单机版安装
下载zk
https://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/stable
jar包名为:zookeeper-3.4.10.tar
在master上创建一个~/bigdata/zookeeper的目录
注意:安装的所有大数据软件都不能用root创建,否则会出现一大堆权限问题,哪怕你修改了权限都还是会有问题,解决方案:删除重装
将上面下载的zk上传至这个目录下(用filezilla工具)
分别在zookeeper 下创建目录data和log,并解压zk的jar包
mkdir ~/bigdata/zookeeper
mkdir ~/bigdata/zookeeper/data
mkdir ~/bigdata/zookeeper/log
cd ~/bigdata/zookeeper
tar -xf zookeeper-3.4.10.tar
进入到zk中的conf目录,配置zoo.cfg文件,如下:
cd ~/bigdata/zookeeper/zookeeper-3.4.10/conf
cp zoo_sample.cfg zoo.cfg
vi zoo.cfg 填写如下配置:
dataDir=/home/hadoop-jrq/bigdata/zookeeper/data
dataLogDir=/home/hadoop-jrq/bigdata/zookeeper/log
在master中配置环境变量
vi ~/.bash_profile
export ZK_HOME=/home/hadoop-jrq/bigdata/zookeeper/zookeeper-3.4.10
PATH=$PATH:$HOME/.local/bin:$HOME/bin:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$ZK_HOME/bin
source .bash_profile
zkServer.sh start 启动zk
jps验证

使用脚本命令zkCli.sh操作Zookeeper
连接zk:zkCli.sh -server master:2181
ls => 查看根节点
create app1 "" => 创建一个节点 创建节点时必须更上数据,否则创建不成功
get app1 => 获取节点/app1的数据值
set app1 "数据内容" => 给节点/app1设置值
get app1 => 获取节点/app1的数据值
create app1/p_1 “p_1_config” => 创建一个节点 注意这样创建app1不存在会报错
delete /app2/p_2 => 删除节点/app2/p_2
quit => 退出zkCli
使用ZooInspector查看Zookeeper
下载:https://issues.apache.org/jira/secure/attachment/12436620/ZooInspector.zi
解压后进入build目录 启动cmd 输入: java -jar zookeeper-dev-ZooInspector.jar
过于简单不在介绍怎么使用
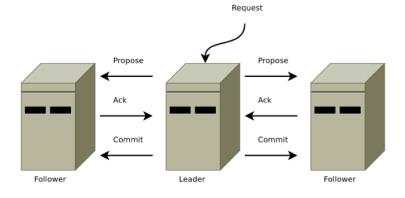
Data Model - ZNode


安装分布式Zookeeper
进入到zk中的conf目录,配置zoo.cfg文件,如下
vi zoo.cfg 填写如下配置:
server.0=master:8880:7770
server.1=slave1:8881:7771
server.2=slave2:8882:7772
将master上的zookeeper文件夹scp到slave1和slave2中
scp -r ~/bigdata/zookeeper/ hadoop-jrq@slave1:~/bigdata/
scp -r ~/bigdata/zookeeper/ hadoop-jrq@slave2:~/bigdata/
分别在3台服务器中的~/bigdata/zookeeper/data中新增文件myid
cd ~/bigdata/zookeeper/data 然后vi myid;内容如下:
master上的内容为0
slave1上的内容为1
slave2上的内容为2
注意myid的内容和上面的zoo.cfg server.值的值一致
关闭master上面的zk服务, zkServer.sh stop
在slave1,slave2配置环境变量 和单机版同理
分别到3台服务器中启动节点zk服务
查看每一个服务器上的zk的状态
zkServer.sh status
状态过于简单,不在解释










 京公网安备 11010802041100号
京公网安备 11010802041100号