知名的大数据中台技术分享基地,涉及大数据架构(hadoop/spark/flink等),数据平台(数据交换、数据服务、数据治理等)和数据产品(BI、AB测试平台)等,也会分享最新技术进展,大数据相关职位和求职信息,大数据技术交流聚会、讲座以及会议等。
上一篇文章《Impala元数据简介》介绍了Impala缓存的元数据(Metadata/Catalog)的具体内容,本文将介绍这些元数据缓存的生命周期,即它们是怎么初始化的,怎么加载的以及怎么失效的。
以下是常见的元数据相关的问题,基本都跟元数据的生命周期有关:
同样的查询,为什么第一次运行比后面几次运行都要慢很多?
在 Hive 中建了个新表,但在 Impala 中不可见,如何解决?
在 Hive 中建了个新的函数,但在 Impala 中不可见,如何解决?
HUE中使用 Impala Editor 时,为什么有些 View 被显示成了表?
Invalidate metadata 和 Refresh语句有什么区别?各有什么应用场景?
我们在最后再讨论这些问题。另外本文尽量在每一部分给出相应的源码入口(对应版本为 Impala-3.3),感兴趣的读者可以钻研更多细节,文中有不对之处也请大家多多指正。
Impala是一个无状态的系统,元数据都从外部系统获取,启动时Catalog Server、Impalad 和 Statestored 的内存都是空的。启动后还无法提供服务,因为要等Catalog Server从Hive中加载完所有的库名、表名和函数名,通过Statestored传播给所有Coordinator角色的Impalad,然后Impalad才能接收查询。在这之前所有查询都会出现如下报错:
AnalysisException: This Impala daemon is not ready to accept user requests.
Status: Waiting for catalog update from the StateStore.
这个行为在 Impala-2.11 (cdh5.14) 开始做了改动(IMPALA-4704):如果 Impalad 还没准备好接收查询,则不会打开 beeswax (21000) 和 hs2 (21050) 端口,客户端的报错变为连接错误。
Catalog Server 启动时要初始化自己的Catalog对象,主要就是代码里的dbCache_:
Catalog
|-- dbCache_ = Map
|-- functions_ = Map>
|-- tableCache_ = CatalogObjectCache
Catalog Server 首先会从HMS(Hive MetaStore)中拉取所有的库名,为每个数据库建立一个Db对象。
对于每一个数据库,先加载里面的函数(UDF/UDAF)。我们通常把函数建在default数据库下,因此default数据库的函数加载时间一般会比其它数据库长。由于函数的元信息较小,Catalog Server会把它们都加载进来,它们包括:
函数名
各种重载的参数列表
binary文件(jar包或so文件)的hdfs路径
函数在binary文件中对应的符号(symbol)
另外 Catalog Server 还会把binary文件也下载到本地磁盘缓存下来。因此我们在生产环境中要控制binary文件的大小,避免从大的jar包或so文件中创建函数。binary文件下载的路径由启动函数 --local_library_dir 控制,默认是 /tmp。
对于每一个数据库,加载完函数后就是加载表名。Catalog Server直接使用 HMS 的 getAllTables API获取该数据库下所有表名字符串,然后为它们一一建立 IncompleteTable 对象(上一篇文章有介绍),表的元数据都处于未加载的状态。如果启动参数里 --load_catalog_in_background 设的是true(Cloudera Manager里的默认值就是true,但Impala代码里的默认值是false),则还会把这些表名放入后台加载队列中,后台有一个线程池会加载它们的元数据,后面我们再介绍这个线程池。生产环境中表的数目较多,而且还有不少大表,不建议将 --load_catalog_in_background 设置为 true。
Catalog Server启动时元数据加载的具体源码可参见
https://github.com/apache/impala/blob/3.3.0/fe/src/main/java/org/apache/impala/service/JniCatalog.java#L134
https://github.com/apache/impala/blob/3.3.0/fe/src/main/java/org/apache/impala/catalog/CatalogServiceCatalog.java#L1443
https://github.com/apache/impala/blob/3.3.0/fe/src/main/java/org/apache/impala/catalog/CatalogServiceCatalog.java#L1354
