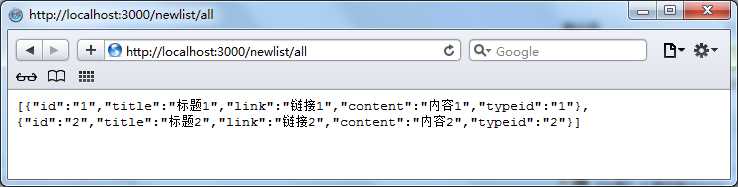
数据库相关软件
MySQL数据库介绍:
在网站开发中,数据库是网站的重要组成部分。只有提供数据库,数据才能够动态的展示,而不是在网页中显示一个静态的页面。数据库有很多,比如有 SQL Server 、 Oracle 、 PostgreSQL 以及 MySQL 等等。 MySQL 由于价格实惠、简单易用、不受平台限制、灵活度高等特性,目前已经取得了绝大多数的市场份额。因此我们在 Django 中,也是使用 MySQL 来作为数据存储。
MySQL驱动程序安装:
我们使用 Django 来操作 MySQL ,实际上底层还是通过 Python 来操作的。因此我们想要用 Django 来操作 MySQL ,首先还是需要安装一个驱动程序。在 Python3 中,驱动程序有多种选择。比如有 pymysql 以及 mysqlclient 等。这里我们就使用 mysqlclient 来操作。 mysqlclient 安装非常简单。只需要通过pip install mysqlclient即可安装。
注意:musqlclient遇到以下问题:
问题:building 'MySQLdb._mysql' extension error: Microsoft Visual C++ 14.0 is required. Get it with "Microsoft Visual C++ Build Tools": http://landinghub.visualstudio.com/visual-cpp-build-tools
解决办法:
先查看我的python版本信息为:
Python 3.6.5 (v3.6.5:f59c0932b4, Mar 28 2018, 16:07:46) [MSC v.1900 32 bit (Intel)] on win32
下载whl文件手动安装
选择版本(选择的版本cp后的值要和python版本对应,否则会报错“is not a supported wheel on this platform.”)
mysqlclient-1.4.2-cp36-cp36m-win32.whl
到下载目录下执行命令D:\flower\download
pip install mysqlclient-1.4.2-cp36-cp36m-win32.whl
Django操作MySQL常见驱动介绍:
1、MySQL-python :也就是 MySQLdb 。是对 C 语言操作 MySQL 数据库的一个简单封装。遵循了 Python DB API v2 。但是只支持 Python2 ,目前还不支持 Python3 。
2、mysqlclient :是 MySQL-python 的另外一个分支。支持 Python3 并且修复了一些 bug 。
3、pymysql :纯 Python 实现的一个驱动。因为是纯 Python 编写的,因此执行效率不如 MySQLpython 。并且也因为是纯 Python 编写的,因此可以和 Python 代码无缝衔接。
4、MySQL Connector/Python : MySQL 官方推出的使用纯 Python 连接 MySQL 的驱动。因为是纯 Python 开发的。效率不高。
Django使用原生sql语句操作数据库
使用navicat连接数据库
1. 点击连接,连接Mysql

2.创建数据库
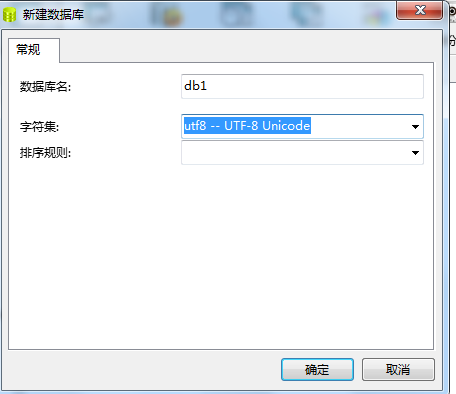
3.创建表,
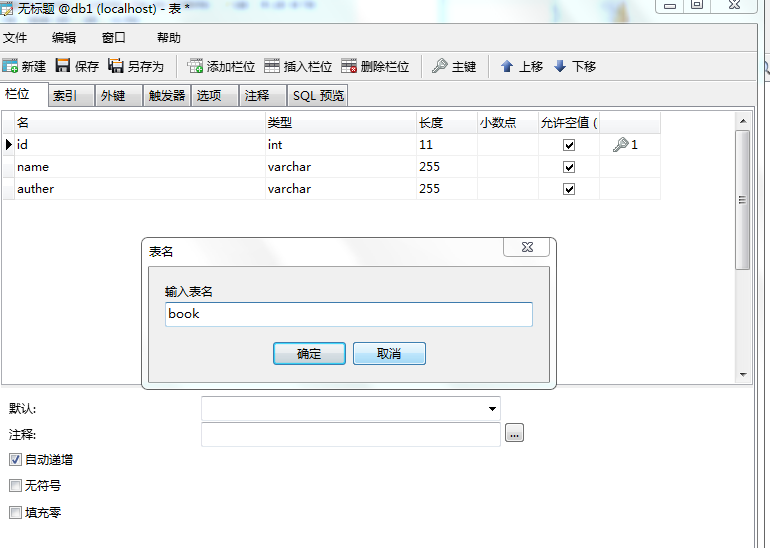
Django配置连接数据库:
在操作数据库之前,首先先要连接数据库。这里我们以配置 MySQL 为例来讲解。 Django 连接数据库,不需要单独的创建一个连接对象。只需要在 settings.py 文件中做好数据库相关的配置就可以了。代码如下:
settings.py
DATABASES ={'default': {#数据库引擎(sqlite3/mysql/oracle等)
'ENGINE': 'django.db.backends.mysql','NAME': 'db1','USER': 'root','PASSWORD': 'root','HOST': '127.0.0.1','PORT': '3306'}
}
在Django中操作数据库:
