Java虚拟机通过系列类加载器加载Class文件,然后读取其中的字节码指令进行工作的。而Class文件则是通过Java编译器编译Java源代码得到的,如下图:

理解编译器是如何与Java虚拟机协同工作的,对编译器开发人员来说很有好处,同样也有助于理解Java虚拟机本身。
下面主要介绍的是Java虚拟机规定的编译规则:
常量、局部变量的使用和控制结构
Java虚拟机是基于栈架构设计的,它的大多数操作是从当前栈帧的操作数栈取出1个或多个操作数,或将结果压入操作数栈中。每调用一个方法,都会创建一个新的栈帧,并创建对应方法所需的操作数栈和局部变量表
前面已经谈到栈和栈帧的概念,在栈帧中存在着操作数栈和局部变量表,两者都被组织为以一个字长为单位、从0开始计数的数组,不同的是前者的访问是通过入栈和出栈,而后者是通过索引完成的。注意在局部变量表中long和double类型占据2个位置,访问时通过第一个位置的索引即可。
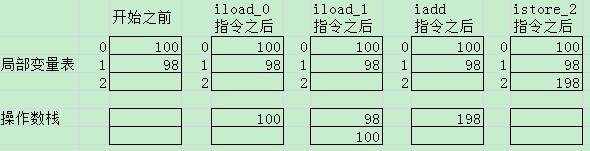
下面来看一个小例子:
int a = 100;
int b = 98;
int c = a + b;
我们简单用图表示下上面代码编译后产生的字节码指令在操作数栈和局部变量表中的执行过程:
接着引用书中的例子,先看Java代码:
void spin()
{
int i; for (i &#61; 0; i <100; i&#43;&#43;)
{
; //Loop body is empty
}
}
很简单的一个空循环&#xff0c;再来看一下经过编译后的字节码指令&#xff1a;
Method void spin()
0 iconst_0 //从常量池中取出常量0放入操作数栈1 istore_1 //把0放入局部变量表中第一个位置(i&#61;0)2 goto 8 //第一次不执行i&#43;&#43;操作5 iinc 1 1 //(i&#43;&#43;)8 iload_1 //从局部变量表中取出第一个局部变量放入操作数栈(i)9 bipush 100 //取出常量 100 放入操作数栈11 if_icmplt 5 //如果满足i<100&#xff0c;执行第五条指令14 return //返回
0和100两个常量分别使用了两条不同的指令压入操作数栈。对于0采用了iconst_0 指令&#xff0c;它属于iconst_指令族。而对于100采用bipush指令。这样的原因是因为Java虚拟机内部规定了入栈的int类型的i是-1、0、1、2、3、4、5时使用iconst_指令&#xff0c;其他的值使用bipush。当然你也可以使用在[-1, 5]时使用bipush指令&#xff0c;但是这样会造成解析的字节码多出一个字节&#xff0c;每次循环时Java虚拟机也会额外的耗费时间去获取和解析这个操作数。
iconst_0这样的形式称作操作码隐式包含。至于为什么不能所有的数值都采用这种格式&#xff0c;我觉得是受限于Java虚拟机操作码的长度。
如果在spin()例子的中循环的计数器使用了非int类型&#xff0c;那么编译代码也要有调整。譬如在spin例子中使用double型取代int&#xff0c;则&#xff1a;
void dspin()
{
double i;
for (i &#61; 0.0; i <100.0; i&#43;&#43;)
{
; //Loop body is empty }
}
相应的自编码也会变成double类型的&#xff1a;
Method void dspin()
0 dconst_0 //从常量池中取出0放入操作数栈1 dstore_1 //从操作数栈取出0放入局部变量表位置1和22 goto 9 //执行95 dload_1 //向操作数栈中放入局部变量1和26 dconst_1 //取出常量1.07 dadd //相加&#xff0c;与int类型不同&#xff0c;double类型没有自增的指令8 dstore_1 //结果放入局部变量表1和29 dload_1 //将局部变量1和2压入操作数栈10 ldc2_w #4 //出去double常量10013 dcmpg //和100进行比较&#xff0c;这里同样没有int类型的直接判断14 iflt 5 //如果小于转向517 return //返回
前文提到过double和long类型的值占用两个局部变量的空间&#xff0c;上例中可以看出来&#xff0c;double在局部变量表中占据了2个位置&#xff0c;访问时使用索引小的访问&#xff0c;这对局部变量不能够分开进行操作。
Java虚拟机中&#xff0c;操作码都为一个字节&#xff0c;这限制了操作码的数量最多是265条。其中对于int类型的操作大部分都可以直接进行&#xff0c;这一部分考虑到操作数栈和局部变量表的实现效率&#xff0c;另一部分也是由于int类型操作的频繁。
在Java虚拟机指令集中&#xff0c;没有对byte&#xff0c;char和short类型变量的store、load和add等指令。例如&#xff0c;用short类型来实现上面spin中的循环时&#xff1a;