1.2 Impalad启动时的元数据加载Impalad 启动时缓存的元数据是空的,此时还不能提供服务。首先要从 statestored 获取一份全量的元数据更新(即跟Catalogd同步),如果此时集群刚启动,则 statestored 里也是空的,需要等 Catalogd 加载完后再更新给 statestored。statestored 是 C++ 写的,内存里缓存的是压缩、序列化后的 Catalog。每一台 Coordinator 角色的 Impalad 启动时,都会从 statestored 获取一份全量的 Catalog,然后才会开始接收查询。
源码可参见:https://github.com/apache/impala/blob/3.3.0/fe/src/main/java/org/apache/impala/service/Frontend.java#L1080
2. 集群运行时的元数据加载Impala里的SQL语句可以简单分为查询语句(Query)、DDL语句和DML语句三种。查询语句指所有返回真实数据的语句,主要指以SELECT为中心的语句。DDL(Data Definition Language)语句主要指元数据操作的各种语句,如 Create Table、Create View、Alter Table、Drop Table这些。DML(Data Manipulation Language)语句主要指数据修改相关的各种语句,如 Insert、Update、Delete等。DML语句可能也会修改元数据,比如 Insert 一个HDFS表时可能会创建新的 Partition。
所有这三种语句都可能触发元数据的加载或刷新(reload),下面我们分异步和同步两类讨论。
2.1 SQL解析触发的异步元数据加载(PrioritizedLoad)对于数据库里的表,集群刚启动时Catalog Server只加载了表名,因此 Impalad 里缓存的也只是这些字符串。当查询来时,Impalad 会对查询进行解析并生成执行计划,这时就需要所查表的完整元数据了。比如展开 "select * " 时需要知道具体的字段名和类型;比如确定函数使用哪个重载时需要知道各参数的类型;再比如join顺序的优化需要知道各表的大小和join字段的基数(Cardinality,即不同值的数目)等统计信息。
缺乏表的必要元数据(不包括统计信息),执行计划就没办法生成。因此 Impalad 会向 Catalogd 发送一个 PrioritizedLoad 的 RPC,传上缺少元数据的表名,让 Catalogd 优先加载它们的元数据。Catalogd 的加载队列里可能有其它任务在排队了,Impalad 请求的加载任务会放在队列前面,优先加载。
Impalad 发送完 PrioritizedLoad 的 RPC 后,Catalogd 返回 ok 只是表示任务放进加载队列里了。Catalogd 加载完后会把元数据的更新发送给 Statestored,从而广播给所有 Coordinator 角色的 Impalad(当然就包括了发起任务的那个)。在没有收到元数据更新之前,查询就一直处于 CREATED 的状态,Last Event 是 "Query submitted",如图所示

Impalad 在完成 PrioritizedLoad PRC 后就开始等待 Statestored 发来的 catalog 更新, 然后再次尝试解析SQL语句。catalog 的更新不一定包含了所缺的所有表(取决于异步加载的执行情况),如果还发现有些表缺元数据,则会再向 Catalogd 发起 PrioritizedLoad RPC。如此循环下去。
最终加载的耗时会体现在Profile里的Query Compilation这段:
Query Compilation: 3s938ms
- Metadata load started: 1.158ms (1.158ms)
- Metadata load finished. loaded-tables=1/4 load-requests=1 catalog-updates=3 storage-load-time=6ms: 3s886ms (3s885ms)
- Analysis finished: 3s920ms (34.379ms)
- Authorization finished (noop): 3s920ms (85.175us)
- Value transfer graph computed: 3s921ms (467.540us)
- Single node plan created: 3s931ms (9.774ms)
- Runtime filters computed: 3s932ms (1.476ms)
- Distributed plan created: 3s932ms (116.092us)
- Planning finished: 3s938ms (6.271ms)
上例中 “Metadata load finished” 一段表示查询触发了元数据加载。其中 "loaded-tables=1/4" 表示查询里涉及4个表,本次加载了1个表(另外3个表在查询编译前已加载过元数据);“load-requests=1” 表示总共向 Catalogd 发送了1次 PrioritizeLoad 请求;"catalog-updates=3" 表示总共等了3轮的catalog广播更新;“storage-load-time=6ms” 表示加载文件元数据花了 6ms。整个元数据加载的等待时间是 3s885ms.