在 Django 中操作数据库有两种方式。第一种方式就是使用原生 sql 语句操作,第二种就是使用 ORM 模型来操作。在 Django 中使用原生 sql 语句操作其实就是使用 python db api 的接口来操作。如果你的 mysql 驱动使用的是 pymysql ,那么你就是使用 pymysql 来操作的,只不过 Django 将数据库连接的这一部分封装好了,我们只要在 settings.py 中配置好了数据库连接信息后直接使用 Django 封装好的接口就可以操作了。示例代码如下:
views.py
from django.shortcuts importrenderfrom django.shortcuts importrender#使用django封装好的connection对象,会自动读取settings.py中数据库的配置信息
from django.db importconnectiondefindex(request):
cursor= connection.cursor() #获取游标对象
cursor.execute("insert into book(name,auther) values ('python','flowers')")#拿到游标对象后执行sql语句
#cursor.execute("select * from book")
#result = cursor.fetcall() # 获取所有的数据
#for row in result:
#print(row)
return render(request,'index.html')
以上的 execute 以及 fetchall 方法都是 Python DB API 规范中定义好的。任何使用 Python 来操作 MySQL 的驱动程序都应该遵循这个规范。所以不管是使用 pymysql 或者是 mysqlclient 或者是 mysqldb ,他们的接口都是一样的。更多规范请参考:https://www.python.org/dev/peps/pep-0249/。
urls.py
from django.urls importpathfrom sq1 importviews
urlpatterns=[
path('', views.index),
]
执行项目,打开http://127.0.0.1:8000
效果图如下:
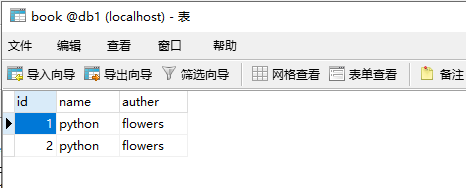
Python DB API下规范下cursor对象常用接口:
1、description :如果 cursor 执行了查询的 sql 代码。那么读取 cursor.description 属性的时候,将返回一个列表,这个列表中装的是元组,元组中装的分别是 (name,type_code,display_size,internal_size,precision,scale,null_ok) ,其中 name 代表的是查找出来的数据的字段名称,其他参数暂时用处不大。
2、rowcount :代表的是在执行了 sql 语句后受影响的行数。
3、close :关闭游标。关闭游标以后就再也不能使用了,否则会抛出异常。
4、execute(sql[,parameters]) :执行某个 sql 语句。如果在执行 sql 语句的时候还需要传递参数,那么可以传给 parameters 参数。示例代码如下:
cursor.execute("select * from article where id=%s",(1,))
5、fetchone :在执行了查询操作以后,获取第一条数据。
6、fetchmany(size) :在执行查询操作以后,获取多条数据。具体是多少条要看传的 size 参数。如果不传 size 参数,那么默认是获取第一条数据。
7、fetchall :获取所有满足 sql 语句的数据。
图书管理系统案例
原生Django使用原生sql操作数据库,主要实现如下功能:图书查看(包括详情)、添加和删除
目录如下:
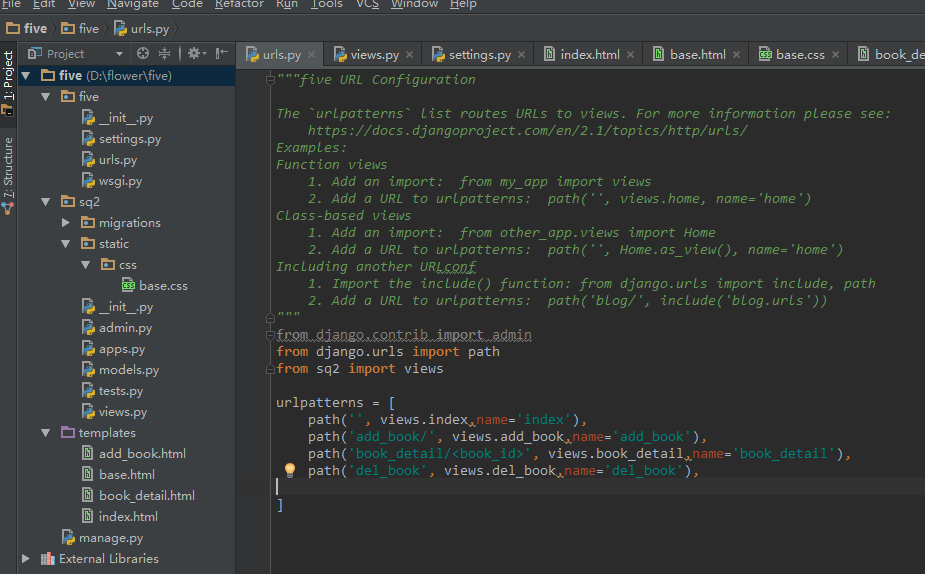
urls.py
from django.urls importpathfrom sq2 importviews
urlpatterns=[
path('', views.index,name='index'),
path('add_book/', views.add_book,name='add_book'),
path('book_detail/', views.book_detail,name='book_detail'),
path('del_book', views.del_book,name='del_book'),
]
setting.py中,MySQL数据库配置,同时关闭中间件的csrf功能:
#mysql数据库配置
