.elasticsearch.core.aggregation.AggregatedPage;
import org.springframework.data.elasticsearch.core.query.NativeSearchQueryBuilder;
import org.springframework.stereotype.Service;import java.util.List;/***@author liuxingying*@description*@date 2020/9/29*/
@Service
public class ElasticsearchServiceImpl implements ElasticsearchService {@Autowiredprivate GetData getData;@Autowiredprivate ElasticsearchDao dao;@Autowiredprivate ElasticsearchTemplate elasticsearchTemplate;/** @description 导入数据* @params []* @return void* @author lxy* @date 2020/9/29 11:06**/@Overridepublic void importData(){List user = getData.getAll();dao.saveAll(user);}/** @description es搜索* @params [parm]* @return java.util.List* @author lxy* @date 2020/9/29 11:32**/@Overridepublic List search(String parm) {//TODO 构建查询对象用于封装各种查询条件 NativeSearchQueryBuilderNativeSearchQueryBuilder nativeSearchQueryBuilder = new NativeSearchQueryBuilder();nativeSearchQueryBuilder.withQuery(QueryBuilders.queryStringQuery(parm).field("name"));//执行查询esAggregatedPage page = elasticsearchTemplate.queryForPage(nativeSearchQueryBuilder.build(), Userinfo.class);//查询结果集合List list = page.getContent();//查询结果总条数long totalElements = page.getTotalElements();//查询结果总页数long totalPages = page.getTotalPages();return list;}
}
- 最后再controller层调用接口就行,一个简单的es检索就搭起来了,我这里只实现了简单的查询检索,还有很多比如排序、分页、范围限制、高亮和聚合查询等等都没实现,es在搜索的方法上有很多api实现,可以去官网看看怎么使用,欢迎探讨。










 京公网安备 11010802041100号
京公网安备 11010802041100号