另外,如果某个表刚被执行过 "Invalidate Metadata table_name",或者全局的 "Invalidate Metadata" 刚被执行过,则跟集群刚启动时一样,查询所要的表的元数据也是空的,此时也会触发 PrioritizedLoad RPC 让 catalogd 去加载。等待元数据加载是比较耗时的,因此生产环境中尽量不要在大表上用 "Invalidate Metadata"。
关于 Impalad 发起 PrioritizedLoad 请求的源码可参见:
https://github.com/apache/impala/blob/3.3.0/fe/src/main/java/org/apache/impala/service/Frontend.java#L1278
https://github.com/apache/impala/blob/3.3.0/fe/src/main/java/org/apache/impala/analysis/StmtMetadataLoader.java#L138
2.2 DDL/DML 执行触发的同步元数据加载DDL 或 DML 语句也需要解析,也需要各表的元数据。比如 Create Table A Like B 语句,就需要表B 的具体信息才能执行。这类元数据的获取也是用 PrioritizedLoad,属于上一类。这里要介绍的是 DDL/DML 执行时触发的元数据加载。Catalogd 里维护了一个 Hive 的连接池,所有 DDL 语句和 DML 语句里的 DDL 部分都是在 Catalogd 里执行的。Catalogd 里发生的同步元数据加载主要有两种情况:
如果执行过程中发现某个表的元数据是空的,则会立即对它进行加载。这种情况比较少见,因为 DDL 语句在 Impalad 端解析时,已经加载完表的元数据了。到 Catalogd 端执行时却发现表的元数据是空的,一般是因为有并发的 Invalidate Metadata 在运行,才会出现这种情况。
执行完DDL后经常需要重新加载元数据,比如 Catalogd 调用 Hive 的 AlterTable API 后,会重新加载这个表的元数据。
总之这些元数据的加载请求都是阻塞式的同步加载,它们有的直接执行,有的会跟异步请求一起被调度执行,具体讨论起来比较繁琐,对实战解决问题的帮助不大,所以我们略过。感兴趣的读者可以直接看代码里对 Table#load() 的各处调用:
public abstract class Table extends CatalogObjectImpl implements FeTable {
...
public abstract void load(boolean reuseMetadata, IMetaStoreClient client,
org.apache.hadoop.hive.metastore.api.Table msTbl, String reason)
throws TableLoadingException;
}
源码位置:https://github.com/apache/impala/blob/3.3.0/fe/src/main/java/org/apache/impala/catalog/Table.java#L221
2.3 加载请求在 Catalogd 里的调度回顾一下异步加载请求,主要有两个来源:
每个 Coordinator 角色的 Impalad 都会向 Catalogd 发送 PrioritizedLoad 的异步加载请求,以获取解析查询所需要的元数据。
如果集群启动参数设置了 --load_catalog_in_background=true,Catalogd 启动时也会有一堆异步的加载请求(称为后台请求)。
