编者按:随着交互方式的升级,直播技术成为目前备受关注的领域之一。直播提供了多种用户互动的方式,譬如 实时弹幕、打赏礼物等,这对当下的直播应用来说是必不可少的。云巴 CEO 张虎在本次实践日上,分享了如何实现一个极高并发的直播实时弹幕系统的经验,探讨高并发实时直播弹幕研发的技术难题和解决方案。以下是他演讲的内容。

演讲嘉宾:张虎,云巴创始人。 JPush 创始人,原 CTO,创意并主导开发的系统为过万开发者、过亿终端用户提供了推送服务。Oracle VM 的创始团队成员,早在 2007 年就开始基于 Xen 做开发。
直播间的特点
直播间与聊天室的区别很小,但直播间的人数不像聊天室那样受到限制。传统的聊天室,比如 QQ 群、微信群,一般是 500 人、 1000 人的规模,但直播间需要的却是人越多越好。
人数限制如何形成的?
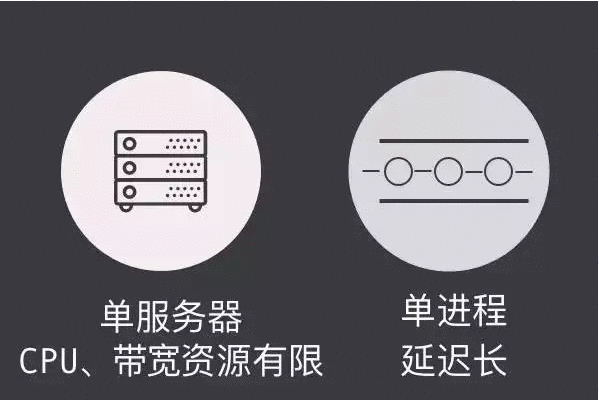
直播间不能限制人数是硬性的业务需求。早期聊天室之所以限制人数并不是因为业务需求,而是技术瓶颈的原因。一个聊天室由单服务器和单进程完成,单服务器意味着 CPU 资源和带宽都是有限的,单进程意味着一次消息群发时, ON 的时间复杂度,即遍历列表越长,遍历时间延迟就会越大。如果做一个实验,就会发现早期 300 人的延迟是最好的,后来服务器更新,硬件质量越来越好,延迟也更低,(所以人数限制)是一个技术限制,就像早期的网络游戏,一个区大概有 200 人在线,这也是一个技术限制。一台物理机在 200 人的时候体验还可以,如果人数过多,体验便会很糟糕。
直播间面临的挑战
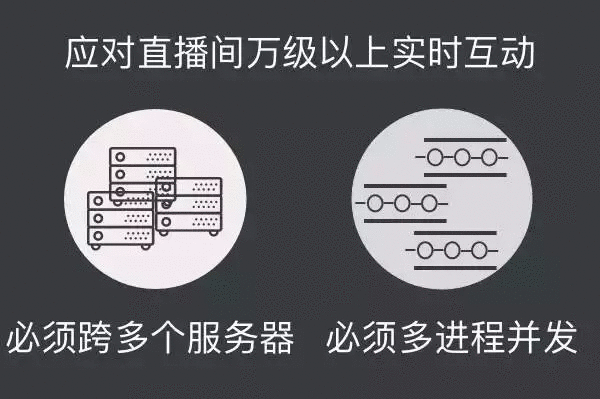
如果要支持万级、几十万级的实时互动是很有挑战的,必须要跨服务器、多进程并发。如果在这种高并发的情况下,仍然使用单进程的做法,那么最后一个收到消息和第一个收到消息的时间跨度非常大,跨服务器主要解决单一服务器接入数量限制的问题,如果一个直播间不能跨多个服务器,用户在线数量就会受到物理上的限制和单一服务器的吞吐限制。带宽是有限制的,CPU 是有限制的,不可能无限的放大。众所周知 CPU 的主屏基本都是上限的,在现阶段如果想做的话,必须要突破这两个限制(单一服务器接入数量限制和单一服务器发布消息吞吐限制),第一需要跨服务器,第二减少循环的规模,降低延迟,使用多任务或多进程。聊天室或直播间的人数是可以切片处理的,假设它里面有 4 万人,可能 1 分片 500 人,这样就能降低规模,即每一个进程需要面临的规模其实只有 500 ,当然进程数比较多,也需要管理多进程的任务。
云巴实时系统的设计
从两个角度来介绍云巴的系统设计:多层结构和微服务化。它们具有一定的关连性,多层结构意味着一定要有服务化。
