英文分词的算法和原理
根据文档相关性计算公式
分词质量对于基于词频的相关性计算是无比重要的
英文(西方语言)语言的基本单位就是单词,所以分词特别容易做,只需要3步:
根据空格/符号/段落 分隔,得到单词组
过滤,排除掉stop word
提取词干
第一步:按空格/符号分词
用正则表达式很容易
pattern = r'''(?x) # set flag to allow verbose regexps
([A-Z]\.)+ # abbreviations, e.g. U.S.A.
| \w+(-\w+)* # words with optional internal hyphens
| \$?\d+(\.\d+)?%? # currency and percentages, e.g. $12.40, 82%
| \.\.\. # ellipsis
| [][.,;"'?():-_`] # these are separate tokens
'''
re.findall(pattern,待分词文本)
第二步:排除stop word
stopword就是类似a/an/and/are/then 的这类高频词,高频词会对基于词频的算分公式产生极大的干扰,所以需要过滤
第三步:提取词干
词干提取(Stemming) 这是西方语言特有的处理,比如说英文单词有 单数复数的变形,-ing和-ed的变形,但是在计算相关性的时候,应该当做同一个单词。比如 apple和apples,doing和done是同一个词,提取词干的目的就是要合并这些变态
Stemming有3大主流算法
Lucene 英文分词自带了3个stemming算法,分别是
EnglishMinimalStemmer
著名的 Porter Stemming
KStemmer
词干提取算法并不复杂,要么是一堆规则,要么用映射表,编程容易,但是必须是这种语言的专家,了解构词法才行啊
Lemmatisation
Lemmatisation是和词干提取(Stemming) 齐名的一个语言学名词,中文可以叫做 词形还原 ,就是通过查询字典,把 "drove" 还原到 "drive"
而stemming会把单词变短,"apples","apple"处理之后都变成了 "appl"
做计算机语言学研究才会涉及到lemmatization,我个人觉得做搜索完全可以不考虑,Stemming已经可以解决大问题了
参考
搜索相关度算法公式: BM25
BM25算法的全称是 Okapi BM25,是一种二元独立模型的扩展,也可以用来做搜索的相关度排序。
Sphinx的默认相关性算法就是用的BM25。Lucene4.0之后也可以选择使用BM25算法(默认是TF-IDF)。如果你使用的solr,只需要修改schema.xml,加入下面这行就可以
BM25也是基于词频的算分公式,分词对它的算分结果也很重要
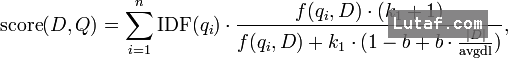
IDF公式
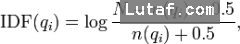
f(qi,D):就是词频
|D|:[给定文档]D长度。
avgdl:索引中所有文档长度。
抽象点看,BM25的公式其实和TF-IDF公式大同小异,可以也可以当做 = ∑ idf(q) * fx(tf),
只不过,BM25的idf和tf都做了一些变形,特别是tf公式,还加入了两个经验参数k1和b,K1和b用来调整精准度,一般情况下我们取K1=2,b=0.75
至于BM25和TF-IDF 哪种相关性算法更更好,我认为依赖于搜索质量评估标准
参考
Lucene TF-IDF 相关性算分公式
Lucene在进行关键词查询的时候,默认用TF-IDF算法来计算关键词和文档的相关性,用这个数据排序
TF:词频,IDF:逆向文档频率,TF-IDF是一种统计方法,或者被称为向量空间模型,名字听起来很复杂,但是它其实只包含了两个简单规则
某个词或短语在一篇文章中出现的次数越多,越相关
整个文档集合中包含某个词的文档数量越少,这个词越重要
所以一个term的TF-IDF相关性等于 TF * IDF
这两个规则非常简单,这就是TF-IDF的核心规则,第二个的规则其实有缺陷的,他单纯地认为文本频率小的单词就越重要,文本频率大的单词就越无 用,显然这并不是完全正确的。并不能有效地反映单词的重要程度和特征词的分布情况,比如说搜索web文档的时候,处于HTML不同结构的特征词中对文章内 容的反映程度不同,应该有不同的权重
TF-IDF的优点是算法简单,运算速度很快
Lucene为了提高可编程行,在上述规则做了一些扩充,就是加入一些编程接口,对不同的查询做了权重归一化处理,但是核心公式还是TF * IDF
Lucene算法公式如下
score(q,d) = coord(q,d) · queryNorm(q) · ∑ ( tf(t in d) · idf(t)2 · t.getBoost() · norm(t,d) )
tf(t in d ), = frequency½
idf(t) = 1 +log(文档总数/(包含t的文档数+1))
coord(q,d) 评分因子,。越多的查询项在一个文档中,说明些文档的匹配程序越高,比如说,查询"A B C",那么同时包含A/B/C3个词的文档 是3分,只包含A/B的文档是2分,coord可以在query中关掉的
queryNorm(q)查询的标准查询,使不同查询之间可以比较
t.getBoost() 和 norm(t,d) 都是提供的可编程接口,可以调整 field/文档/query项 的权重
各种编程插口显得很麻烦,可以不使用,所以我们可以把Lucence的算分公式进行简化
score(q,d) = coord(q,d) · ∑ ( tf(t in d) · idf(t)2 )
结论
TF-IDF 算法是以 term为基础的,term就是最小的分词单元,这说明分词算法对基于统计的ranking无比重要,如果你对中文用单字切分,那么就会损失所有的语义相关性,这个时候 搜索只是当做一种高效的全文匹配方法
按照规则1 某个词或短语在一篇文章中出现的次数越多,越相关 一定要去除掉stop word,因为这些词出现的频率太高了,也就是TF的值很大,会严重干扰算分结果
TF和IDF在生成索引的时候,就会计算出来: TF会和DocID保存在一起(docIDs的一部分),而IDF= 总文档数 / 当前term拥有的docIDs 长度
http://my.oschina.net/bruceray/blog/493317






 京公网安备 11010802041100号
京公网安备 11010802041100号