DATABASES={'default': {#数据库引擎(sqlite3/mysql/oracle等)
'ENGINE': 'django.db.backends.mysql','NAME': 'book_manage','USER': 'root','PASSWORD': 'root','HOST': '127.0.0.1','PORT': '3306'}
}
MIDDLEWARE=[#'django.middleware.csrf.CsrfViewMiddleware',
]
静态文件模板——base.html
{% load static %}
图书管理系统{% block content %}
{% endblock %}
index.css 内容
*{margin:0;padding:0;
}.nav{background:#3a3a3a;height:65px;overflow:hidden;
}.nav li{float:left;list-style:none;margin:0 20px;line-height:65px;
}.nav li a{color:#fff;text-decoration:none;
}.nav li a:hover{color:lightblue;
}
index.html首页内容
{% extends 'base.html' %}
{% block content %}
序号书名作者
{% for book in books %}{{ forloop.counter }}{{ book.1 }}{{ book.2 }}{% endfor %}{% endblock %}add_book.html
{% extends 'base.html' %}
{% block content %}
| 书名: | |
| 作者: | |
{% endblock %}
book_detail.html
{% extends 'base.html' %}
{% block content %}
书名:{{ book.1 }}
作者:{{ book.2 }}
{% endblock %}
views.py
from django.shortcuts importrender, redirect, reversefrom django.db importconnection#将cursor定义函数
defget_cursor():returnconnection.cursor()defindex(request):
cursor= get_cursor() #获取cursor
cursor.execute("select * from book")
books=cursor.fetchall()return render(request,'index.html',cOntext={'books':books})defadd_book(request):if request.method == 'GET':return render(request, 'add_book.html')else:
name= request.POST.get('name')
author= request.POST.get('author')
cursor=get_cursor()
cursor.execute("insert into book (name, author) VALUES ('%s', '%s')" %(name, author))return redirect(reverse('index'))defbook_detail(request, book_id):
cursor=get_cursor()
cursor.execute("select * from book where id=%s" %book_id)
book=cursor.fetchone()#print(book[0],book[1],book[2])
print(type(book))return render(request, 'book_detail.html', {'book': book})defdel_book(request):if request.method == "POST":
book_id= request.POST.get("book_id")
cursor=get_cursor()
cursor.execute("delete from book where id=%s" %book_id)returnredirect(reverse(index))else:raise RuntimeError("删除图书失败!!!")