void sspin()
{
short i;
for (i &#61; 0; i <100; i&#43;&#43;)
{
; //Loop body is empty }
}
Java虚拟机编译时要将其他可安全转化为int类型的数据转换为int类型进行操作。在将short类型值转换为int类型值时&#xff0c;可以保证short类型值操作后结果一定在int类型的精度范围之内&#xff0c;因此sspin()的编译后代码如下&#xff1a;
Method void sspin()
0 iconst_0
1 istore_1
2 goto 10
5 iload_1 //把short当做int来使用6 iconst_1
7 iadd
8 i2s //int转化为short9 istore_1
10 iload_1
11 bipush 100
13 if_icmplt 5
16 return
在Java虚拟机中&#xff0c;缺乏对byte、short和char类型的相对支持&#xff0c;但是带来的问题并不大。在编译过程中&#xff0c;byte和short类型带符号扩展为int类型&#xff0c;而char零位扩展为int类型。而long和浮点类型&#xff0c;Java虚拟机提供了和int相当的支持&#xff0c;但是没有条件转移指令。
算术运算
Java虚拟机中的算术运算是基于操作数栈来进行的&#xff0c;算术运算中用到的操作数都是从操作数栈中弹出&#xff0c;运算结果再压入操作数栈。在内部运算中&#xff0c;运算的中间结果可以当做操作数使用。
唯一例外的是iinc指令&#xff0c;它直接操作局部变量进行自增。
访问运行时常量池
很多数值常量&#xff0c;以及对象、字段和方法&#xff0c;都是通过当前类的运行时常量池进行访问。类型为int、long、float和double的数据&#xff0c;以及表示String实例的引用类型数据的访问将由ldc、ldc_w和ldc2_w指令实现。ldc和ldc_w指令用于访问运行时常量池中的对象&#xff0c;包括String实例&#xff0c;但不包括double和long类型的值。当使用的运行时常量池的项的数目过多时(多于256个&#xff0c;1个字节能表示的范围)&#xff0c;需要使用ldc_w指令取代ldc指令来访问常量池。ldc2_w 指令用于访问类型为double和long的运行时常量池项&#xff0c;这条指令没有非宽索引的版本(即没有ldc2指令)。
对于整型常量&#xff0c;包括byte、char、short和int&#xff0c;将编译到代码之中&#xff0c;使用bipush、sipush和iconst_指令进行访问。某些浮点常量也可以编译进代码&#xff0c;使用fconst_和dconst_指令进行访问。
通过以上描述&#xff0c;编译的规则已经基本解释清楚了。下面这个例子将这些规则汇总了起来&#xff1a;
void useManyNumeric()
{
int i &#61; 100;
int j &#61; 1000000;
long l1 &#61; 1;
long l2 &#61; 0xffffffff;
double d &#61; 2.2;
}
编译后的字节码如下&#xff1a;
Method void useManyNumeric()
0 bipush 100 //把100压入操作数栈(前面说过[-1,0,1,2,3,4,5]时使用i_const指令)2 istore_1
3 ldc #1 //把10000到操作数栈(比较大的int数值&#xff0c;使用ldc和bipush的界限我也不太清楚。望达人指教)5 istore_2
6 lconst_1 //把long值1压入操作数栈7 lstore_3
8 ldc2_w #6 //把long值0xffffffff压入操作数栈11 lstore 5
13 ldc2_w #8 //16 dstore 7
接受参数
如果传递了n个参数给某个实例方法&#xff0c;则当前栈帧会按照约定的顺序接收这些参数&#xff0c;将它们保存为方法的第1个至第n个局部变量之中。
int addTwo(int i, int j)
{
return i &#43; j;
}
编译后的字节码如下&#xff1a;
Method int addTwo(int,int)
0 iload_1 //将第一个局部变量压入操作站(i)1 iload_2 //将第二个局部变量压入操作站(j)2 iadd //i和j出栈相加再入栈3 ireturn //返回int型结果
按照约定&#xff0c;实例方法需要传递一个自身实例的引用作为第0个局部变量。
类方法不需要传递自身示例作为第0个局部变量&#xff1a;
static int addTwoStatic(int i, int j)
{
return i &#43; j;
}
编译后的字节码如下&#xff1a;
Method int addTwoStatic(int,int)
0 iload_0
