在做新聞推薦系統的時候,首先要做的應該是抓取新聞,從中提取關鍵字,其次是運用機器學習裡面的聚類分類方法根據瀏覽記錄對用戶進行分組,在組內進行推薦。在這裡我只是簡單說下抓取新聞之後如何從中提取出關鍵字,其他內容就不在這裡介紹了。
關於提取關鍵字的理論基礎,強烈推薦大家看這篇文章:TF-IDF與餘弦相似性的應用(一):自動提取關鍵詞,作者是大名鼎鼎的阮一峰。了解了提取關鍵字是怎麼一回事後,接下來就是實踐的過程了,不用擔心,其實別人早就給我們寫好了提取關鍵字的工具,自己只需要調用其接口就行,省時省力,何樂而不為呢?
目前網絡上這方面的工具有不少,就使用來看主要有下面兩個開源的工具,一個是北理工張華平(曉陽速來拜見導師)老師的NLPIR,專門做分詞的,號稱全球第一;還有一個是復旦大學fudanNLP。這兩個工具各有特點:NLPIR是用C++寫的,C++,C#很容易調用,JAVA調用起來還要用JNI,感覺比較麻煩;fudanNLP本身就是java實現的,JAVA調用起來很方便。所以看你的平台,這裡我是JAVA,首選fudanNLP,如果非要在JAVA下使用NLPIR,建議參看這篇文章:http://blog.csdn.net/zhyh1986/article/details/9167593,下面就不介紹NLPIR了。
1、下載fudanNLP
解壓後能看見很多文件,不過只需要和下面這幾個文件/文件夾打交道:
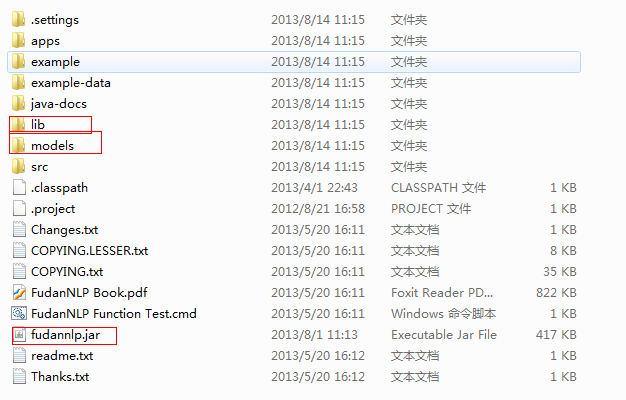
2、添加jar和models
創建一個工程,把lib下所有的jar包和fudannlp.jar包添加到項目中,同時把models文件夾拷貝到項目下:
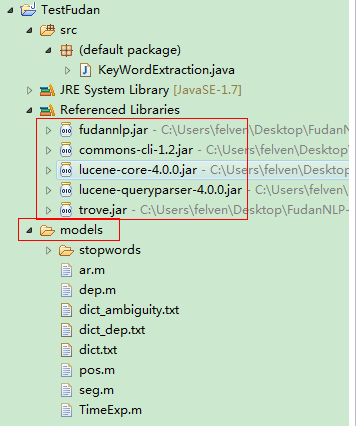
3、寫關鍵字提取函數
添加好之後下面就可以寫提取關鍵字的函數了,如果不知道怎麼寫可以參看fudanNLP自帶的例子:
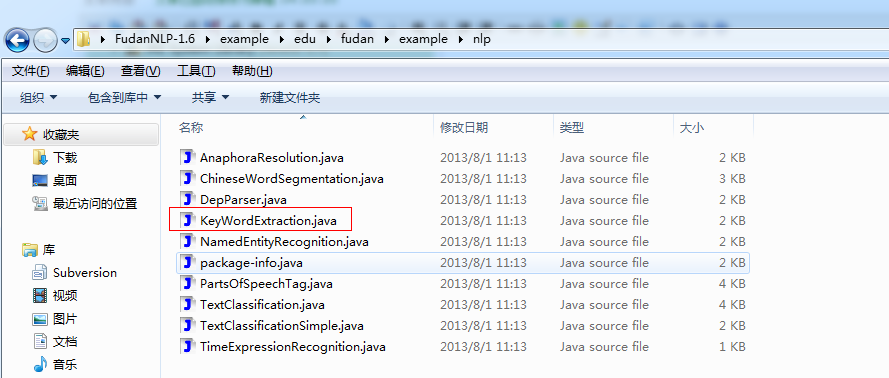
這裡我只需要在原有代碼的基礎上加以修改,注意到提取到的關鍵字是作為一個Map保存起來的:
Map ans = key.extract(String str, Integer n);
那我只需要傳遞str和n,然後讀取map中的key值即可得到關鍵字,全部代碼如下:
import java.util.ArrayList;
import java.util.Map;
import org.fnlp.app.keyword.AbstractExtractor;
import org.fnlp.app.keyword.WordExtract;
import edu.fudan.nlp.cn.tag.CWSTagger;
import edu.fudan.nlp.corpus.StopWords;
public class GetKeywords {
public ArrayList GetKeyword(String News,int keywordsNumber) throws Exception{
ArrayList keywords=new ArrayList();
StopWords sw= new StopWords("models/stopwords");
CWSTagger seg = new CWSTagger("models/seg.m");
AbstractExtractor key = new WordExtract(seg,sw);
//you need to set the keywords number, here you will get 10 keywords
Map ans = key.extract(News, keywordsNumber);
for (Map.Entry entry : ans.entrySet()) {
String keymap = entry.getKey().toString();
String value = entry.getValue().toString();
keywords.add(keymap);
System.out.println("key=" + keymap + " value=" + value);
}
return keywords;
}
}
輸出結果是這樣:

其實後面那個value值應該是用來標記某個詞重要性的,值越大證明越可能是關鍵詞,這裡我並不需要用到。