这些请求在 Catalogd 中统一用一个双端队列(Deque)来维护,后台请求在队列尾部入列,PrioritizedLoad 请求在队列头部入列,入列时都会去重以防重复加载。Catalogd 中有两个线程池,一个用于执行元数据的加载,另一个用于调度元数据加载请求到这个线程池中,并发数都由 num_metadata_loading_threads 参数控制,默认为16。调度请求的线程池(图中的 SubmitterThreads)中的线程不断从队列头部取出请求(Task),并提交到执行元数据加载的线程池(图中的 TableLoadingPool)里去执行。每个调度线程只有在当前的请求加载完后,才会从队列中取出下一个请求,因此每个时刻最多有16个异步请求被提交到 TableLoadingPool 里去执行。
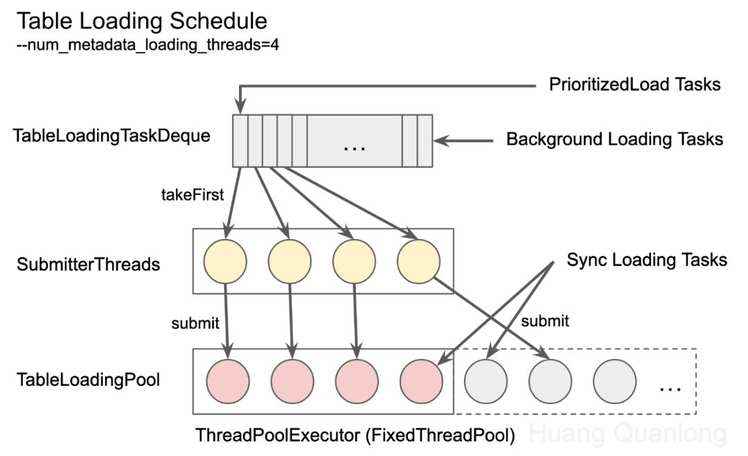
为什么需要两个线程池呢?因为有一些同步加载请求会直接放到执行的线程池里,跳过调度这一步。两个线程池的方式既保证了异步请求不会被饿死(Starvation),也保证了同步请求能尽量早地被执行。具体可参见 IMPALA-9140 里的讨论,其实是有改进空间的,这里不多展开。
值得一提的是,曾经有这么一个bug(IMPALA-4765):某个表的元数据加载时间很长,导致 Impalad 迟迟收不到它的元数据,因此对这个表发送了多轮的 PrioritizedLoad 请求,最终导致整个线程池里的线程都在加载这个表,其它表的元数据就没机会加载了(即出现 Starvation 现象)。此时整个集群的表现就是大量查询处于 CREATED 状态,而且呈持续堆积的态势。这个 bug 在数仓中存在大表时容易触发, Impala-2.9 修复了这个问题(做了更精确的判重),对应的 CDH 版本是 5.12,建议还在使用老版本 CDH 的用户尽量升级。
Catalogd内元数据加载请求的调度源码:
https://github.com/apache/impala/blob/3.3.0/fe/src/main/java/org/apache/impala/catalog/TableLoadingMgr.java
https://github.com/apache/impala/blob/3.3.0/fe/src/main/java/org/apache/impala/catalog/CatalogServiceCatalog.java#L1701
3. 元数据的清除 —— Invalidate MetadataImpala的表级元数据只有两种状态,即加载和未加载。如果已加载,则为具体的实现(HdfsTable、KuduTable、View等):
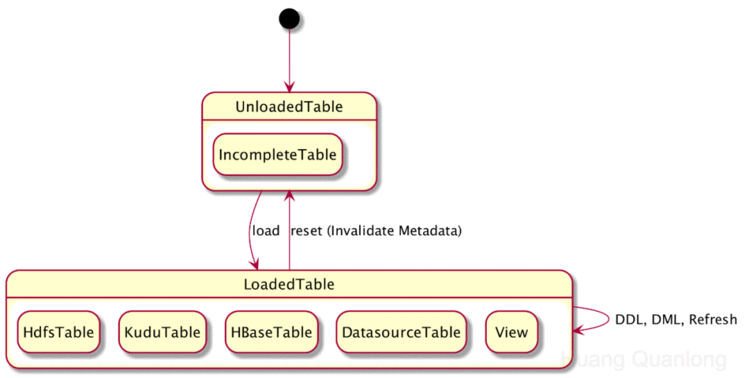
前面已经介绍了元数据从启动时的未加载转为已加载状态的各种机制,正常情况下,元数据已加载的表不会自动回到 IncompleteTable 的状态。如果在 Impala 中对某个表执行了 DDL/DML,Impala会对应地更改元数据缓存,以让其保持最新状态(还是已加载状态)。如果是外部系统(如Hive、Spark)对某个表做了更改,则Impala缓存的变成了过时的元数据,会导致查询失败或查漏数据。Impala 提供了 Invalidate Metadata 和 Refresh 两个语句来解决这种情况,语法如下:
INVALIDATE METADATA [[db_name.]table_name]
REFRESH [db_name.]table_name [PARTITION (key_col1=val1 [, key_col2=val2...])]