1 iload_1
2 iadd
3 ireturn
可以看出来参数保存在局部变量表时&#xff0c;索引从0开始。
方法调用
对于普通实例方法的调用是通过invokevirtual指令实现。每条invokevirtual指令都会带有一个表示索引的参数&#xff0c;运行时常量池在该索引处的项为某个方法的符号引用&#xff0c;这个符号引用可以提供方法所在对象的类型的内部二进制名称、方法名称和方法描述符。来看一个例子&#xff1a;
int add12and13()
{
return addTwo(12, 13);
}
编译后字节码如下&#xff1a;
Method int add12and13()
0 aload_0 //将自身引用压入操作栈1 bipush 12 //将参数12压入操作栈3 bipush 13 //将参数13压入操作站5 invokevirtual #4 //调用方法8 ireturn //返回结果到操作栈顶
方法调用的过程是这样的&#xff1a;前面说过会将当前实例的自身引用放入局部变量表的第0位&#xff0c;方法调用的第一步是将当前实例的自身引用压入操作栈&#xff0c;随后将参数12和13压入操作栈&#xff0c;调用方法addTwo&#xff0c;这是Java虚拟机会创建一个新的栈帧&#xff0c;新的栈帧将作为当前栈帧&#xff0c;传入的实例引用(this)和参数12、13将作为当前栈帧的第0、1、2个局部变量。当addTwo方法执行完返回时&#xff0c;add12and13方法的栈帧重新作为当前栈帧&#xff0c;返回结果压入add12and13方法的操作数栈的栈顶&#xff0c;便于ireturn指令马上能够得到结果并返回。
invokevirtual指令操作数(在上面示例中的运行时常量池索引#4)不是Class实例中方法指令的偏移量。编译器并不需要了解Class实例的内部布局&#xff0c;它只需要产生方法的符号引用并保存于运行时常量池即可&#xff0c;这些运行时常量池项将会在执行时转换成调用方法的实际地址。Java虚拟机指令集中其他指令在访问Class实例时也采用相同的方式。
如果上个例子中&#xff0c;调用的实例方法addTwo()变成类(static)方法的话&#xff0c;编译代码会有略微变化&#xff0c;如下&#xff1a;
int add12and13()
{
return addTwoStatic(12, 13);
}
编译代码中使用了另一个Java虚拟机调用指令invokestatic&#xff1a;
Method int add12and13()
0 bipush 12
2 bipush 13
4 invokestatic #3 //调用方法7 ireturn
类方法和实例方法的调用的编译代码很类似&#xff0c;两者的区别仅仅是实例方法需要调用者传递this参数而类方法则不用。
invokespecial指令用于调用实例初始化方法&#xff0c;它也可以用来调用父类方法和私有方法。譬如下面例子中的Near和Far两个类&#xff1a;
class Near {
int it;
public int getItNear()
{
return getIt();
}
private int getIt()
{
return it;
}
}
class Far extends Near
{
int getItFar()
{
return super.getItNear();
}
}
调用类Near的方法getItNear()(调用私有方法)被编译为&#xff1a;
Method int getItNear()
0 aload_0
1 invokespecial #5 //调用私有方法getIt()4 ireturn
调用类Far的方法getItFar ()(调用父类方法)被编译为&#xff1a;
Method int getItFar()
0 aload_0
1 invokespecial #4 //Method Near.getItNear()I4 ireturn
invokespecial指令和invokevirtual指令一样需要将自身示例引用this作为第一个参数&#xff0c;保存在第0个局部变量。
如果编译器要调用某个方法&#xff0c;必须先产生这个方法描述符&#xff0c;描述符中包含了方法实际参数和返回类型。编译器在方法调用时不会处理参数的类型转换问题&#xff0c;只是简单地将参数的压入操作数栈&#xff0c;且不改变其类型。通常&#xff0c;编译器会先把一个方法所在的对象的引用压入操作数栈&#xff0c;方法参数则按顺序跟随这个对象之后入栈。编译器在生成invokevirtual指令时&#xff0c;也会生成这条指令所引用的描述符&#xff0c;这个描述符提供了方法参数和返回值的信息。
使用类实例