ORM模型介绍:
随着项目越来越大,采用写原生SQL的方式在代码中会出现大量的SQL语句,那么问题就出现了:
1、SQL语句重复利用率不高,越复杂的SQL语句条件越多,代码越长。会出现很多相近的SQL语句;
2、很多SQL语句是在业务逻辑中拼出来的,如果有数据库需要更改,就要去修改这些逻辑,这会很容易漏掉对某些SQL语句的修改;
3、写SQL时容易忽略web安全问题,给给未来造成隐患。SQL注入;
如何解决上面的问题:
ORM ,全称 Object Relational Mapping ,中文叫做对象关系映射,通过 ORM 我们可以通过类的方式去操作数据库,而不用再写原生的SQL语句。通过把表映射成类,把行作实例,把字段作为属性, ORM 在执行对象操作的时候最终还是会把对应的操作转换为数据库原生语句。使用 ORM 有许多优点:
1、易用性:使用 ORM 做数据库的开发可以有效的减少重复SQL语句的概率,写出来的模型也更加直观、清晰;
2、性能损耗小: ORM 转换成底层数据库操作指令确实会有一些开销。但从实际的情况来看,这种性能损耗很少(不足5%),只要不是对性能有严苛的要求,综合考虑开发效率、代码的阅读性,带来的好处要远远大于性能损耗,而且项目越大作用越明显;
3、设计灵活:可以轻松的写出复杂的查询;
4、可移植性: Django 封装了底层的数据库实现,支持多个关系数据库引擎,包括流行的 MySQL 、 PostgreSQL 和 SQLite 。可以非常轻松的切换数据库;
创建和映射ORM模型
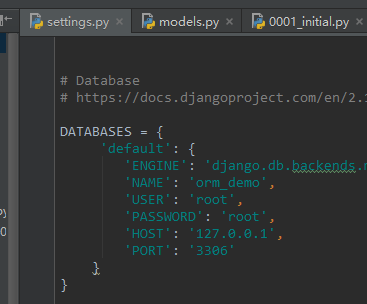
ORM 模型一般都是放在 app 的 models.py 文件中。每个 app 都可以拥有自己的模型。并且如果这个模型想要映射到数据库中,那么这个 app 必须要放在 settings.py 的 INSTALLED_APP 中进行安装。首先创建一个数据库,然后配置在settings.py中链接MYSQL;
settings.py
models.py
from django.db importmodelsfrom datetime importdatetime#如果要将普通类变成一个可以映射到数据库中的ORM模型,那么必须要将弗雷设置为models.Model或者他的子类
classbook(models.Model):
id= models.AutoField(primary_key=True) #AutoField代表自动增长,primary_key=True代表主键
name= models.CharField(max_length=100,null=False) #CharField可变长度,必须指定一个长度字符,null不能为空
author= models.CharField(max_length=100,null=False)
time= models.DateTimeField(default=datetime.now()) #数据类型是 datetime 类型
price = models.FloatField(default=0,null=False) #浮点类型,默认值0
#如果一个模型没有定义主键,那么将会自动生成一个自动增长的 int 类型的主键,并且这个主键的名字就叫做 id
classpublisher(models.Model):
name= models.CharField(max_length=100,null=False)
address= models.CharField(max_length=100,null=False)
映射模型到数据库中:
将 ORM 模型映射到数据库中,总结起来就是以下几步:
1、在 settings.py 中,配置好 DATABASES ,做好数据库相关的配置;
2、在 app 中的 models.py 中定义好模型,这个模型必须继承自 django.db.models ;
3、将这个 app 添加到 settings.py 的 INSTALLED_APP 中;
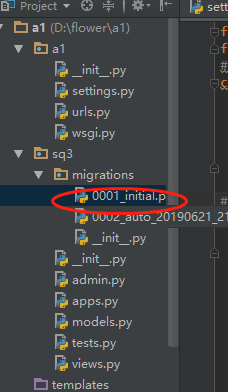
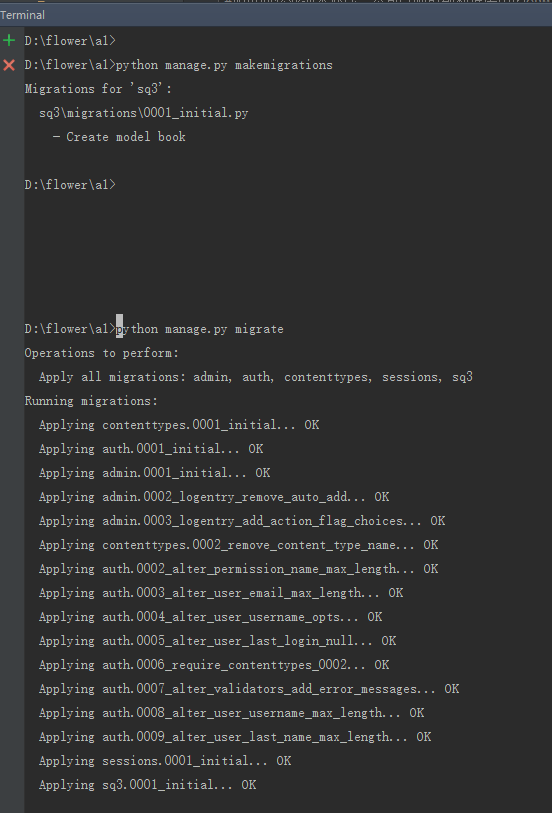
4、在命令行终端,进入到项目所在的路径,然后执行命令:python manage.py makemigrations 来生成迁移脚本文件。
5、同样在命令行中,执行命令 python manage.py migrate 来将迁移脚本文件映射到数据库中;
执行第一个命令,会生成一个文件,如下:
命令执行效果图如下:
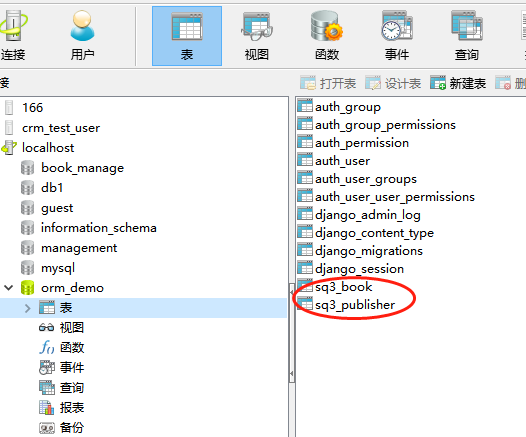
数据表结果图如下:
ORM模型基本的增删改查
实例代码如下:
settings.py配置数据库以及添加app
INSTALLED_APPS =['sq4',
]
DATABASES={'default': {'ENGINE': 'django.db.backends.mysql','NAME': 'orm_demo2','USER': 'root','PASSWORD': 'root','HOST': '127.0.0.1','PORT': '3306'}