好了,調用別人的工具就是這麼簡單,當然fudanNLP的功能遠不止這些,可以上它的演示網站看看:http://jkx.fudan.edu.cn/nlp/
註:fudanNLP的關鍵詞提取技術並不是用TF-IDF,而是類似於Pagerank的Textrank,具體可以參看這篇論文:
感謝曉陽童鞋更正
最後附上別人寫的通過web service調用FudanNLP的代碼:
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URL;
import java.net.URLEncoder;
/**
* FudanNLP Web Services使用示例
* @author 趙嘉億
*/
public class Demo {
static String u = "http://jkx.fudan.edu.cn/fudannlp/";
public static String nlp(String func, String input) throws IOException {
// must encode url!! if we write FudannlpResource.seg(String) this way
input = URLEncoder.encode(input, "utf-8"); //utf-8 重要!
URL url = new URL( u + func + "/" + input);
StringBuffer sb = new StringBuffer();
BufferedReader out = new BufferedReader(new InputStreamReader(url.openStream(), "utf-8")); //utf-8 重要!
String line;
while ((line = out.readLine()) != null)
sb.append(line);
out.close();
return sb.toString();
}
public static String welcome() throws IOException {
URL url = new URL(u);
StringBuffer sb = new StringBuffer();
BufferedReader out = new BufferedReader(new InputStreamReader(url.openStream(), "utf-8"));
String line;
while ((line = out.readLine()) != null)
sb.append(line);
out.close();
return sb.toString();
}
public static String nlp(String func) throws IOException {
URL url = new URL(u + func);
StringBuffer sb = new StringBuffer();
BufferedReader out = new BufferedReader(new InputStreamReader(url.openStream(), "utf-8"));
String line;
while ((line = out.readLine()) != null)
sb.append(line);
out.close();
return sb.toString();
}
public static void main(String[] args) throws IOException {
// 也可直接用IE訪問 http://jkx.fudan.edu.cn/fudannlp/seg/開源中文自然語言處理工具包 FudanNLP
System.out.println(welcome());
System.out.println(nlp("key"));
System.out.println(nlp("seg", "開源中文自然語言處理工具包 FudanNLP"));
System.out.println(nlp("ner", "開源中文自然語言處理工具包 FudanNLP"));
System.out.println(nlp("time", "2010-10-10"));
}
}







 京公网安备 11010802041100号
京公网安备 11010802041100号