多层结构是指一个基本的业务逻辑的完成,需要经过很多模块。例如接入云巴的系统,接入服务器(也可称为前端服务器)接进来,它并不处理业务逻辑,它仅仅是对接入的请求进行验证,确认是否有权限、SL 密钥是否正确、编解码以及确认请求的内容。再通过一个内部的消息队列进行部署。如下图所示,这个消息队列是一个集群,每个机房都有一个自己的集群,所以接入服务器其实是很多集群,它可以跨多个机房去部署,通过内部的消息队列把消息转入主逻辑。例如它发现一个登陆的请求,主逻辑会去确认登陆时需要做什么,其中一个重要的事情是修改路由表。假设有一个客户端,它从北京或者广州的机房接进来,主逻辑发现已登陆成功,它便会修改全局路由表,其他的逻辑就可以通过这个全局路由表看到这件事。再举例,如果做一个订阅动作,需要从接入端发一个订阅请求,通过 MQ 转到主逻辑,主逻辑会修改订阅关系,且这个订阅关系也是一个独立的全局都可以访问的服务。
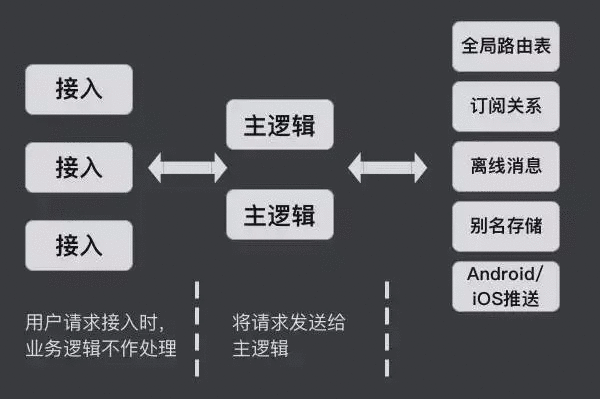
发消息的时候也会涉及几个方面,例如在一个直播间发一个消息,推送端要知道这个直播间有哪些人在线,才能把消息有效的分发出去,如果想知道在线的人在什么位置,就需要读全局路由表和订阅关系。另一个方面,离线消息的保存。例如每个人都希望能收到主播更新的消息,但某些人可能因为不在线而无法收到消息,这时就会需要离线消息。如果某个主播的关注量很大,有近几十万的粉丝,这种情况下存一个离线消息的延迟会很大。云巴做了一个设计——别名的存储,这是为了帮助客户的帐号系统和云巴的帐号系统做一个预设,每个客户或者主播都有自己的 UID ,显然大家不愿意分享自己的 UID,云巴可以通过别名把客户的 UID 跟自己内部的 UID 做绑定,并且支持安卓和 iOS 的推送。
多层结构的特点
多层结构有优点与缺点,其中最主要的优点,即每一个模块都可以独立运行,例如接入、主逻辑或者里面任意一个逻辑、节点,多层结构都可以独立运行。编好之后运行,不需要依赖于任何其他的模块,有输入就可以得到输出。在这样的情况下,不管是开发、测试、部署还是后期的运维,都可以极大地提高效率。例如定位一个问题时,只需要看每一个模块的输入和输出,通过输入检查输出是否按照预期的行为输出,定位问题后找出问题最上游的模块进行解决。如果该模块的问题被解决后逻辑仍有问题,就看它下游的模块。云巴给所有模块定义了一个在线监控的点(称为环回测试),即定期通过每个模块接受的输入检查输出是否正确,且还回测试是在线的(生产状态中的)。如果环回测试报警了,则意味着那个模块的生产业务逻辑出问题了。
第二个优点,开发可以很容易地做持续集成。例如发一个新版本,模拟测试环境跟直接生产还是有差距的。这时候可以挑一台机房,在机房加一台服务器,把免费用户 1% 的流量导上去,观察该模块一周内是否可以正常运作,这是很有说服力的测试。针对这个云巴很容易做到,因为云巴的每个逻辑基本都是切开的,加一个点的时候它其实只有一个模块,即这 1% 的流量从新加的节点上去,所以它对开发也会有很大的帮助。举个具体的例子,早期的时候这个结构里很多都是用 Node.js 写的,后来发现它更适合用来做网站。最早云巴是从主逻辑开始做迭代,把主逻辑换成 Erlang ,但团队的人都是第一次用 Erlang ,当时很担心上线有问题,所以采取了上述方法。刚开始导几十分之一的流量上去,一周后发现运作情况不错,就慢慢的增加,直到最后所有的模块全部被替换。另外,上线的时间一般选在上午,因为夜晚人容易困倦,如果出问题了做及时调整的效率会很低。