INVALIDATE METADATA 直接把元数据重置回未加载状态,从而下次使用时加载的就是最新的元数据。如果未指定表名,则清空的是全体元数据(包括所有db、函数的元数据),相当于重启了Catalog Server。如果指定了表名,则只是把该表的元数据删除,然后在 HMS 中查询该表是否存在,存在则为其生成一个 IncompleteTable 对象。实践中重新加载元数据的做法会让查询延时产生较大的抖动,因此大部分场景推荐增量的更新方式。
REFRESH 语句让 Impala 增量更新指定表的元数据(表名是必须指定的),还可以细化到 partition 级别。REFRESH 语句以 mtime(最近更改时间)为依据对元数据进行增量更新,所有 mtime 未变的 partition 都被认为元数据未改变而跳过更新。
INVALIDATE METADATA 和 REFRESH 语句的实现细节较多(特别是加 sync_ddl=true 的情况),我们在后续文章中会专门讨论。关于 INVALIDATE METADATA 和 REFRESH 语句的细节可参考源码:
https://github.com/apache/impala/blob/3.3.0/fe/src/main/java/org/apache/impala/catalog/CatalogServiceCatalog.java#L1443
https://github.com/apache/impala/blob/3.3.0/fe/src/main/java/org/apache/impala/catalog/CatalogServiceCatalog.java#L1354
https://github.com/apache/impala/blob/3.3.0/fe/src/main/java/org/apache/impala/catalog/CatalogServiceCatalog.java#L2039
https://github.com/apache/impala/blob/3.3.0/fe/src/main/java/org/apache/impala/service/CatalogOpExecutor.java#L3663
4. FAQ下面我们集中讨论一下文章开头列出的问题。
4.1 同样的查询,为什么第一次运行比后面几次运行都要慢很多?第一次运行时表的元数据未加载,Impalad在编译查询时向Catalogd发送PrioritizedLoad请求,等待Catalogd加载需要额外的时间。而第二次第三次再运行查询时,这部分的时间就不需要了,因此会更快。
另外如果表的元数据被 INVALIDATE METADATA 清空,查询的编译也会因为元数据加载而突然变慢。如果遇到全局的(即不加表名的)INVALIDATE METADATA,则集群里所有新提交的查询都会突然变慢。
4.2 在Hive中建了个新表,但在Impala中不可见,如何解决?执行 INVALIDATE METADATA table_name 让 Impala 感知到新表的存在。
类似的,如果在 Hive 中建了个新库,也只有通过 INVALIDATE METADATA db_name.table_name 才能让 Impala 感知到这个新库的存在。由于 INVALIDATE METADATA 目前不支持只指定库名(IMPALA-1763),如果这个数据库里没有任何表,那就只能用不带表名的 INVALIDATE METADATA 了…… 这种场景还是建议直接在 Impala 里建库,或者在 Hive 中再建个表来对它执行 INVALIDATE METADATA table_name。
4.3 在Hive中建了个新的函数,但在Impala中不可见,如何解决?乍一看好像只能用不带表名的 INVALIDATE METADATA,因为没有函数级别的 INVALIDATE METADATA。但其实有个语句专门为这个场景而生:REFRESH FUNCTIONS db_name,用它就可以了。
4.4 HUE 中使用 Impala Editor 时,为什么有些 View 被显示成了表?元数据未加载时,Impala 只知道库名和表名,因此不知道一个表是否是View。因此在返回给HUE的元数据中,凡是元数据未加载的表统一都当作表来返回。解决办法是在 HUE 中执行 DESCRIBE table_name 触发这个表元数据的加载,然后再点击 "Clear Cache" 模式的 Refresh 让HUE重新从Impala获取元数据。
相关源码可参考:
https://github.com/apache/impala/blob/3.3.0/fe/src/main/java/org/apache/impala/service/Frontend.java#L1562
