作者 | 张景俊
编辑 | 丛 末
目前,不管是工业界还是学术界,基于 Transformer 的模型已经广泛应用于自然语言处理(NLP)任务中,然而很多人依然对这些模型的内部工作机制知之甚少。
论文链接:https://arxiv.org/abs/2002.12327
基于此背景,Anna Rogers等人对当前霸占各大NLP任务榜单的 BERT 模型进行了论述,分析了BERT模型工作机理,包括pre-training和fine-turning阶段。并且提出了一些改善BERT模型训练性能的新方法,此外,对未来BERT在NLP任务中的研究方向也进行了探索。
AI 科技评论对这篇文章内容作以简介,抛砖引玉。
1、简 介
自2017年Transformers提出以来,便迅速席卷了整个NLP领域,在众多Transformer-based模型中,毫无疑问最著名的非BERT莫属。本文是一篇综述性文章,概述了目前学术界对BERT已取得的研究成果,并且对后续的研究也进行了展望。
2、BERT 架构
BERT是基于multiple “heads”多头组成的Transformer编码器,它的全连接层采用了self-attention机制,其中每一个头部都用于进行key、value、query的计算。
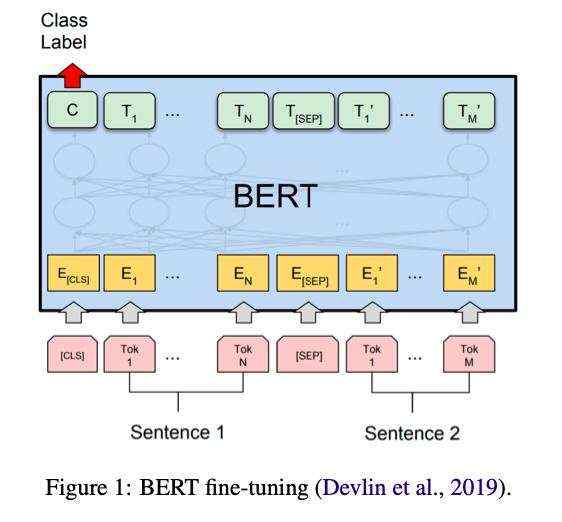
BERT的常规工作流程分为两个阶段:预训练pre-training和微调fine-tuning。其中预训练使用两个半监督任务:MLM模型和NSP模型,对于MLM模型而言,他主要的作用是预测被随机mask的输入token,对于NSP模型而言,他主要的作用是用于,预测两个输入句子是否彼此相邻、是否为前后句关系。相比预训练阶段,微调fine-tuning主要是针对下游应用,在fine-tuning时是通常需要一层或多层全连接层来添加到最终编码器层的顶部,如图1所示:
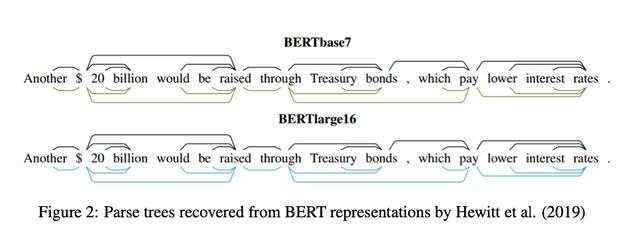
目前,工业界主流的BERT分为基础版和大型版,差异具体体现在模型网络层数的不同、hidden size的大小和不同数量的attention heads。图2给出了Hewitt等人利用BERT进行NLP任务时的解析树。
3、BERT 嵌入
对于BERT embeddings的介绍,作者引述了这方面的相关研究成果进行论述。其中Mikolov和Pennington等人对BERT embeddings与传统的static embeddings之间的区别提出了新的见解,他们认为BERT的embeddings过程是取决于上下文关系的,即每个输入的token都是依赖于特定上下文的向量;而Wiedemann等人于认为BERT的embeddings是通过上下文嵌入与词语聚类来实现的;Mickus等人认为注意力相同单词之间的embedding通过依赖于他们在句子中的位置实现的。
4、BERT学到的是什么知识?