Java虚拟机类实例通过Java虚拟机new指令创建。在Java虚拟机层面&#xff0c;构造函数将会以一个编译器提供的以命名的方法出现。这个特殊的名字的方法也被称作实例初始化方法。一个类可以有多个构造函数&#xff0c;对应地也就会有多个实例初始化方法。一旦类实例被创建&#xff0c;那么这个实例包含的所有实例变量&#xff0c;除了在本身定义的以及父类中所定义的&#xff0c;都将被赋予默认初始值&#xff0c;接着&#xff0c;新对象的实例初始化方法将会被调用。
Object create()
{
return new Object();
}
编译后字节码如下&#xff1a;
Method java.lang.Object create()
0 new #1 //new指令3 dup
4 invokespecial #4 //调用实例初始化方法7 areturn
在参数传递和方法返回时&#xff0c;类实例(作为reference类型)与普通的数值类型没有太大区别&#xff0c;reference类型也有它自己类型专有的Java虚拟机指令&#xff0c;譬如&#xff1a;
int i; {
MyObj o &#61; new MyObj();
return silly(o);
}
MyObj silly(MyObj o)
{
if (o !&#61; null)
{
return o;
}
else
{
return o;
}
}
编译后字节码如下&#xff1a;
Method MyObj example()
0 new #2 //Class MyObj3 dup
4 invokespecial #5 //Method MyObj.()V7 astore_1
8 aload_0
9 aload_1
10 invokevirtual #4 //Method Example.silly(LMyObj;)LMyObj;13 areturn
Method MyObj silly(MyObj)
0 aload_1
1 ifnull 6
4 aload_1
5 areturn
6 aload_1
7 areturn
类实例的字段(实例变量)将使用getfield和putfield指令进行访问&#xff0c;假设i是一个int型的实例变量&#xff0c;且方法getIt()和setIt()的定义如下&#xff1a;
void setIt(int value)
{
i &#61; value;
}
int getIt()
{
return i;
}
编译后字节码如下&#xff1a;
Method void setIt(int)
0 aload_0
1 iload_1
2 putfield #4 //Field Example.i I5 return
Method int getIt()
0 aload_0
1 getfield #4 //Field Example.i I4 ireturn
无论方法调用指令的操作数&#xff0c;还是putfield、getfield指令的操作数(上面例子中运行时常量池索引#4)都并非类实例中的地址偏移量。编译器会为这些字段生成符号引用&#xff0c;保存在运行时常量池之中。这些运行时常量池项会在解析阶段转换为引用对象中真实的字段位置。
数组
在Java虚拟机中&#xff0c;数组也使用对象来表示。数组由专门的指令集来创建和操作。newarray指令用于创建元素类型为数值类型的数组。譬如&#xff1a;
void createBuffer()
{
int buffer[];
int bufsz &#61; 100;
int value &#61; 12;
buffer &#61; new int[bufsz];
buffer[10] &#61; value;
value &#61; buffer[11];
}
编译后字节码如下&#xff1a;
Method void createBuffer()
0 bipush 100 //常量100压入操作数栈2 istore_2 //存储到局部变量池第2个位置3 bipush 12 //常量12压入操作数栈5 istore_3 //存储到局部变量池第3个位置
6 iload_2 //bufsz压入操作数栈7 newarray int //new一个bufsz长度的int数组9 astore_1 //存储到第一个局部变量位置10 aload_1 //把buff压入操作数栈11 bipush 10 //常量10压入操作数栈13 iload_3 //把第三个局部变量12压入操作数栈
14 iastore//把值赋给buff[10]15 aload_1 //把buff压入操作数栈
16 bipush 11//常量11压入操作数栈18 iaload //buffer[11]的值压入操作数栈19 istore_3 //放入第三个局部变量的位置
20 return
anewarray指令用于创建元素为引用类型的一维数组。譬如&#xff1a;
void createThreadArray()
{
Thread threads[];
int count &#61; 10;
threads &#61; new Thread[count];
threads[0] &#61; new Thread();
}
编译后字节码如下&#xff1a;