}
models.py
from django.db importmodelsclassbook(models.Model):
id= models.AutoField(primary_key=True)
name= models.CharField(max_length=100,null=False)
author= models.CharField(max_length=100,null=False)
price= models.FloatField(default=0)#查询出来的数据为了更加美观,打印对象的时候自动调用str方法
def __str__(self):return "".format(name=self.name,author=self.author,price=self.price)
view.py
from django.shortcuts importrenderfrom django.http importHttpResponsefrom .models importbookdefindex(request):##1.使用ORM添加数据到数据库中
#book1 = book(name='python菜鸟教程',author='李宁',price=79)
#book1.save()
#2.查询数据,根据主键id进行查询,pk=primary key,同样也可以使用id查找;
#book2=book.objects.get(pk=1)
#print(book2)
##根据其他条件进行查找,filter过滤,会查询出name值=python的所有数据查出来;book.objects.filter(name='python').first()first()代表查出第一条数据
#book3 = book.objects.filter(name='python')
#print(book3)
#3.删除数据
book4 = book.objects.get(pk=1)
book4.delete()#4.修改数据
book5 = book.objects.get(pk=2)
book5.price=80book5.save()return HttpResponse("操作成功!")
urls.py
from sq4 importviews
urlpatterns=[
path('', views.index),
]
注意:遇到一个坑,数据库的字符集写的不是utf-8,然后就出现了数据新增时报错;
ORM常用Field详解
AutoField:
映射到数据库中是 int 类型,可以有自动增长的特性。一般不需要使用这个类型,如果不指定主键,那么模型会自动的生成一个叫做 id 的自动增长的主键。如果你想指定一个其他名字的并且具有自动增长的主键,使用 AutoField 也是可以的。
BigAutoField:
64位的整形,类似于 AutoField ,只不过是产生的数据的范围是从 1-9223372036854775807 。
BooleanField:
在模型层面接收的是 True/False 。在数据库层面是 tinyint 类型。如果没有指定默认值,默认值是 None 。
django.utils.timezone.now方法:
会根据settings.py中是否设置了USE_TZ=True获取当前的时间。如果设置了,那么就获取一个aware类型的UTC时间。如果没有设置,那么就会获取一个navie类型的时间。
django.utils.timezone.localtime方法:
会根据setting.py中的TIME_ZONE来将一个aware类型的时间转换为TIME_ZONE指定时区的时间。
DateField:
日期类型。在Python中是datetime.date类型,可以记录年月日。在映射到数据库中也是date类型。使用这个Field可以传递以下几个参数:
auto_now:在每次这个数据保存的时候,都使用当前的时间。比如作为一个记录修改日期的字段,可以将这个属性设置为True。
auto_now_add:在每次数据第一次被添加进去的时候,都使用当前的时间。比如作为一个记录第一次入库的字段,可以将这个属性设置为True。
DateTimeField:
日期时间类型,类似于DateField。不仅仅可以存储日期,还可以存储时间。映射到数据库中是datetime类型。这个Field也可以使用auto_now和auto_now_add两个属性。
TimeField:
时间类型。在数据库中是time类型。在Python中是datetime.time类型。
EmailField:
类似于 CharField 。在数据库底层也是一个 varchar 类型。最大长度是254个字符;
FileField:
用来存储文件的。这个请参考后面的文件上传章节部分;
ImageField:
用来存储图片文件的。这个请参考后面的图片上传章节部分;
FloatField:
浮点类型。映射到数据库中是 float 类型;
IntegerField:
整形。值的区间是 -2147483648——2147483647 ;