第三个优点,细粒度扩容。可以对接入扩容,加一台服务器,再导一些流量过去,这就完成了扩容。如果发现服务器有问题,把流量撤走即可。
第四个优点,隔离问题。如果想要有效的跟踪定位到客户报的问题,可以强制它(用户)从某一条有三至五台服务器的路径走,在跟用户相关的信息上设置一些钩子,这样可以从这三至五台服务器里收集信息,从而能够看到关键性的用户,甚至可以做性能的测量。所谓的隔离是指,可以指定哪些用户从哪些路径走,或者是哪些路径出问题之后,可以把哪些路径摘除掉。发现问题最重要的不是解决问题,而是隔离问题,因为解决问题的周期是很难控制的。云巴作为一个线上系统,客户等待的时间不能太长,如果发现有介入或者问题,第一步并不是思考如何解决问题,而是先确认线上是否有闲置的服务器,把客户切入到闲置的服务器,再检查原来的点出了什么问题,这样可以很好的控制处理问题的时间周期。
微服务化
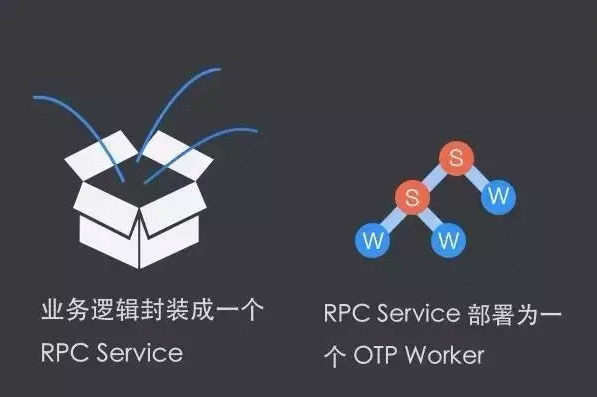
其实微服务是一个比较老的概念,观察 OTP 的框架,它的诞生就是为了做微服务。S(Superviser)代指监控者,W(Worker)指工作进程,在 OTP 里是一个海量进程组成的进程数,一个应用就是一整个进程树,S 即该进程树的根。S 下面还继续监控 S 和 W。按照上图的设计,下面的 S 和 W 数量是可以无限大的。所以 OTP 里用了海量的微服务,任何一个应用的逻辑均做成这样,具体的业务均由 W 完成,这个 W 是一个 RPC Service 。 举例说明,写一个很简单的逻辑,收到请求后查询 Redis,再返回结果。
用这个设计是如何完成的?首先暴露一个 RESTful API 接口,外面发一个请求给 W,假设这个 W 连接了 Redis,再转 Redis 的请求给 W ,该 W 再去真正的访问 Redis,再返回把结果转发给 W,最后把结果给客户端。云巴会把 HTTP 相关的、 Redis 相关的 分别做成一个独立的树,里面可能有 50 多个 W,可以用来做负载均衡和高可用,如果出现了任何问题,都可以直接撤掉之前的 W 再重建。所以在 OTP 的微服务框架里,业务逻辑很简单,并且可以做到很大的并发量,即业务逻辑封装成一个 RPC service ,RPC service 部署为一个 OTP Worker。
轻量级任务
长连接的维持其实很简单,把任何一个存在于系统里的连接定义为一个轻量级的任务,由这个任务维持连接的心跳、观察它的动作或管理它的登陆和消息。任何一个用户发给系统的请求,均由一个任务来处理。假设用户需要加入一个直播间,这个动作就可以用一个任务来处理,用户发了一个加入直播间的请求,它就会去检查是否有权限,最后会返回一个结果检查用户的动作是否成功,这里会涉及到很多模块的操作,并且它是一个极大并发。直播平台业务量的增加是很难控制的,云巴的方法是确认目前的硬件资源是否能支撑现有的业务需求。如果不能支撑,可以通过增加硬件资源来扩大池子(例如处理订阅频道和发布消息的池子),这样做的情况下,不需要知道每一个具体的任务是什么,只要确认任务池跟硬件资源的水位线差距是多少。如果水位线超过 80%,可以增加硬件资源扩大池子,在下一次的调度时,即可找到闲置的资源来处理任务。