Method void createThreadArray()
0 bipush 10 //常量10压入操作数栈2 istore_2 //给第二个局部变量count赋值103 iload_2 //count压入操作数栈4 anewarray class #1 //new一个常量池中索引为1的符号类型的数组7 astore_1 //新数组存储到局部变量池第一个位置
8 aload_1//数组threads压入操作数栈9 iconst_0 //常量0压入操作数栈10 new #1 //new一个Thread的实例13 dup //在操作数栈中拷贝14 invokespecial #5 //调用Thread类的实例初始化方法17 aastore //存储到数组threads的第0个位置18 return
anewarray指令也可以用于创建多维数组的第一维。不过我们也可以选择采用multianewarray指令一次性创建多维数组。譬如三维数组&#xff1a;
int[][][]
create3DArray()
{
int grid[][][];
grid &#61; new int[10][5][];
return grid;
}
编译后字节码如下&#xff1a;
Method int create3DArray()[][][]
0 bipush 10 //常量10压入操作数栈2 iconst_5 //常量5压入操作数栈3 multianewarray #1 dim #2 //new二位数组7 astore_1 //存储到局部变量表第一个位置8 aload_1 //grid压入操作数栈9 areturn
multianewarray指令的第一个操作数是运行时常量池索引&#xff0c;它表示将要被创建的数组的成员类型。第二个操作数是需要创建的数组的实际维数。multianewarray指令可以用于创建所有类型的多维数组&#xff0c;譬如create3DArray中展示的。注意&#xff0c;多维数组也只是一个对象&#xff0c;所以使用aload_1指令加载&#xff0c;使用areturn指令返回。
所有的数组都有一个与之关联的长度属性&#xff0c;通过arraylength指令访问。
编译switch语句
在Java程序语言中&#xff0c;遇到switch语句我们应该首先想到是否能够不用或者改用多态来实现相关功能&#xff0c;但是在Java虚拟机层面&#xff0c;我们还是有必要知道switch语句是怎样编译的。
编译器会使用tableswitch和lookupswitch指令来生成switch语句的编译代码。tableswitch指令用于表示switch结构中的case语句块&#xff0c;可以高效地从索引表中确定case语句块的分支偏移量。当switch语句中提供的条件值不能从索引表中确定任何一个case语句块的分支偏移量时&#xff0c; default分支将起作用。譬如&#xff1a;
int chooseNear(int i)
{
switch (i)
{
case 0: return 0;
case 1: return 1;
case 2: return 2;
default: return -1;
}
}
编译后字节码如下&#xff1a;
Method int chooseNear(int)
0 iload_1 //局部变量i压入操作数栈1 tableswitch 0 to 2: //建立索引表0: 28 //0执行281: 30 //1执行302: 32 //2执行32default:34 //其他执行3428 iconst_0 //i was 0; push int constant 0...29 ireturn //...and return it30 iconst_1 //i was 1; push int constant 1...31 ireturn //...and return it32 iconst_2 //i was 2; push int constant 2...33 ireturn //...and return it34 iconst_m1 //otherwise push int constant –1...35 ireturn //...and return it
Java虚拟机的tableswitch和lookupswitch指令都只能支持int类型的条件值。选择支持int类型是因为byte、char和short类型的值都会被隐式展为int型。如果chooseNear()方法中使用short类型作为条件值&#xff0c;那编译出来的代码中与使用int类型时是完全相同的。如果使用其他数值类型的条件值&#xff0c;那就必须窄化转换成int类型。
当switch语句中的case分支的条件值比较稀疏时&#xff0c;tableswitch指令的空间使用率偏低。这种情况下将使用lookupswitch指令来替代。lookupswitch指令的索引表由int型的键值(来源于case语句块后面的数值)与对应的目标语句偏移量所构成。当lookupswitch指令执行时&#xff0c;switch语句的条件值将和索引表中的key进行比较&#xff0c;如果某个key和条件值相符&#xff0c;那么将转移到这个key对应的分支偏移量继续执行&#xff0c;如果没有key值符合&#xff0c;执行将在default分支执行。譬如&#xff1a;