BigIntegerField:
大整形。值的区间是 -9223372036854775808——9223372036854775807;
PositiveIntegerField:
正整形。值的区间是 0——2147483647 ;
SmallIntegerField:
小整形。值的区间是 -32768——32767 ;
PositiveSmallIntegerField:
正小整形。值的区间是 0——32767 ;
TextField:
大量的文本类型。映射到数据库中是longtext类型;
UUIDField:
只能存储 uuid 格式的字符串。 uuid 是一个32位的全球唯一的字符串,一般用来作为主键;
URLField:
类似于 CharField ,只不过只能用来存储 url 格式的字符串。并且默认的 max_length 是200;
Field的常用参数:
null:如果设置为 True , Django 将会在映射表的时候指定是否为空。默认是为 False 。在使用字符串相关的 Field (CharField/TextField)的时候,官方推荐尽量不要使用这个参数,也就是保持默认值 False 。因为 Django 在处理字符串相关的 Field 的时候,即使这个 Field 的 null=False ,如果你没有给这个 Field 传递任何值,那么 Django 也会使用一个空的字符串 "" 来作为默认值存储进去。因此如果再使用 null=True , Django 会产生两种空值的情形(NULL或者空字符串)。如果想要在表单验证的时候允许这个字符串为空,那么建议使用 blank=True 。如果你的 Field 是 BooleanField ,那么对应的可空的字段则为 NullBooleanField 。
blank:标识这个字段在表单验证的时候是否可以为空。默认是 False 。这个和 null 是有区别的, null 是一个纯数据库级别的。而 blank 是表单验证级别的。
db_column:这个字段在数据库中的名字。如果没有设置这个参数,那么将会使用模型中属性的名字。
default:默认值。可以为一个值,或者是一个函数,但是不支持 lambda 表达式。并且不支持列表/字典/集合等可变的数据结构。
primary_key:是否为主键。默认是 False 。
unique:在表中这个字段的值是否唯一。一般是设置手机号码/邮箱等。
navie时间和aware时间详解
navie时间和aware时间:
navie时间:不知道自己的时间表示的是哪个时区的。
aware时间:知道自己的时间表示的是哪个时区的。也就是比较清醒。
pytz库:
专门用来处理时区的库。这个库会经常更新一些时区的数据,不需要我们担心。并且这个库在安装Django的时候会默认的安装。如果没有安装,那么可以通过pip install pytz的方式进行安装。
astimezone方法:
将一个时区的时间转换为另外一个时区的时间。这个方法只能被aware类型的时间调用。不能被navie类型的时间调用。示例代码如下(Linux环境下进入python环境):
importpytzfrom datetime importdatetime
now= datetime.now() #这是一个navie类型的时间
utc_timezOne= pytz.timezone("UTC") #定义UTC的时区对象
utc_now = now.astimezone(utc_timezone) #将当前的时间转换为UTC时区的时间
>> ValueError: astimezone() cannot be applied to a naive datetime #会抛出一个异常,原因就是因为navie类型的时间不能调用astimezone方法
now= now.replace(tzinfo=pytz.timezone('Asia/Shanghai'))
utc_now=now.astimezone(utc_timezone)#这时候就可以正确的转换。
replace方法:
可以将一个时间的某些属性进行更改。
模型中 Meta 配置:
对于一些模型级别的配置。我们可以在模型中定义一个类,叫做 Meta 。然后在这个类中添加一些类属性来控制模型的作用。比如我们想要在数据库映射的时候使用自己指定的表名,而不是使用模型的名称。那么我们可以在 Meta 类中添加一个 db_table 的属性。示例代码如下:
class Book(models.Model):
name = models.CharField(max_length=20,null=False)
desc = models.CharField(max_length=100,name='description',db_column="description1")
class Meta:
db_table = 'book_model'
以下将对 Meta 类中的一些常用配置进行解释。
db_table:这个模型映射到数据库中的表名。如果没有指定这个参数,那么在映射的时候将会使用模型名来作为默认的表名。
