作者:初夏mx | 来源:互联网 | 2023-09-12 10:44
RDD的依赖关系
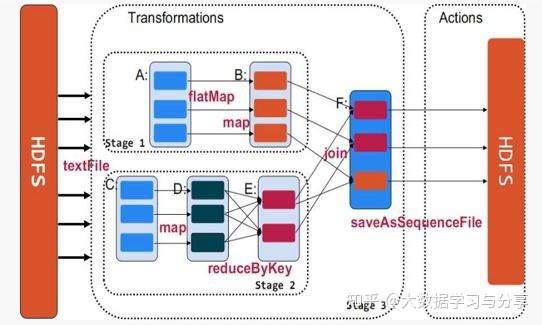
Spark中使用DAG(有向无环图)来描述RDD之间的依赖关系,根据依赖关系的不同,划分为宽依赖和窄依赖
通过上图,可以很容易得出所谓宽依赖:多个子RDD的partition会依赖同一个parentRDD的partition;窄依赖:每个parentRDD的partition最多被子RDD的一个partition使用。这两个概念很重要,像宽依赖是划分stage的关键,并且一般都会伴有shuffle,而窄依赖之间其实就形成前文所述的pipeline管道进行处理数据。(图中的map、filter等是Spark提供的算子,具体含义大家可以自行到Spark官网了解,顺便感受一下scala函数式编程语言的强大)。
Spark任务以及stage等的具体划分,牵涉到源码,后续会单独讲解
最后笔者以RDD源码中的注释,阐述一下RDD的属性:
- 分区列表(数据块列表,只保存数据位置,不保存具体地址)
2. 计算每个分片的函数(根据父RDD计算出子RDD)
3. RDD的依赖列表
4. RDD默认是存储于内存,但当内存不足时,会spill到disk(可通过设置StorageLevel来控制)
5. 默认hash分区,可自定义分区器
6. 每一个分片的优先计算位置(preferred locations)列表,比如HDFS的block的所在位置应该是优先计算的位置
更多Spark分区原理和特性请参考文章:
通过spark.default.parallelism谈Spark谈并行度mp.weixin.qq.com
聊聊Spark的分区mp.weixin.qq.com
重要 | Spark分区并行度决定机制mp.weixin.qq.com
关注 微信公众号:大数据学习与分享,获取更多技术干货






 京公网安备 11010802041100号
京公网安备 11010802041100号