int chooseFar(int i)
{
switch (i)
{
case -100: return -1;
case 0: return 0;
case 100: return 1;
default: return -1;
}
}
编译后的代码如下&#xff0c;相比chooseNear()方法的编译代码&#xff0c;仅仅把tableswitch指令换成了lookupswitch指令&#xff1a;
Method int chooseFar(int)
0 iload_1
1 lookupswitch
3: −100: 36
0: 38
100: 40
default:42
36 iconst_m1
37 ireturn
38 iconst_0
39 ireturn
40 iconst_1
41 ireturn
42 iconst_m1
43 ireturn
Java虚拟机规定的lookupswitch指令的索引表必须根据key值排序&#xff0c;这样使用(如采用二分搜索)将会比直接使用线性扫描搜索来得更有效率。在从索引表确定分支偏移量的过程中&#xff0c;lookupswitch指令是把条件值与不同的key的进行比较&#xff0c;而tableswitch指令则只需要索引值进行一次范围检查。因此&#xff0c;在如果不需要考虑空间效率时&#xff0c;tableswitch指令相比lookupswitch指令有更高的执行效率。
使用操作数栈
Java虚拟机为方便使用操作数栈&#xff0c;提供了的大量的不区分操作数栈数据类型的指令。这些指令都很常用&#xff0c;因为Java虚拟机是基于栈的虚拟机&#xff0c;大量操作是建立在操作数栈的基础之上的。譬如&#xff1a;
public long nextIndex()
{
return index&#43;&#43;;
}
private long index &#61; 0;
编译后字节码如下&#xff1a;
Method long nextIndex()
0 aload_0 //当前实例的自身引用this压入操作数栈1 dup //复制this压入栈顶2 getfield #4 //取得类变量index&#xff0c;同时栈顶的this副本被消耗5 dup2_x1 //复制栈顶两个字长的数据&#xff0c;弹出栈顶三个字长的数据&#xff0c;将复制后的两个字长的数据压栈&#xff0c;再将弹出的三个字长的数据压栈。6 lconst_1 //long型常量1压入栈顶7 ladd //index&#43;18 putfield #4 //类变量index值改变11 lreturn //
抛出异常和处理异常
Java程序中用throw关键字来抛出异常&#xff1a;
void cantBeZero(int i) throws TestExc
{
if (i &#61;&#61; 0)
{
throw new TestExc();
}
}
编译后字节码如下&#xff1a;
Method void cantBeZero(int)
0 iload_1 //i压入操作数栈1 ifne 12 //如果i&#61;&#61;0 执行124 new #1 //new一个TestExc实例7 dup //复制一份压入栈顶8 invokespecial #7 //调用类实例初始化方法 并消耗掉栈顶的实例副本11 athrow //throw12 return //如果抛出异常&#xff0c;这里永远不执行
try-catch结构的编译也同样简单&#xff1a;
void catchOne() {
try
{
tryItOut();
}
catch (TestExc e)
{
handleExc(e);
}
}
编译后字节码如下&#xff1a;
Method void catchOne()
0 aload_0 //this压入栈顶1 invokevirtual #6 //调用方法4 return //返回5 astore_1 //6 aload_0 //this压入栈7 aload_1 //Push thrown value8 invokevirtual #5 //Invoke handler method://Example.handleExc(LTestExc;)V11 return //Return after handling TestExc
Exception table:
From To Target Type
0 4 5 Class TestExc
可以看到&#xff0c;try语句块被编译后似乎没有生成任何指令&#xff0c;如果在try语句块执行过程中没有异常抛出&#xff0c;程序那么就犹如没有使用try结构一样&#xff1a;在tryItOut()调用catchOne()方法后就返回了。