ordering:设置在提取数据的排序方式。后面章节会讲到如何查找数据。比如我想在查找数据的时候根据添加的时间排序,那么示例代码如下:
classBook(models.Model):
name= models.CharField(max_length=20,null=False)
desc= models.CharField(max_length=100,name='description',db_column="description1")
pub_date= models.DateTimeField(auto_now_add=True)classMeta:
db_table= 'book_model'ordering= ['pub_date'] #ordering = ['-pub_date'] 加个-号就是倒序
ORM外键使用详解
外键的使用:
在 MySQL 中,表有两种引擎,一种是 InnoDB ,另外一种是 myisam 。如果使用的是 InnoDB 引擎,是支持外键约束的。外键的存在使得 ORM 框架在处理表关系的时候异常的强大。因此这里我们首先来介绍下外键在 Django 中的使用。注意:创建完数据模型需要执行迁移的两个命令,将表映射到数据库中。
主要包括以下三点:
1、外键的引用
2、如何引用不同app外键,语法:app.模型名
3、外键引用的是本身自己这个模型,那么 to 参数可以为 'self'
类定义为 class ForeignKey(to,on_delete,**options) 。第一个参数是引用的是哪个模型,第二个参数是在使用外键引用的模型数据被删除了,这个字段该如何处理,比如有 CASCADE 、 SET_NULL 等。
具体工程如下:
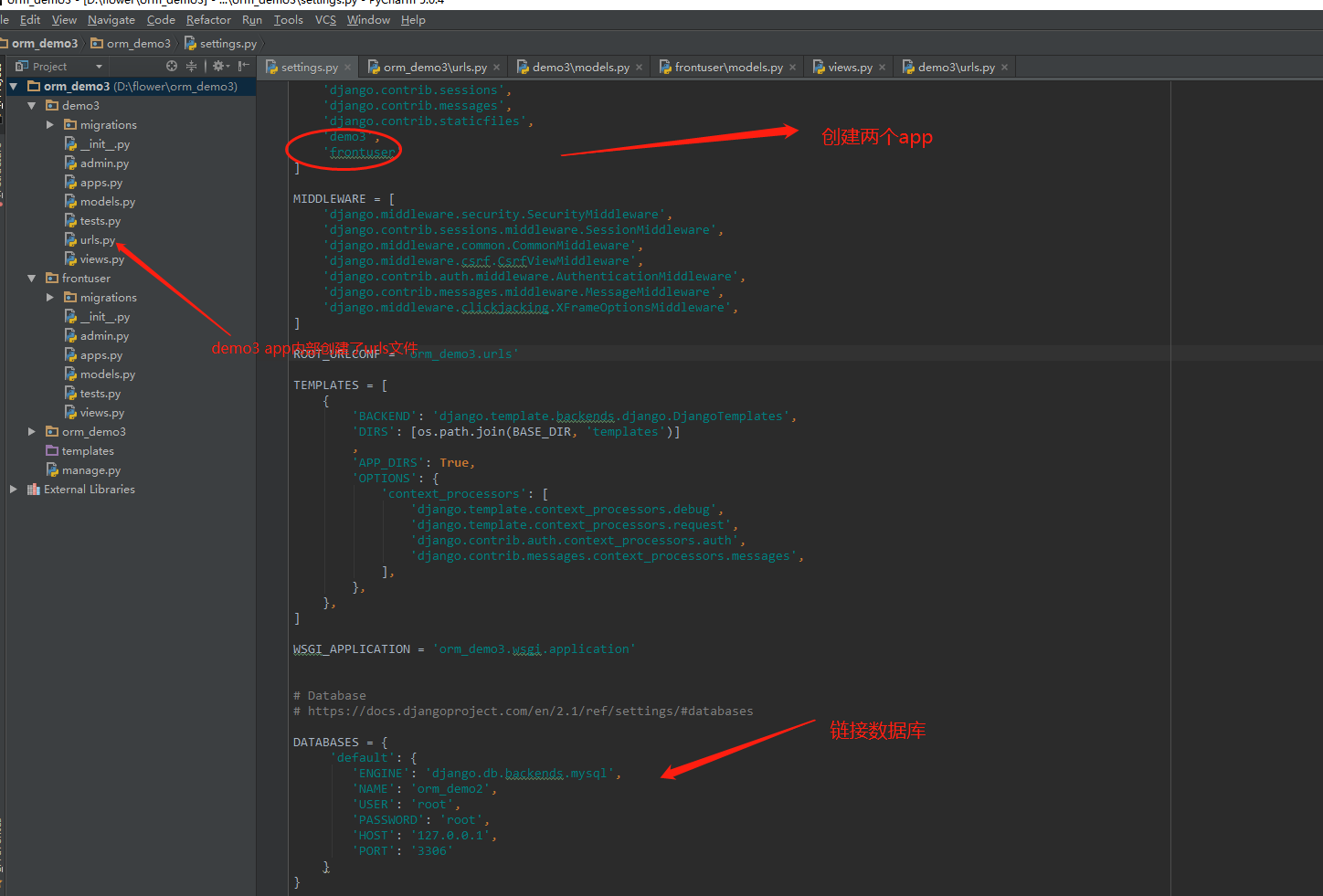
代码如下:
demo3/models.py
from django.db importmodelsclassCategory(models.Model):
name= models.CharField(max_length=128)classArticle(models.Model):
title= models.CharField(max_length=128)
cOntent=models.TextField()
category= models.ForeignKey("Category",on_delete=models.CASCADE) #同一个app外键
author = models.ForeignKey("frontuser.FronUser",on_delete=models.CASCADE,null=True) #如果想要引用另外一个 app 的模型,那么应该在传递 to 参数的时候,app.模型名字
#如果模型的外键引用的是本身自己这个模型,那么 to 参数可以为 'self' ,或者是这个模型的名字。在论坛开发中,一般评论都可以进行二级评论,即可以针对另外一个评论进行评论,那么在定义模型的时候就需要使用外键来引用自身
classcomment(models.Model):
cOntent=models.TextField()
origin_comment= models.ForeignKey('self', on_delete=models.CASCADE)#或
#origin_comment = models.ForeignKey('comment', on_delete=models.CASCADE)
demo3/views.py
from django.shortcuts importrenderfrom .models importCategory,Articlefrom django.http importHttpResponsedefindex(request):
category= Category(username='时政') #判断Category在数据库中是否存在,不存在会抛异常,所以要先保存下category
category.save()
article= Article(title="abc",cOntent='111')
article.category= category #Article指定category时,直接找到category这个模型就ok,不用找category_id
article.save()return HttpResponse('success')
demo3/urls.py
from django.urls importpathfrom . importviews
app_name= 'demo3' #命名空间
urlpatterns =[
path('', views.index,name='index')
]
urls.py
from django.contrib importadminfrom django.urls importpath,include
urlpatterns=[
path('', include('demo3.urls')),
]
frontuser/models.py 另外一个app的模型文件