任务与运行位置无关
根据上述场景加一台硬件后,就可以调度新任务,它的表象是可以动态地把任务接入到不同的物理机,具有能够随时扩容系统里任何一个点的优势。因为不同的模块承受的压力不同,大部分的直播应用最大的压力来源于发布消息。如果想做到任务运行跟位置无关,那么所有的数据都需要独立存储,即存在一个独立的集群,有一个单一的路口,即使将来扩展到 50 台机器,还是可以使用同样的方式访问。任务运行时,数据相当于从第三方里读出来,不会在扩容里会出来。
海量消息发布过程
举例说明,一个几万级量级的过程要达到实时,需要做很多预备性的处理,例如在订阅关系和路由的数据上分片,或者是一个直播间里有 4 万人,想一次性读出 4 万个 UID ,它的延迟很明显,如果数量更多延迟就会更明显,所以并不能仅用一个包就把它读出来。正如上述所说,每一个 UID 都有一个自己接入点的路由信息,是一个比较长的数据,想做到一次性读出来,一定要做分片。修改这些数据时需要也准备好分片,下一步再进行切分任务发布执行。
如果用户列表里有 4 万个 UID,一定要把它切开,现在的做法是每片切到 200 个 UID,这意味着需要用更多的任务来处理一次发布,总体消耗比较大,因为任务的创建本身是有消耗的。这时需要找一个平衡点,因为每个分片足够小时,最大延迟也会足够小,但如果分片太小了,又会面临任务规模变大的问题。
发布过程
一般过程(一)
所谓的一般过程,实际上是一个很典型的聊天室的做法,遍历列表里的每一个 UID,读取路由,逐一发消息。
一般过程(二)
这个过程用了很多接入服务器,但没有做路由器的管理。它不管直播间的用户是从哪里接过来的,仅仅简单地给每个服务器发命令,每个服务器再进行判断 UID 是否加入直播间(是否订阅频道),它需要每台接入服务器管理订阅关系。但这里存在一个同步的问题。
云巴的消息发布
类似于 Map/Reduce ,这里有三个重要的点,第一个是任务可以切分。第二个是不论任务的数据被分发到哪一个处理节点上,数据都是没有问题的。另外,任务逻辑的运行跟位置没有相关性。第三个是需要有一个发布任务,汇聚所有分发出去的反馈结果,再返回给客户端。
这个发布过程的再大优点,是有效控制最大延迟。假设直播间里有 4 万人,以用户收到的最后一个消息为准来评估延迟的时长,所有程序的调优参数均以此作为指标,即延迟控制在 200 ms 以内。第二个优点,平行扩展。极大并发量时,简单地往里面加服务器即可,一样可以将延迟控制在 200 ms 以内。如果要控制发布过程的延迟,加入的服务器需要专门用来处理发布消息,这样就可以控制住最大的延迟。





 京公网安备 11010802041100号
京公网安备 11010802041100号