https://github.com/apache/impala/blob/3.3.0/fe/src/main/java/org/apache/impala/service/MetadataOp.java#L515
https://github.com/apache/impala/blob/3.3.0/fe/src/main/java/org/apache/impala/service/MetadataOp.java#L328-L331
4.5 Invalidate metadata 和 Refresh语句有什么区别?各有什么应用场景?Invalidate metadata 用来清空(重置)元数据,执行完后元数据处于未加载状态。Refresh 用来增量更新元数据,执行完后元数据处于已加载状态。
大部分情况我们推荐用 REFRESH 语句来解决元数据过时的问题,只有以下两种情况需要使用 INVALIDATE METADATA:
Hive 中创建的新表在 Impala 中找不到,使用 REFRESH 语句会报错。
HDFS Rebalance 挪动了文件的 block 位置,此时 partition、文件的 mtime 都不变,REFRESH 语句只看 mtime,因此感知不到 block 位置过时了,并不会更新 block 位置。这种情况的后果是查询分片(PlanFragment)会被调度到错误的 Impalad 去执行,导致查询性能变差(Impala以为是本地读,其实变成了远程读)。
5. 总结Impala 通过在 Server 级别缓存元数据来加速查询的编译,不同的查询共用同一份元数据缓存。由于元数据总量很大(相当于HMS+NameNode的元数据),Impala在启动时并没有全部加载,只加载了所有数据库和UDF的元数据以及各表的表名。
表级元数据只有未加载和已加载两种状态,初次使用时 Impalad 会发送 PrioritizedLoad 请求让Catalogd 进行异步加载,Catalogd 中执行的 DDL/DML 也可能发起同步加载的请求。Catalogd 中用线程数为 --num_metadata_loading_threads(默认值为16)的线程池来执行加载请求,调高这个参数能让 Catalogd 同时加载更多的表,但也会增加对 HMS 和 NameNode 的压力。关于 HdfsTable 的元数据加载还有一些相关参数,我们在下一篇文章中再一并介绍。
Catalogd 加载完元数据后通过 Statestored 广播给所有 Coordinator 角色的 Impalad,从而让 Impalad 能继续查询的编译。在这之前 Impalad 对该查询的编译会一直处于等待状态,并按需或定时重发 PrioritizedLoad 请求。
表级元数据只有通过 Invalidate Metadata 才能重置回未加载的状态,但对查询的编译延时有影响,一般情况下建议使用 Refresh。
6. Future Work表级元数据的二元化状态(加载 vs 未加载)带来了很多问题,比如上述 FAQ 中提到的把 View 当成 Table 返回给 HUE 的问题。其实应该引进更细粒度的状态来减少元数据加载引起的等待时间,比如执行 DESCRIBE table_name 时,只需要获取 HMS 中的元数据就够了,不需要再从 NameNode 加载所有文件的元数据。社区在 2018 年发起了 “Fetch-on-demand metadata” 项目(IMPALA-7127,也叫 LocalCatalog 或 catalog-v2,我们在后续文章会专门介绍),目前解决了 Impalad 端元数据粒度的问题,能做到只向 Catalogd 获取查询需要的元数据,也解决了 Impalad 端元数据缓存没有上限的问题。然而 Catalogd 端的元数据问题还没有解决,主要因为 DDL/DML 引入的复杂性,无法照搬 Impalad 端的解决方案,这块目前还在进行当中,可以关注以下 JIRA:
IMPALA-3127 (Decouple partitions from tables): 把元数据的粒度做到 partition 级别(目前是表级别)
IMPALA-8937 (Fine grained table metadata loading on Catalog server): Catalog Server 端细粒度的元数据加载
下一篇文章将介绍表级元数据的加载细节,敬请期待!
作者简介:黄权隆,Cloudera研发工程师,Apache Impala PMC & Comitter,毕业于北大计算机系网络所数据库实验室,曾就职于Hulu大数据基础架构团队,负责大数据系统的维护和二次开发,主要负责Impala和HBase方向。现就职于Cloudera Impala研发团队,主要参与Metadata、Planner、ORC集成、Ranger集成等模块的开发。







 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有