from django.db importmodelsclassFronUser(models.Model):
username= models.CharField(max_length=200)
外键删除
如果一个模型使用了外键。那么在对方那个模型被删掉后,该进行什么样的操作。可以通过 on_delete 来指定。可以指定的类型如下:
1、CASCADE :级联操作。如果外键对应的那条数据被删除了,那么这条数据也会被删除。
2、PROTECT :受保护。即只要这条数据引用了外键的那条数据,那么就不能删除外键的那条数据。
3、SET_NULL:设置为空。如果外键的那条数据被删除了,那么在本条数据上就将这个字段设置为空。如果设置这个选项,前提是要指定这个字段可以为空。
4、SET_DEFAULT:设置默认值。如果外键的那条数据被删除了,那么本条数据上就将这个字段设置为默认值。如果设置这个选项,前提是要指定这个字段一个默认值。
5、SET() :如果外键的那条数据被删除了。那么将会获取 SET 函数中的值来作为这个外键的值。 SET 函数可以接收一个可以调用的对象(比如函数或者方法),如果是可以调用的对
象,那么会将这个对象调用后的结果作为值返回回去。
6、DO_NOTHING :不采取任何行为。一切全看数据库级别的约束。
以上这些选项只是Django级别的,数据级别依旧是RESTRICT!
表关系
表之间的关系都是通过外键来进行关联的。而表之间的关系,无非就是三种关系:一对一、一对多(多对一)、多对多等。以下将讨论一下三种关系的应用场景及其实现方式。
一对多:
1. 应用场景:比如文章和作者之间的关系。一个文章只能由一个作者编写,但是一个作者可以写多篇文章。文章和作者之间的关系就是典型的多对一的关系。
2. 实现方式:一对多或者多对一,都是通过 ForeignKey 来实现的。
demo3/models.py
from django.db importmodelsclassCategory(models.Model):"""文章分类表"""name= models.CharField(max_length=128)classArticle(models.Model):"""文章表"""title= models.CharField(max_length=128)
cOntent=models.TextField()
category= models.ForeignKey("Category",on_delete=models.CASCADE) #同一个app外键
#category = models.ForeignKey("Category", on_delete=models.CASCADE, related_name='articles') #如果想通过文章拿到一些对象,可以通过related_name
author = models.ForeignKey("frontuser.FronUser",on_delete=models.CASCADE,null=True) #不同app引用外键时,app.模型名字
#为了Article更加美观,打印对象模型时自动调用该方法,
def __str__(self):return "" % (self.id,self.title)

demo3/views.py
from frontuser.models importFronUserfrom django.http importHttpResponse#练习一对多
defon_to_many_view(request):"""1.一对多关联"""
#article = Article(title='鬼谷子',cOntent='111112') #创建文章
##获取文章分类和作者第一条数据
#category = Category.objects.first()
#author = FronUser.objects.first()
# #article.category = category
#article.author = author
#article.save()
#return HttpResponse('success')
"""2.获取分类下所有文章"""category=Category.objects.first()
article= category.article_set.all() #谁引用了表的字段作为外键,就设置这个 "模型的_set" 方法获取数据
for article inarticle:print(article)#第二种添加文章数据方式
article1 = Article(title='5555', cOntent="55577")
category.article_set.add(article1,bulk=False)#category.articles.add(article1,bulk=False) #如果模型中设置了: related_name='articles'
return HttpResponse('success')
一对一:








 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有