在这一部分,作者主要就目前对BERT中的knowledge进行了阐述,具体包括:句法知识(Syntactic knowledge)、语义知识(Semantic knowledge)和知识库(World knowledge)。对于Syntactic knowledge而言,学术界认为BERT对于格式错误的输入信息其实并不敏感,主要表现在它的预测不因改变单词顺序、句子截断、主语和宾语被删除而受影响。
然而,对于Semantic knowledge的研究学术论文相对较少,但是不乏如Tenney等人的研究,他们主要对BERT编码与语义知识之间的关系进行了研究。对于World knowledge的研究主要是Petroni等人,他们于2019发表了有关vanilla BERT与World knowledge在关系型任务中的工作原理论文。
5、Localizing linguistic knowledge
这一部分,作者主要从两个角度来进行阐述,分别为:Self-attention heads和BERT layers。
1)Self-attention heads
目前,许多学者认为研究注意力对于理解Transformer模型很有帮助,因此针对attention heads学术界进行了大量的研究。2019年,Kovaleva等人对Self-attentionheads的研究表明,Self-attention heads不会直接编码任何普通的语言信息,这是因为它们中有不足一半的是“heterogeneous”模式。同年,Clark等人对[CLS]和[SEP]在注意力机制中的作用进行了相关研究,它们假设用[CLS]和[SEP]来代替句号和逗号,并且让模型学会依赖他们。他们还假定[SEP]的功能就是是“no-op”,通俗的理解就是一旦模式不适用于当前情况,其头部信息是完全可以忽略的。
2)BERT layers
针对BERT的网络结构,作者主要从BERT layers的首层、中间层、最末层三部分进行阐述。对于first layer而言,可以接收由token、segment和positional embeddings三种组合后的输入,所以作者认为他的lower layers具有线性的词序信息。对于BERT的middle layer, Liu等人认为这一层主要用于处理句法信息,通过实验表明,跨任务转移在transform中间层上表现最佳。对于BERT的最末层网络而言,它主要是用于处理具体场景下的任务,这一点在fine-tuning阶段得到了很好地应用。
6、Training BERT
预训练和微调是BERT中的两个重要的任务。在预训练阶段,许多学者针对下一句预测(NSP)和屏蔽语言模型提出了改善BERT性能的一些方法,诸如删除NSP任务、dynamic masking、句子 masking 、实体 masking以及Conditional MLM等等。我们以删除NSP任务为例说明,作者列举了Liu 、Joshi、Clinchant等人的研究成果,研究表明删除NSP任务不但不会损害BERT任务的性能,相反甚至会提升BERT的工作性能,这一情况尤其是在跨语言模型中将NSP替换为预测当前的前后句子表现的更为明显。
对于微调阶段,学术界也进行了多项试验来改善BERT的微调性能,包括 yang等人于2019年提出的加入更多层的网络、Phang等人提出的采用two-stage的方法来提升预训练和微调的中间监督训练等一系列实验探索。
7、How big should BERT be?
当BERT来解决复杂的NLP任务,大家通常都是采用增加模型的复杂度来提升模型的准确度,然而Voita等人通过实验表明,这一做法往往会使得一部分NLP任务因为模型过于复杂反而而造成模型性能的下降。
作者给出了Michel等人在2019年发表论文,阐述了增加BERT模型复杂度对下游任务造成的损害,实践表明通过禁用部分多余的头不但没有造成性能的下降,反而给机器翻译任务带来了性能上的提升,同样的,对于GLUE任务,也有相同的实验结果。至于为什么出现这种情况,Clark等人认为可能是由于在dropout部分attention时,会将训练过程中的注意力权重归零的缘故造成的。
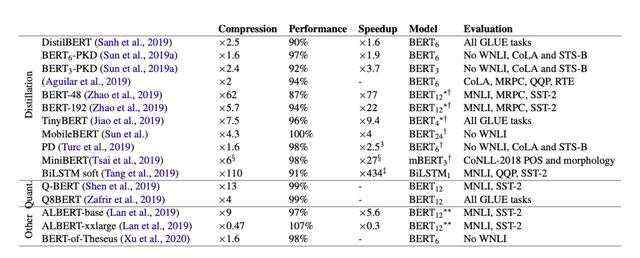
基于此背景,学术界诞生了很多BERT compression的研究,随之作者列举了有关于压缩后的BERT模型性能,并进行了比较,如表1所示。
Table1: Comparison of BERT compression studies
表中的speedup是针对BERTbase而言,各模型中的下标数字代表的是层数,可以发现压缩后的BERT,优点不仅体现在运行速度的提升,而且performance也大幅提升,典型的代表模型如TinyBERT、Albert等。
8、Multilingual BERT
这一部分作者主要对Multilingual BERT模型进行了介绍,其中多语言BERT指的是利用Wikipedia上已有的104种语言,进行了二次抽样或者使用指数平滑进行超级采样后,最终训练好的模型,图7给出了mBERT均值池的语言云图。针对多语言BERT模型,Wu 和 Dredze等人认为它在zero-shot 转移任务中表现极为出色,这是由于该模型通过学习大量的高质量跨语言单词,辅助open-class结构语言,从而极大地提升了模型的质量。当然多语言BERT模型也有很多需要改进的地方,作者罗列了业界主要的改进方法,具体如下:
1、通过freezing 底层的网络来提升多语言数据集的fine-tuning;
2、在fine-tuning任务上改进单词的对齐;
3、通过translation language模型来改善预训练时被屏蔽的目标单词或句子对;
Figure 7:Language centroids of themean-pooled mBERT representations
9、讨论
通过上面的分析介绍,我们会发现,相比其他NLP模型,BERT模型拥有惊人数量的句法、语义以及world knowledge。然而,对于这些惊人数量的句法、语义以及world knowledge,学术界并没有阐述BERT任务中探测分类器是如何根据它们学习以及应用于下游任务的。
除此之外,有关于探针复杂度与检验假设的问题也没有得到合理地解释,这些都需要我们进一步对原模型进行探索。在此背景下,作者给出了未来关于BERT的三个研究方向,分别为:需要推理能力的benchmarks、开发新方法用于“teach” reasoning以及有效的学习推理过程。
10、结论
在短短一年多的时间里,BERT已成为NLP领域众多分析模型的首选,并且很多人也基于BERT进行了各版本的改进,本论文主要是用于阐述目前BERT的研究成果以及工作原理,希望读者能够通读这份文献深入了解BERT,并对以后BERT的研究提出自己的观点与意见。
戳戳,更有料!
【CVPR 2020专题】










 京公网安备 11010802041100号
京公网安备 11010802041100号