字节码中5-11行是Java虚拟机实现的catch语句&#xff0c;在catch语句块里&#xff0c;调用handleExc()方法的指令和正常的方法调用完全一样。不过&#xff0c;每个catch语句块的会使编译器在异常表中增加一个成员&#xff0c;此例中的成员是0 4 5 Class TestExc&#xff0c;如果在0-4句中有TestExc实例被抛出&#xff0c;那么操作将转移到第5步。如果异常并不是TestExc&#xff0c;那么catch语句并不能捕获它。
一个try结构中可包含多个catch语句块&#xff0c;譬如&#xff1a;
void catchTwo()
{
try {
tryItOut();
}
catch (TestExc1 e)
{
handleExc(e);
}
catch (TestExc2 e)
{
handleExc(e);
}
}
如果try语句包含有多个catch语句块&#xff0c;那么在编译代码中&#xff0c;多个catch语句块的内容将连续排列&#xff0c;在异常表中也会有对应的连续排列的成员&#xff0c;它们的排列的顺序和源码中的catch语句块出现的顺序一致。
Method void catchTwo()
0 aload_0
1 invokevirtual #5
4 return
5 astore_1
6 aload_0
7 aload_1
8 invokevirtual #7
11 return
12 astore_1
13 aload_0
14 aload_1
15 invokevirtual #7
18 return
Exception table:
From To Target Type
0 4 5 Class TestExc1
0 4 12 Class TestExc2
编译finally语句块
很早之前(JDK 1.4.2之前)的Sun Javac已经不再为finally语句生成jsr和ret指令了&#xff0c;而是改为在每个分支之后冗余代码的形式来实现finally语句&#xff0c;所以如果想了解finally语句早期的编译方法请自己看书。
同步
Java虚拟机中的同步(Synchronization)基于进入和退出线程(Monitor)对象实现。无论是显式同步(有明确的monitorenter和monitorexit指令)还是隐式同步(依赖方法调用和返回指令实现的)都是如此。
在Java语言中&#xff0c;同步用的最多的地方可能是被synchronized修饰的同步方法。同步方法并不是由monitorenter和monitorexit指令来实现同步的&#xff0c;而是由方法调用指令读取运行时常量池中方法的ACC_SYNCHRONIZED标志来隐式实现的。
monitorenter和monitorexit指令用于实现同步语句块&#xff0c;譬如&#xff1a;
void onlyMe(Foo f)
{
synchronized(f)
{
doSomething();
}
}
编译后字节码如下&#xff1a;
Method void onlyMe(Foo)
0 aload_1 //f压入栈顶1 dup //复制压入栈顶2 astore_2 //将复制的f存储在第2个局部变量位置3 monitorenter //进入线程4 aload_0 //保持住线程同步&#xff0c;将this压入栈顶5 invokevirtual #5 //调用方法8 aload_2 //将f压入栈顶9 monitorexit //推出关联f的线程10 goto 18 //正常推出13 astore_3 14 aload_2 15 monitorexit //发生异常时&#xff0c;确保执行monitorexit指令16 aload_3 17 athrow 18 return Exception table:
FromTo Target Type
4 10 13 any 13 16 13 any
编译器必须确保无论方法通过何种方式完成&#xff0c;方法中调用过的每条monitorenter指令都必须有执行其对应monitorexit指令&#xff0c;而无论这个方法是正常结束还是异常结束。为了保证在方法异常完成时monitorenter和monitorexit指令依然可以正确配对执行&#xff0c;编译器会自动产生一个异常处理器&#xff0c;这个异常处理器声明可处理所有的异常&#xff0c;它的目的就是用来执行monitorexit指令。
这章到此结束&#xff0c;比较漫长&#xff0c;比较枯燥&#xff0c;毕竟是比较底层的字节码指令&#xff0c;规则之类的。相比于设计模式等技术学习起来子让是少了点乐趣和思维。但是这是基础&#xff0c;仔细学习完以后对于Java虚拟机的编译和各种指令都会有详细的了解&#xff0c;下一次将学习Class文件格式。





 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有